

Keras 学习之旅(一)
3 keras 学习小结
引自:http://blog.csdn.net/sinat_26917383/article/details/72857454
3.1 keras网络结构

3.2 keras网络配置

其中回调函数 callbacks 是keras
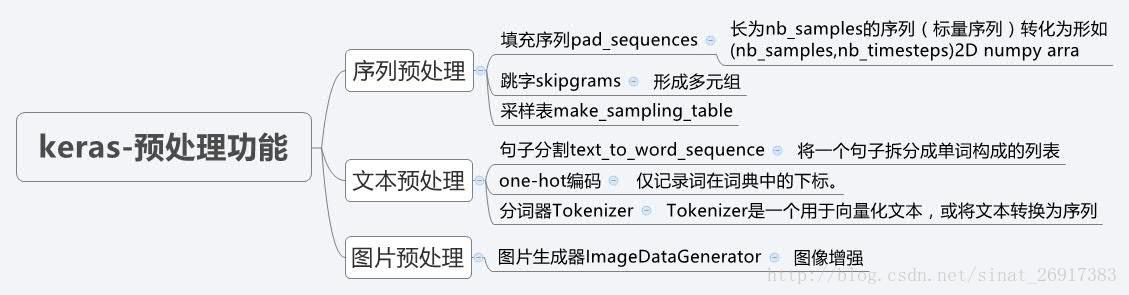
3.3 keras预处理功能
3.4 模型的节点信息提取
对于序列模型
%%time
import keras
from keras.models import Sequential
from keras.layers import Dense
import numpy as np
# 实现 Lenet
import keras
from keras.datasets import mnist
(x_train, y_train), (x_test,y_test) = mnist.load_data()
x_train=x_train.reshape(-1, 28,28,1)
x_test=x_test.reshape(-1, 28,28,1)
x_train=x_train/255.
x_test=x_test/255.
y_train=keras.utils.to_categorical(y_train)
y_test=keras.utils.to_categorical(y_test)
from keras.layers import Conv2D, MaxPool2D, Dense, Flatten
from keras.models import Sequential
lenet=Sequential()
lenet.add(Conv2D(6, kernel_size=3,strides=1, padding='same', input_shape=(28, 28, 1)))
lenet.add(MaxPool2D(pool_size=2,strides=2))
lenet.add(Conv2D(16, kernel_size=5, strides=1, padding='valid'))
lenet.add(MaxPool2D(pool_size=2, strides=2))
lenet.add(Flatten())
lenet.add(Dense(120))
lenet.add(Dense(84))
lenet.add(Dense(10, activation='softmax'))
lenet.compile('sgd',loss='categorical_crossentropy',metrics=['accuracy']) # 编译模型
lenet.fit(x_train,y_train,batch_size=64,epochs= 20,validation_data=[x_test,y_test], verbose= 0) # 训练模型
lenet.save('E:/Graphs/Models/myletnet.h5') # 保存模型
Wall time: 2min 48s
# 节点信息提取
config = lenet.get_config() # 把 lenet 模型中的信息提取出来
config[0]
{'class_name': 'Conv2D',
'config': {'activation': 'linear',
'activity_regularizer': None,
'batch_input_shape': (None, 28, 28, 1),
'bias_constraint': None,
'bias_initializer': {'class_name': 'Zeros', 'config': {}},
'bias_regularizer': None,
'data_format': 'channels_last',
'dilation_rate': (1, 1),
'dtype': 'float32',
'filters': 6,
'kernel_constraint': None,
'kernel_initializer': {'class_name': 'VarianceScaling',
'config': {'distribution': 'uniform',
'mode': 'fan_avg',
'scale': 1.0,
'seed': None}},
'kernel_regularizer': None,
'kernel_size': (3, 3),
'name': 'conv2d_7',
'padding': 'same',
'strides': (1, 1),
'trainable': True,
'use_bias': True}}
model = Sequential.from_config(config) # 将提取的信息传给新的模型, 重构一个新的 Model 模型,fine-tuning 比较好用
3.5 模型概况查询、保存及载入
1、模型概括打印
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_7 (Conv2D) (None, 28, 28, 6) 60
_________________________________________________________________
max_pooling2d_7 (MaxPooling2 (None, 14, 14, 6) 0
_________________________________________________________________
conv2d_8 (Conv2D) (None, 10, 10, 16) 2416
_________________________________________________________________
max_pooling2d_8 (MaxPooling2 (None, 5, 5, 16) 0
_________________________________________________________________
flatten_4 (Flatten) (None, 400) 0
_________________________________________________________________
dense_34 (Dense) (None, 120) 48120
_________________________________________________________________
dense_35 (Dense) (None, 84) 10164
_________________________________________________________________
dense_36 (Dense) (None, 10) 850
=================================================================
Total params: 61,610
Trainable params: 61,610
Non-trainable params: 0
_________________________________________________________________
2、权重获取
