

缓存穿透、缓存击穿、缓存雪崩
什么是缓存穿透?(限流,网关层面限制ip的单位请求)
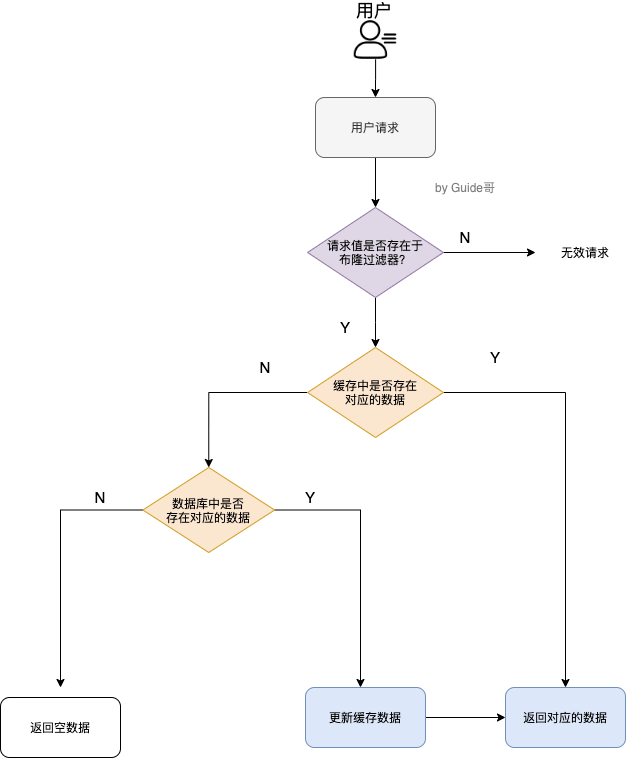
缓存穿透说简单点就是大量请求的 key 是不合理的,根本不存在于缓存中,也不存在于数据库中 。这就导致这些请求直接到了数据库上,根本没有经过缓存这一层,对数据库造成了巨大的压力,可能直接就被这么多请求弄宕机了。
解决办法:1、参数校验,一些不合法的参数请求直接抛出异常信息返回给客户端。比如查询的数据库 id 不能小于 0、传入的邮箱格式不对的时候直接返回错误消息给客户端等等。
2、缓存无效 key 短时间内有效,但不推荐
3、布隆过滤器 把所有可能存在的请求的值都存放在布隆过滤器中,当用户请求过来,先判断用户发来的请求的值是否存在于布隆过滤器中。不存在的话,直接返回请求参数错误信息给客户端,存在的话才会走下面的流程
什么是缓存击穿?
缓存击穿中,请求的 key 对应的是 热点数据 ,该数据 存在于数据库中,但不存在于缓存中(通常是因为缓存中的那份数据已经过期) 。这就可能会导致瞬时大量的请求直接打到了数据库上,对数据库造成了巨大的压力,可能直接就被这么多请求弄宕机了。
有哪些解决办法?
- 设置热点数据永不过期或者过期时间比较长。
- 针对热点数据提前预热,将其存入缓存中并设置合理的过期时间比如秒杀场景下的数据在秒杀结束之前不过期。
- 请求数据库写数据到缓存之前,先获取互斥锁,保证只有一个请求会落到数据库上,减少数据库的压力。
缓存雪崩
缓存在同一时间大面积的失效,导致大量的请求都直接落到了数据库上,对数据库造成了巨大的压力。 这就好比雪崩一样,摧枯拉朽之势,数据库的压力可想而知,可能直接就被这么多请求弄宕机了。
针对 Redis 服务不可用的情况:
- 采用 Redis 集群,避免单机出现问题整个缓存服务都没办法使用。
- 限流,避免同时处理大量的请求。
针对热点缓存失效的情况:
- 设置不同的失效时间比如随机设置缓存的失效时间。
- 缓存永不失效(不太推荐,实用性太差)。
- 设置二级缓存。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY