
JVM调优
一、参数基本策略
各分区的大小对GC的性能影响很大。如何将各分区调整到合适的大小,分析活跃数据的大小是很好的切入点。
活跃数据的大小是指,应用程序稳定运行时长期存活对象在堆中占用的空间大小,也就是Full GC后堆中老年代占用空间的大小。可以通过GC日志中Full GC之后老年代数据大小得出,比较准确的方法是在程序稳定后,多次获取GC数据,通过取平均值的方式计算活跃数据的大小。活跃数据和各分区之间的比例关系如下
例如,根据GC日志获得老年代的活跃数据大小为300M,那么各分区大小可以设为:
总堆:1200MB = 300MB × 4* 新生代:450MB = 300MB × 1.5* 老年代: 750MB = 1200MB - 450MB*
如果满足下面的指标,则一般不需要进行 GC 优化:
MinorGC 执行时间不到50ms; Minor GC 执行不频繁,约10秒一次; Full GC 执行时间不到1s; Full GC 执行频率不算频繁,不低于10分钟1次。
二、优化步骤
GC优化一般步骤可以概括为:确定目标、优化参数、验收结果。
目标: - 高可用,可用性达到几个9。 - 低延迟,请求必须多少毫秒内完成响应。 - 高吞吐,每秒完成多少次事务。
注:
高可用HA(High Availability)是分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计减少系统不能提供服务的时间。
假设系统一直能够提供服务,我们说系统的可用性是100%。
如果系统每运行100个时间单位,会有1个时间单位无法提供服务,我们说系统的可用性是99%。
很多公司的高可用目标是4个9,也就是99.99%,这就意味着,系统的年停机时间为8.76个小时。
明确系统需求之所以重要,是因为上述性能指标间可能冲突。比如通常情况下,缩小延迟的代价是降低吞吐量或者消耗更多的内存或者两者同时发生。
由于笔者所在团队主要关注高可用和低延迟两项指标,所以接下来分析,如何量化GC时间和频率对于响应时间和可用性的影响。通过这个量化指标,可以计算出当前GC情况对服务的影响,也能评估出GC优化后对响应时间的收益,这两点对于低延迟服务很重要。
举例:假设单位时间T内发生一次持续25ms的GC,接口平均响应时间为50ms,且请求均匀到达,根据下图所示:
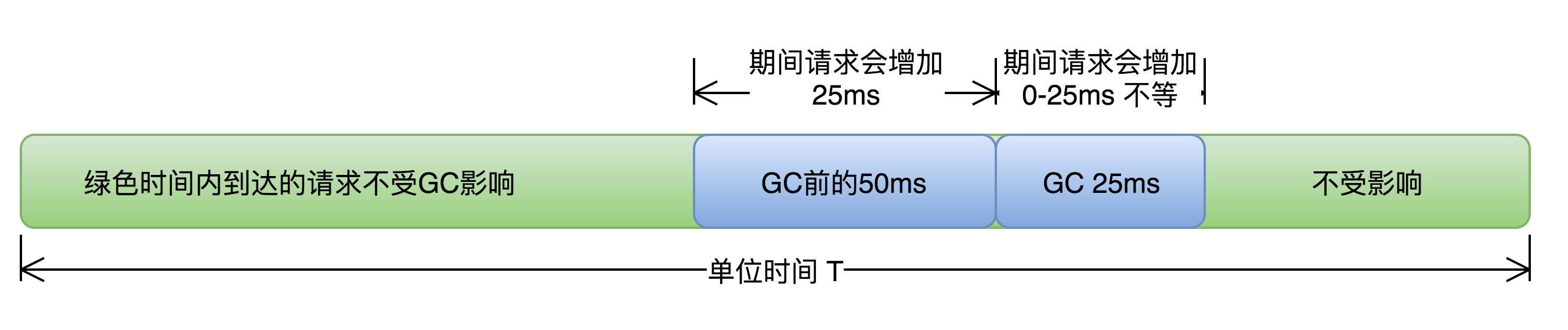