model.get_layer('conv2d_7' ) # 依据层名或下标获得层对象
<keras.layers.convolutional.Conv2D at 0x1ed425bce10>
weights = model.get_weights() #返回模型权重张量的列表,类型为 numpy array
model.set_weights(weights) #从 numpy array 里将权重载入给模型,要求数组具有与 model.get_weights() 相同的形状。
# 查看 model 中 Layer 的信息
model.layers
[<keras.layers.convolutional.Conv2D at 0x1ed425bce10>,
<keras.layers.pooling.MaxPooling2D at 0x1ed4267a4a8>,
<keras.layers.convolutional.Conv2D at 0x1ed4267a898>,
<keras.layers.pooling.MaxPooling2D at 0x1ed4266bb00>,
<keras.layers.core.Flatten at 0x1ed4267ebe0>,
<keras.layers.core.Dense at 0x1ed426774a8>,
<keras.layers.core.Dense at 0x1ed42684940>,
<keras.layers.core.Dense at 0x1ed4268edd8>]
3.6 模型保存与加载
引用:keras如何保存模型
-
使用
model.save(filepath)将 Keras 模型和权重保存在一个 HDF5 文件中,该文件将包含:- 模型的结构(以便重构该模型)
- 模型的权重
- 训练配置(损失函数,优化器等)
- 优化器的状态(以便于从上次训练中断的地方开始)
-
使用
keras.models.load_model(filepath)来重新实例化你的模型,如果文件中存储了训练配置的话,该函数还会同时完成模型的编译
# 将模型权重保存到指定路径,文件类型是HDF5(后缀是.h5)
filepath = 'E:/Graphs/Models/lenet.h5'
model.save_weights(filepath)
# 从 HDF5 文件中加载权重到当前模型中, 默认情况下模型的结构将保持不变。
# 如果想将权重载入不同的模型(有些层相同)中,则设置 by_name=True,只有名字匹配的层才会载入权重
model.load_weights(filepath, by_name=False)
json_string = model.to_json() # 等价于 json_string = model.get_config()
open('E:/Graphs/Models/lenet.json','w').write(json_string)
model.save_weights('E:/Graphs/Models/lenet_weights.h5')
#加载模型数据和weights
model = model_from_json(open('E:/Graphs/Models/lenet.json').read())
model.load_weights('E:/Graphs/Models/lenet_weights.h5')
3.6.1 只保存模型结构,而不包含其权重或配置信息
- 保存成
json格式的文件
# save as JSON
json_string = model.to_json()
open('E:/Graphs/Models/my_model_architecture.json','w').write(json_string)
from keras.models import model_from_json
model = model_from_json(open('E:/Graphs/Models/my_model_architecture.json').read())
- 保存成
yaml文件
# save as YAML
yaml_string = model.to_yaml()
open('E:/Graphs/Models/my_model_architectrue.yaml','w').write(yaml_string)
from keras.models import model_from_yaml
model = model_from_yaml(open('E:/Graphs/Models/my_model_architectrue.yaml').read())
这些操作将把模型序列化为json或yaml文件,这些文件对人而言也是友好的,如果需要的话你甚至可以手动打开这些文件并进行编辑。当然,你也可以从保存好的json文件或yaml文件中载入模型
3.6.2 实时保存模型结构、训练出来的权重、及优化器状态并调用
keras 的 callback 参数可以帮助我们实现在训练过程中的适当时机被调用。实现实时保存训练模型以及训练参数
keras.callbacks.ModelCheckpoint(
filepath,
monitor='val_loss',
verbose=0,
save_best_only=False,
save_weights_only=False,
mode='auto',
period=1
)
filename:字符串,保存模型的路径monitor:需要监视的值- verbose:信息展示模式,
0或1 - save_best_only:当设置为True时,将只保存在验证集上性能最好的模型
- mode:‘auto’,‘min’,‘max’之一,在save_best_only=True时决定性能最佳模型的评判准则,例如,当监测值为val_acc时,模式应为max,当检测值为val_loss时,模式应为min。在auto模式下,评价准则由被监测值的名字自动推断。
- save_weights_only:若设置为True,则只保存模型权重,否则将保存整个模型(包括模型结构,配置信息等)
- period:CheckPoint之间的间隔的epoch数
3.6.3 示例
假如原模型为:
x=np.array([[0,1,0],[0,0,1],[1,3,2],[3,2,1]])
y=np.array([0,0,1,1]).T
model=Sequential()
model.add(Dense(5,input_shape=(x.shape[1],),activation='relu', name='layer1'))
model.add(Dense(4,activation='relu',name='layer2'))
model.add(Dense(1,activation='sigmoid',name='layer3'))
model.compile(optimizer='sgd',loss='mean_squared_error')
model.fit(x,y,epochs=200, verbose= 0) # 训练
model.save_weights('E:/Graphs/Models/my_weights.h5')
model.predict(x[0:1]) # 预测
array([[ 0.38783705]], dtype=float32)
