
基本数据类型大小 字符集、编码规范(gdk utf-8等)
位(bit):是计算机 内部数据 储存的最小单位,11001100是一个八位二进制数。
字节(byte):是计算机中 数据处理 的基本单位,习惯上用大写 B 来表示,1B(byte,字节)= 8bit(位)
字符:是指计算机中使用的字母、数字、字和符号
基本单位都是字节(byte),1个字符是2个字节
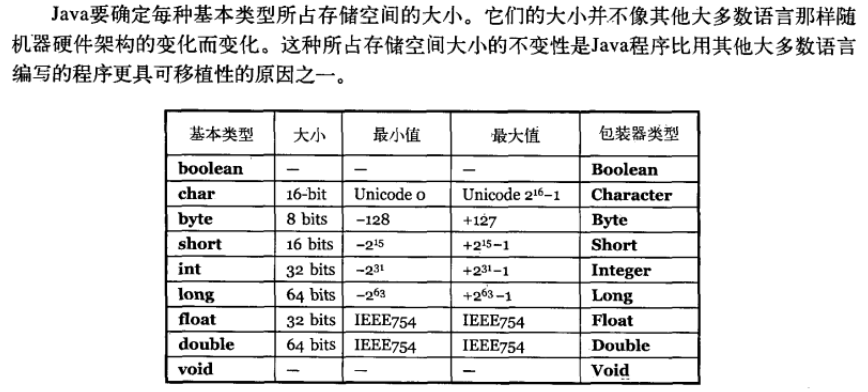
类型 存储需求 bit数 取值范围
byte 1字节 1*8 (-2的31次方到2的31次方-1)boolean 1字节 1*8 false、trueshort 2字节 2*8 -32768~32767int 4字节 4*8 (-2的63次方到2的63次方-1)long 8字节 8*8 -128~127float 4字节 4*8 float类型的数值有一个后缀F(例如:3.14F)double 8字节 8*8 没有后缀F的浮点数值(如3.14)默认为double类型编码规范
所谓字符集其实是一套编码规范中的子概念,为了显示字符,国际组织就制定了编码规范,希望使用不同的二进制数来表示代表不同的字符,这样电脑就可以根据二进制数来显示其对应的字符。我们通常就称呼其为XX编码,XX字符集。
例如:ASCII码、ISO-8859-1(不支持中文)、Unicode(全世界通用的编码规范)、GBK 编码规范,编码规范,计算机就可以在中文字符和二进制数之间相互转换。而使用GBK编码就可以使计算机显示中文字符。
编码规范子概念:
1.字库表
一套编码规范不一定包含世界上所有的字符,每套编码规范都有自己的使用场景。而字库表就存储了编码规范中能显示的所有字符,计算机就是根据二进制数从字库表中找到字符然后显示给用户滴,相当于一个存储字符的数据库。
例如:几乎所有汉字都保存在GBK 编码规范的字库表中。所以可以显示汉字,但法语,俄语并不在其字库表中,所以GBK不能显示法语,俄语等不包含在其中的字符。
2.编码字符集(字符集),存放二进制数
我们平时说的字符集就是这个。在一个字库表中,每一个字符都有一个对应的二进制地址,而编码字符集就是这些地址的集合。
例如:在ASCII码的编码字符集中,字母A的序号(地址)是65,65的二进制就是01000001。我们可以说编码字符集就是用来存储这些二进制数的。而这个二进制数就是编码字符集中的一个元素,同时它也是字库表中字母A的地址。我们根据这个地址就可以显示出字母A。
结论:字符集和字库表一一对应,相互转换,这是电脑识别字符的关键。
3.字符编码(编码方式)
知道字库表和编码字符集后,我们就可以直接使用二进制地址来得到字符了。
但直接使用字符对应的二进制地址来显示文字是十分浪费的,Unicode 编码规范中包括了几百万个字符,想要包括几百万个不同的字符,起码需要3个字节的容量,为了方便将来扩展,Unicode还保留了更多未使用的空间,最多可以存储4个字节的容量。
因此为了区分每个字符,哪怕是00000000 00000000 00000000 00001111这种其实只占了1个字节的字符,我们也要为他分配4个字节的空间,这就导致一个可以用1G保存的文件,现在需要4G才能保存,这是极其浪费的做法。
于是程序员制定了一套算法来节省空间,而每种不同的算法都被称作一种编码方式(下文中为了便于理解都将使用编码方式来称呼字符编码)。一套编码规范可以有多种不同的编码方式,不同的编码方式有不同的适应场景。
例如:UTF-8就是一种编码方式,Unicode是一种编码规范。此外,Unicode还有UTF-16,UTF-32这两种编码方式。不同的编码方式节约的空间不同。
总结:一个较短的二进制数,通过一种编码方式,转换成编码字符集中正常的地址,然后在字库表中找到一个对应的字符,最终显示给用户。
常见编码规范:
1、ASCII码,是最早产生的编码规范,一共包含00000000~01111111共128个字符,可以表示阿拉伯数字和大小写英文字母,以及一些简单的符号
2、GBK全称《汉字内码扩展规范》,支持国际标准ISO/IEC10646-1和国家标准GB13000-1中的全部中日韩汉字。GBK字符集中所有字符占2个字节,不论中文英文都是2个字节。 没有特殊的编码方式,习惯称呼GBK 编码。一般在国内,汉字较多时使用
3、SO-8859-1收录的字符除ASCII收录的字符外,还包括西欧语言、希腊语、泰语、阿拉伯语、希伯来语对应的文字符号;ISO-8859-1是不支持中文的
4、Unicode,全世界通用的编码规范。Unicode最多可以保存4个字节容量的字符。也就是说,要区分每个字符,每个字符的地址需要4个字节。这是十分浪费存储空间的,于是,程序员就设计了几种字符编码方式,比如:UTF-8,UTF-16,UTF-32。
注意:UTF-8不是编码规范,而是编码方式
String chinese="汉"; //使用UTF-8编码方式进行编码。 byte[] bs = chinese.getBytes("UTF-8"); for (byte b : bs) { System.out.print(b+" "); }" "); }
输出结果:-26 -79 -119 //可见utf-8的编码方式下,1个汉字对应3个字节
String utf8 = new String(bs,"UTF-8"); System.out.println(utf8);
输出:汉 //字节转换成字符
String gbk = new String(bs, "GBK"); System.out.println(gbk);
输出:姹?
|
字母/数字/英文标点 |
中文汉字/中文标点 |
换行符 Win/Unix/mac |
空白文件大小 |
空格 |
|||
|
ansi |
1 |
2 |
1 |
1 |
1 |
0 |
1 |
|
Utf8 |
1 |
3 |
2 |
1 |
1 |
0 |
1 |
|
Utf8-bom |
1 |
3 |
2 |
1 |
1 |
3 |
1 |
|
GBk2312 |
1 |
2 |
2 |
1 |
1 |
0(不为空前面加3) |
1 |
转自:
————————————————
版权声明:本文为CSDN博主「笑我归无处」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_42068856/article/details/83792174



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· winform 绘制太阳,地球,月球 运作规律
· 上周热点回顾(3.3-3.9)