那么有(50ms+25ms)/T比例的请求会受GC影响,其中GC前的50ms内到达的请求都会增加25ms,GC期间的25ms内到达的请求,会增加0-25ms不等,如果时间T内发生N次GC,受GC影响请求占比=(接口响应时间+GC时间)×N/T 。可见无论降低单次GC时间还是降低GC次数N都可以有效减少GC对响应时间的影响。
我们通过三个案例来实践以上的优化流程和基本原则(本文中三个案例使用的垃圾回收器均为ParNew(新生代)+CMS(老年代),CMS失败时Serial Old替补)。
案例一 Major GC和Minor GC频繁
确定目标
服务情况:Minor GC每分钟100次 ,Major GC每4分钟一次,单次Minor GC耗时25ms,单次Major GC耗时200ms,接口响应时间50ms。
由于这个服务要求低延时高可用,结合上文中提到的GC对服务响应时间的影响,计算可知由于Minor GC的发生,12.5%的请求响应时间会增加,其中8.3%的请求响应时间会增加25ms,可见当前GC情况对响应时间影响较大。
(50ms+25ms)× 100次/60000ms = 12.5%,50ms × 100次/60000ms = 8.3% 。
优化目标:降低TP99、TP90时间。
优化
首先优化Minor GC频繁问题。通常情况下,由于新生代空间较小,Eden区很快被填满,就会导致频繁Minor GC,因此可以通过增大新生代空间来降低Minor GC的频率。例如在相同的内存分配率的前提下,新生代中的Eden区增加一倍,Minor GC的次数就会减少一半。
注:单次Minor GC时间更多取决于GC后存活对象的数量,而非Eden区的大小。因为对JVM复制对象的成本要远高于扫描成本,新生代使用复制算法,因为耗时在复制而不是扫描
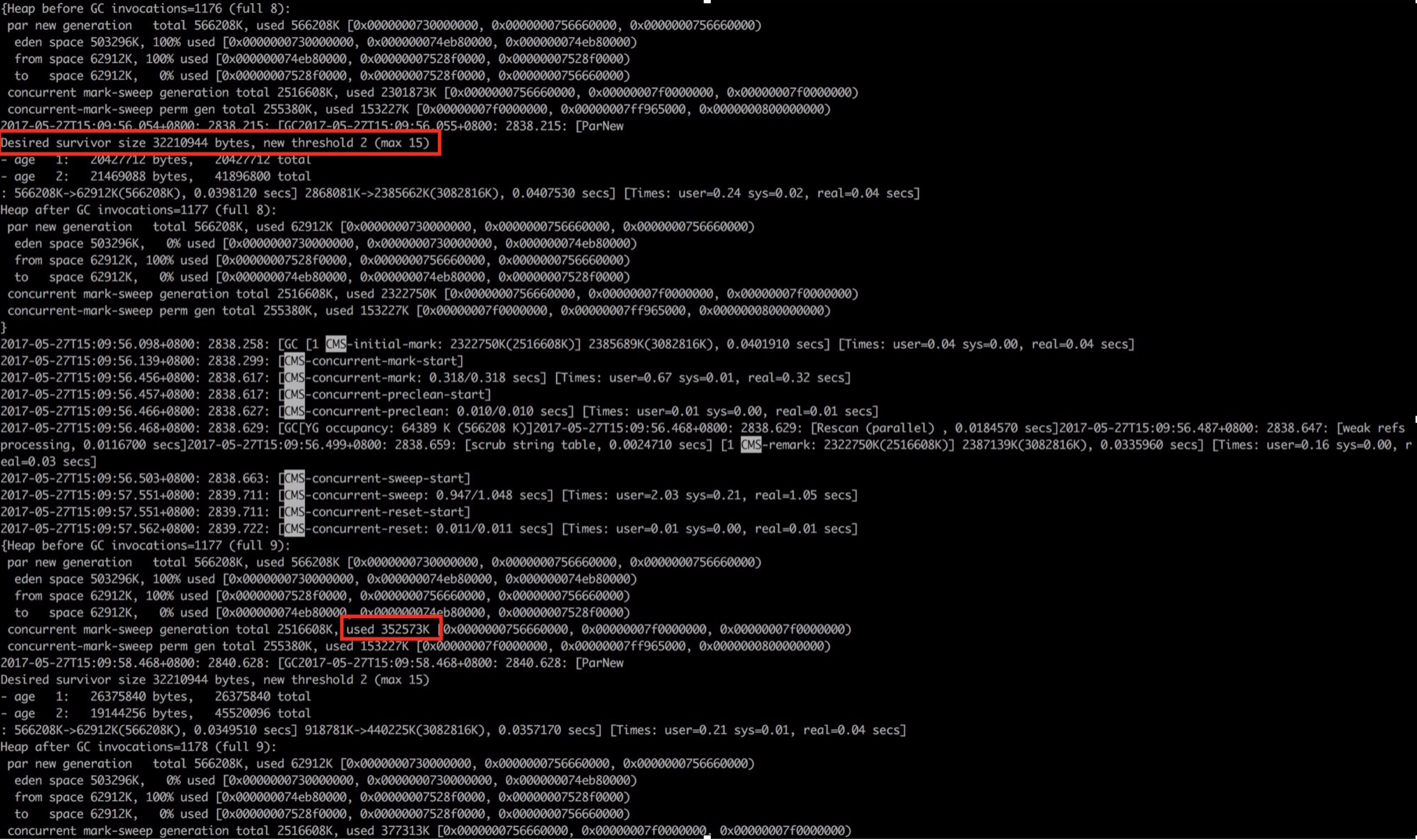
通过上图GC日志中两处红色框标记内容可知: 1. new threshold = 2(动态年龄判断,对象的晋升年龄阈值为2),对象仅经历2次Minor GC后就晋升到老年代,这样老年代会迅速被填满,直接导致了频繁的Major GC。 2. Major GC后老年代使用空间为300M+,意味着此时绝大多数(86% = 2G/2.3G)的对象已经不再存活,也就是说生命周期长的对象占比很小。
由此可见,服务中存在大量短期临时对象,扩容新生代空间后,Minor GC频率降低,对象在新生代得到充分回收,只有生命周期长的对象才进入老年代。这样老年代增速变慢,Major GC频率自然也会降低。
优化结果