# 新模型
model = Sequential()
model.add(Dense(2, input_dim=3, name="layer_1")) # will be loaded
model.add(Dense(10, name="new_dense")) # will not be loaded
# load weights from first model; will only affect the first layer, dense_1.
model.load_weights('E:/Graphs/Models/my_weights.h5', by_name=True)
model.predict(x[1:2])
array([[-0.27631092, -0.35040742, -0.2807056 , -0.22762418, -0.31791407,
-0.0897391 , 0.02615392, -0.15040982, 0.19909057, -0.38647971]], dtype=float32)
3.7 How to Check-Point Deep Learning Models in Keras
# Checkpoint the weights when validation accuracy improves
from keras.models import Sequential
from keras.layers import Dense
from keras.callbacks import ModelCheckpoint
import matplotlib.pyplot as plt
import numpy as np
x=np.array([[0,1,0],[0,0,1],[1,3,2],[3,2,1]])
y=np.array([0,0,1,1]).T
model=Sequential()
model.add(Dense(5,input_shape=(x.shape[1],),activation='relu', name='layer1'))
model.add(Dense(4,activation='relu',name='layer2'))
model.add(Dense(1,activation='sigmoid',name='layer3'))
# Compile model
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
filepath="E:/Graphs/Models/weights-improvement-{epoch:02d}-{val_acc:.2f}.hdf5"
checkpoint = ModelCheckpoint(filepath, monitor='val_acc', verbose=1, save_best_only=True, mode='max')
callbacks_list = [checkpoint]
# Fit the model
model.fit(x, y, validation_split=0.33, epochs=150, batch_size=10, callbacks=callbacks_list, verbose=0)
Epoch 00000: val_acc improved from -inf to 1.00000, saving model to E:/Graphs/Models/weights-improvement-00-1.00.hdf5
Epoch 00001: val_acc did not improve
Epoch 00002: val_acc did not improve
Epoch 00003: val_acc did not improve
Epoch 00004: val_acc did not improve
Epoch 00005: val_acc did not improve
Epoch 00006: val_acc did not improve
Epoch 00007: val_acc did not improve
Epoch 00008: val_acc did not improve
Epoch 00009: val_acc did not improve
Epoch 00010: val_acc did not improve
Epoch 00011: val_acc did not improve
Epoch 00012: val_acc did not improve
Epoch 00013: val_acc did not improve
Epoch 00014: val_acc did not improve
Epoch 00015: val_acc did not improve
Epoch 00016: val_acc did not improve
Epoch 00017: val_acc did not improve
Epoch 00018: val_acc did not improve
Epoch 00019: val_acc did not improve
Epoch 00020: val_acc did not improve
Epoch 00021: val_acc did not improve
Epoch 00022: val_acc did not improve
Epoch 00023: val_acc did not improve
Epoch 00024: val_acc did not improve
Epoch 00025: val_acc did not improve
Epoch 00026: val_acc did not improve
Epoch 00027: val_acc did not improve
Epoch 00028: val_acc did not improve
Epoch 00029: val_acc did not improve
Epoch 00030: val_acc did not improve
Epoch 00031: val_acc did not improve
Epoch 00032: val_acc did not improve
Epoch 00033: val_acc did not improve
Epoch 00034: val_acc did not improve
Epoch 00035: val_acc did not improve
Epoch 00036: val_acc did not improve
Epoch 00037: val_acc did not improve
Epoch 00038: val_acc did not improve
Epoch 00039: val_acc did not improve
Epoch 00040: val_acc did not improve
Epoch 00041: val_acc did not improve
Epoch 00042: val_acc did not improve
Epoch 00043: val_acc did not improve
Epoch 00044: val_acc did not improve
Epoch 00045: val_acc did not improve
Epoch 00046: val_acc did not improve
Epoch 00047: val_acc did not improve
Epoch 00048: val_acc did not improve
Epoch 00049: val_acc did not improve
Epoch 00050: val_acc did not improve
Epoch 00051: val_acc did not improve
Epoch 00052: val_acc did not improve
Epoch 00053: val_acc did not improve
Epoch 00054: val_acc did not improve
Epoch 00055: val_acc did not improve
Epoch 00056: val_acc did not improve
Epoch 00057: val_acc did not improve
Epoch 00058: val_acc did not improve
Epoch 00059: val_acc did not improve
Epoch 00060: val_acc did not improve
Epoch 00061: val_acc did not improve
Epoch 00062: val_acc did not improve
Epoch 00063: val_acc did not improve
Epoch 00064: val_acc did not improve
Epoch 00065: val_acc did not improve
Epoch 00066: val_acc did not improve
Epoch 00067: val_acc did not improve
Epoch 00068: val_acc did not improve
Epoch 00069: val_acc did not improve
Epoch 00070: val_acc did not improve
Epoch 00071: val_acc did not improve
Epoch 00072: val_acc did not improve
Epoch 00073: val_acc did not improve
Epoch 00074: val_acc did not improve
Epoch 00075: val_acc did not improve
Epoch 00076: val_acc did not improve
Epoch 00077: val_acc did not improve
Epoch 00078: val_acc did not improve
Epoch 00079: val_acc did not improve
Epoch 00080: val_acc did not improve
Epoch 00081: val_acc did not improve
Epoch 00082: val_acc did not improve
Epoch 00083: val_acc did not improve
Epoch 00084: val_acc did not improve
Epoch 00085: val_acc did not improve
Epoch 00086: val_acc did not improve
Epoch 00087: val_acc did not improve
Epoch 00088: val_acc did not improve
Epoch 00089: val_acc did not improve
Epoch 00090: val_acc did not improve
Epoch 00091: val_acc did not improve
Epoch 00092: val_acc did not improve
Epoch 00093: val_acc did not improve
Epoch 00094: val_acc did not improve
Epoch 00095: val_acc did not improve
Epoch 00096: val_acc did not improve
Epoch 00097: val_acc did not improve
Epoch 00098: val_acc did not improve
Epoch 00099: val_acc did not improve
Epoch 00100: val_acc did not improve
Epoch 00101: val_acc did not improve
Epoch 00102: val_acc did not improve
Epoch 00103: val_acc did not improve
Epoch 00104: val_acc did not improve
Epoch 00105: val_acc did not improve
Epoch 00106: val_acc did not improve
Epoch 00107: val_acc did not improve
Epoch 00108: val_acc did not improve
Epoch 00109: val_acc did not improve
Epoch 00110: val_acc did not improve
Epoch 00111: val_acc did not improve
Epoch 00112: val_acc did not improve
Epoch 00113: val_acc did not improve
Epoch 00114: val_acc did not improve
Epoch 00115: val_acc did not improve
Epoch 00116: val_acc did not improve
Epoch 00117: val_acc did not improve
Epoch 00118: val_acc did not improve
Epoch 00119: val_acc did not improve
Epoch 00120: val_acc did not improve
Epoch 00121: val_acc did not improve
Epoch 00122: val_acc did not improve
Epoch 00123: val_acc did not improve
Epoch 00124: val_acc did not improve
Epoch 00125: val_acc did not improve
Epoch 00126: val_acc did not improve
Epoch 00127: val_acc did not improve
Epoch 00128: val_acc did not improve
Epoch 00129: val_acc did not improve
Epoch 00130: val_acc did not improve
Epoch 00131: val_acc did not improve