通过扩容新生代为为原来的三倍,单次Minor GC时间增加小于5ms,频率下降了60%,服务响应时间TP90,TP99都下降了10ms+,服务可用性得到提升。
小结
如何选择各分区大小应该依赖应用程序中对象生命周期的分布情况:如果应用存在大量的短期对象,应该选择较大的年轻代;如果存在相对较多的持久对象,老年代应该适当增大。
更多思考
关于上文中提到晋升年龄阈值为2,很多同学有疑问,为什么设置了MaxTenuringThreshold=15,对象仍然仅经历2次Minor GC,就晋升到老年代?这里涉及到“动态年龄计算”的概念。
动态年龄计算:Hotspot遍历所有对象时,按照年龄从小到大对其所占用的大小进行累积,当累积的某个年龄大小超过了survivor区的一半时,取这个年龄和MaxTenuringThreshold中更小的一个值,作为新的晋升年龄阈值。在本案例中,调优前:Survivor区 = 64M,desired survivor = 32M,此时Survivor区中age<=2的对象累计大小为41M,41M大于32M,所以晋升年龄阈值被设置为2,下次Minor GC时将年龄超过2的对象被晋升到老年代。
JVM引入动态年龄计算,主要基于如下两点考虑:
-
如果固定按照MaxTenuringThreshold设定的阈值作为晋升条件: a)MaxTenuringThreshold设置的过大,原本应该晋升的对象一直停留在Survivor区,直到Survivor区溢出,一旦溢出发生,Eden+Svuvivor中对象将不再依据年龄全部提升到老年代,这样对象老化的机制就失效了。 b)MaxTenuringThreshold设置的过小,“过早晋升”即对象不能在新生代充分被回收,大量短期对象被晋升到老年代,老年代空间迅速增长,引起频繁的Major GC。分代回收失去了意义,严重影响GC性能。
-
相同应用在不同时间的表现不同:特殊任务的执行或者流量成分的变化,都会导致对象的生命周期分布发生波动,那么固定的阈值设定,因为无法动态适应变化,会造成和上面相同的问题。
总结来说,为了更好的适应不同程序的内存情况,虚拟机并不总是要求对象年龄必须达到Maxtenuringthreshhold再晋级老年代。
参考:https://tech.meituan.com/2017/12/29/jvm-optimize.html



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· winform 绘制太阳,地球,月球 运作规律
· 上周热点回顾(3.3-3.9)