Epoch 00132: val_acc did not improve
Epoch 00133: val_acc did not improve
Epoch 00134: val_acc did not improve
Epoch 00135: val_acc did not improve
Epoch 00136: val_acc did not improve
Epoch 00137: val_acc did not improve
Epoch 00138: val_acc did not improve
Epoch 00139: val_acc did not improve
Epoch 00140: val_acc did not improve
Epoch 00141: val_acc did not improve
Epoch 00142: val_acc did not improve
Epoch 00143: val_acc did not improve
Epoch 00144: val_acc did not improve
Epoch 00145: val_acc did not improve
Epoch 00146: val_acc did not improve
Epoch 00147: val_acc did not improve
Epoch 00148: val_acc did not improve
Epoch 00149: val_acc did not improve
<keras.callbacks.History at 0x1ed46f00ac8>
3.8 Checkpoint Best Neural Network Model Only
# Checkpoint the weights for best model on validation accuracy
import keras
from keras.layers import Input, Dense
from keras.models import Model
from keras.callbacks import ModelCheckpoint
import matplotlib.pyplot as plt
# 层实例接受张量为参数,返回一个张量
inputs = Input(shape=(100,))
# a layer instance is callable on a tensor, and returns a tensor
# 输入inputs,输出x
# (inputs)代表输入
x = Dense(64, activation='relu')(inputs)
x = Dense(64, activation='relu')(x)
# 输入x,输出x
predictions = Dense(100, activation='softmax')(x)
# 输入x,输出分类
# This creates a model that includes
# the Input layer and three Dense layers
model = Model(inputs=inputs, outputs=predictions)
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
# Generate dummy data
import numpy as np
data = np.random.random((1000, 100))
labels = keras.utils.to_categorical(np.random.randint(2, size=(1000, 1)), num_classes=100)
# checkpoint
filepath="E:/Graphs/Models/weights.best.hdf5"
checkpoint = ModelCheckpoint(filepath, monitor='val_acc', verbose=1, save_best_only=True, mode='max')
callbacks_list = [checkpoint]
# Fit the model
model.fit(data, labels, validation_split=0.33, epochs=15, batch_size=10, callbacks=callbacks_list, verbose=0)
Epoch 00000: val_acc improved from -inf to 0.48036, saving model to E:/Graphs/Models/weights.best.hdf5
Epoch 00001: val_acc improved from 0.48036 to 0.51360, saving model to E:/Graphs/Models/weights.best.hdf5
Epoch 00002: val_acc did not improve
Epoch 00003: val_acc did not improve
Epoch 00004: val_acc improved from 0.51360 to 0.52568, saving model to E:/Graphs/Models/weights.best.hdf5
Epoch 00005: val_acc did not improve
Epoch 00006: val_acc improved from 0.52568 to 0.52568, saving model to E:/Graphs/Models/weights.best.hdf5
Epoch 00007: val_acc did not improve
Epoch 00008: val_acc did not improve
Epoch 00009: val_acc did not improve
Epoch 00010: val_acc did not improve
Epoch 00011: val_acc did not improve
Epoch 00012: val_acc did not improve
Epoch 00013: val_acc did not improve
Epoch 00014: val_acc did not improve
<keras.callbacks.History at 0x1a276ec1be0>
3.9 Loading a Check-Pointed Neural Network Model
# How to load and use weights from a checkpoint
from keras.models import Sequential
from keras.layers import Dense
from keras.callbacks import ModelCheckpoint
import matplotlib.pyplot as plt
# create model
model = Sequential()
model.add(Dense(64, input_dim=100, kernel_initializer='uniform', activation='relu'))
model.add(Dense(64, kernel_initializer='uniform', activation='relu'))
model.add(Dense(100, kernel_initializer='uniform', activation='sigmoid'))
# load weights
model.load_weights("E:/Graphs/Models/weights.best.hdf5")
# Compile model (required to make predictions)
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
print("Created model and loaded weights from file")
# Generate dummy data
import numpy as np
data = np.random.random((1000, 100))
labels = keras.utils.to_categorical(np.random.randint(2, size=(1000, 1)), num_classes=100)
# estimate accuracy on whole dataset using loaded weights
scores = model.evaluate(data, labels, verbose=0)
print("%s: %.2f%%" % (model.metrics_names[1], scores[1]*100))
Created model and loaded weights from file
acc: 99.00%
3.10 如何在 keras 中设定 GPU 使用的大小
本节来源于:深度学习theano/tensorflow多显卡多人使用问题集(参见:Limit the resource usage for tensorflow backend · Issue #1538 · fchollet/keras · GitHub)
在使用 keras 时候会出现总是占满 GPU 显存的情况,可以通过重设 backend 的 GPU 占用情况来进行调节。
import tensorflow as tf
from keras.backend.tensorflow_backend import set_session
config = tf.ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction = 0.3
set_session(tf.Session(config=config))
需要注意的是,虽然代码或配置层面设置了对显存占用百分比阈值,但在实际运行中如果达到了这个阈值,程序有需要的话还是会突破这个阈值。换而言之如果跑在一个大数据集上还是会用到更多的显存。以上的显存限制仅仅为了在跑小数据集时避免对显存的浪费而已。
Tips
更科学地训练与保存模型
from keras.datasets import mnist
from keras.models import Model
from keras.layers import Dense, Activation, Flatten, Input
(x_train, y_train), (x_test, y_test) = mnist.load_data()
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)
x_train.shape
(60000, 28, 28)
import keras
from keras.layers import Input, Dense
from keras.models import Model
from keras.callbacks import ModelCheckpoint
# 层实例接受张量为参数,返回一个张量
inputs = Input(shape=(28, 28))
x = Flatten()(inputs)
x = Dense(64, activation='relu')(x)
x = Dense(64, activation='relu')(x)
predictions = Dense(10, activation='softmax')(x)
# 输入x,输出分类
# This creates a model that includes
# the Input layer and three Dense layers
model = Model(inputs=inputs, outputs=predictions)
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_6 (InputLayer) (None, 28, 28) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 784) 0
_________________________________________________________________
dense_16 (Dense) (None, 64) 50240
_________________________________________________________________
dense_17 (Dense) (None, 64) 4160
_________________________________________________________________
dense_18 (Dense) (None, 10) 650
=================================================================
Total params: 55,050
Trainable params: 55,050
Non-trainable params: 0
_________________________________________________________________
filepath = 'E:/Graphs/Models/model-ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5'
checkpoint = ModelCheckpoint(filepath, monitor='val_loss', verbose=1, save_best_only=True, mode='min')
# fit model
model.fit(x_train, y_train, epochs=20, verbose=2, batch_size=64, callbacks=[checkpoint], validation_data=(x_test, y_test))
Train on 60000 samples, validate on 10000 samples
Epoch 1/20
Epoch 00000: val_loss improved from inf to 6.25477, saving model to E:/Graphs/Models/model-ep000-loss6.835-val_loss6.255.h5
10s - loss: 6.8349 - acc: 0.5660 - val_loss: 6.2548 - val_acc: 0.6063
Epoch 2/20
Epoch 00001: val_loss improved from 6.25477 to 5.75301, saving model to E:/Graphs/Models/model-ep001-loss5.981-val_loss5.753.h5
7s - loss: 5.9805 - acc: 0.6246 - val_loss: 5.7530 - val_acc: 0.6395
Epoch 3/20
Epoch 00002: val_loss did not improve
5s - loss: 5.8032 - acc: 0.6368 - val_loss: 5.9562 - val_acc: 0.6270
Epoch 4/20
Epoch 00003: val_loss improved from 5.75301 to 5.69140, saving model to E:/Graphs/Models/model-ep003-loss5.816-val_loss5.691.h5
7s - loss: 5.8163 - acc: 0.6363 - val_loss: 5.6914 - val_acc: 0.6451
Epoch 5/20
Epoch 00004: val_loss did not improve
6s - loss: 5.7578 - acc: 0.6404 - val_loss: 5.8904 - val_acc: 0.6317
Epoch 6/20
Epoch 00005: val_loss did not improve
7s - loss: 5.7435 - acc: 0.6417 - val_loss: 5.8636 - val_acc: 0.6342
Epoch 7/20
Epoch 00006: val_loss improved from 5.69140 to 5.68394, saving model to E:/Graphs/Models/model-ep006-loss5.674-val_loss5.684.h5
7s - loss: 5.6743 - acc: 0.6458 - val_loss: 5.6839 - val_acc: 0.6457
Epoch 8/20
Epoch 00007: val_loss improved from 5.68394 to 5.62847, saving model to E:/Graphs/Models/model-ep007-loss5.655-val_loss5.628.h5
6s - loss: 5.6552 - acc: 0.6472 - val_loss: 5.6285 - val_acc: 0.6488
Epoch 9/20
Epoch 00008: val_loss did not improve
6s - loss: 5.6277 - acc: 0.6493 - val_loss: 5.7295 - val_acc: 0.6422
Epoch 10/20
Epoch 00009: val_loss improved from 5.62847 to 5.55242, saving model to E:/Graphs/Models/model-ep009-loss5.577-val_loss5.552.h5
6s - loss: 5.5769 - acc: 0.6524 - val_loss: 5.5524 - val_acc: 0.6540
Epoch 11/20
Epoch 00010: val_loss improved from 5.55242 to 5.53212, saving model to E:/Graphs/Models/model-ep010-loss5.537-val_loss5.532.h5
6s - loss: 5.5374 - acc: 0.6550 - val_loss: 5.5321 - val_acc: 0.6560
Epoch 12/20
Epoch 00011: val_loss improved from 5.53212 to 5.53056, saving model to E:/Graphs/Models/model-ep011-loss5.549-val_loss5.531.h5
6s - loss: 5.5492 - acc: 0.6543 - val_loss: 5.5306 - val_acc: 0.6553
Epoch 13/20
Epoch 00012: val_loss improved from 5.53056 to 5.48013, saving model to E:/Graphs/Models/model-ep012-loss5.558-val_loss5.480.h5
7s - loss: 5.5579 - acc: 0.6538 - val_loss: 5.4801 - val_acc: 0.6587
Epoch 14/20
Epoch 00013: val_loss did not improve
6s - loss: 5.5490 - acc: 0.6547 - val_loss: 5.5233 - val_acc: 0.6561
Epoch 15/20
Epoch 00014: val_loss did not improve
7s - loss: 5.5563 - acc: 0.6541 - val_loss: 5.4960 - val_acc: 0.6580
Epoch 16/20
Epoch 00015: val_loss did not improve
6s - loss: 5.5364 - acc: 0.6554 - val_loss: 5.5200 - val_acc: 0.6567
Epoch 17/20
Epoch 00016: val_loss did not improve
6s - loss: 5.5081 - acc: 0.6571 - val_loss: 5.5577 - val_acc: 0.6544
Epoch 18/20
Epoch 00017: val_loss did not improve
6s - loss: 5.5281 - acc: 0.6560 - val_loss: 5.5768 - val_acc: 0.6530
Epoch 19/20
Epoch 00018: val_loss did not improve
6s - loss: 5.5146 - acc: 0.6567 - val_loss: 5.7057 - val_acc: 0.6447
Epoch 20/20
Epoch 00019: val_loss improved from 5.48013 to 5.46820, saving model to E:/Graphs/Models/model-ep019-loss5.476-val_loss5.468.h5
7s - loss: 5.4757 - acc: 0.6592 - val_loss: 5.4682 - val_acc: 0.6601
<keras.callbacks.History at 0x25b5ae27630>
如果 val_loss 提高了就会保存,没有提高就不会保存。
探寻有趣之事!

