

在项目中重新搭建一套读写分离+高可用+多master的redis cluster集群
redis cluster模式下,不建议做物理的读写分离了
我们建议通过master的水平扩容,来横向扩展读写吞吐量,还有支撑更多的海量数据
redis单机,读吞吐是5w/s,写吞吐2w/s
扩展redis更多master,那么如果有5台master,不就读吞吐可以达到总量25/s QPS,写可以达到10w/s QPS
redis单机,内存,6G,8G,fork类操作的时候很耗时,会导致请求延时的问题
扩容到5台master,能支撑的总的缓存数据量就是30G,40G -> 100台,600G,800G,甚至1T+,海量数据
redis是怎么扩容的
1、加入新master
mkdir -p /var/redis/7007
port 7007
cluster-enabled yes
cluster-config-file /etc/redis-cluster/node-7007.conf
cluster-node-timeout 15000
daemonize yes
pidfile /var/run/redis_7007.pid
dir /var/redis/7007
logfile /var/log/redis/7007.log
bind 192.168.31.227
appendonly yes
搞一个7007.conf,再搞一个redis_7007启动脚本
手动启动一个新的redis实例,在7007端口上
redis-trib.rb add-node 192.168.31.227:7007 192.168.31.187:7001
redis-trib.rb check 192.168.31.187:7001
连接到新的redis实例上,cluster nodes,确认自己是否加入了集群,作为了一个新的master
2、reshard一些数据过去
resharding的意思就是把一部分hash slot从一些node上迁移到另外一些node上
redis-trib.rb reshard 192.168.31.187:7001
要把之前3个master上,总共4096个hashslot迁移到新的第四个master上去
How many slots do you want to move (from 1 to 16384)?
1000
3、添加node作为slave
eshop-cache03
mkdir -p /var/redis/7008
port 7008
cluster-enabled yes
cluster-config-file /etc/redis-cluster/node-7008.conf
cluster-node-timeout 15000
daemonize yes
pidfile /var/run/redis_7008.pid
dir /var/redis/7008
logfile /var/log/redis/7008.log
bind 192.168.31.227
appendonly yes
redis-trib.rb add-node --slave --master-id 28927912ea0d59f6b790a50cf606602a5ee48108 192.168.31.227:7008 192.168.31.187:7001
4、删除node
先用resharding将数据都移除到其他节点,确保node为空之后,才能执行remove操作
redis-trib.rb del-node 192.168.31.187:7001 bd5a40a6ddccbd46a0f4a2208eb25d2453c2a8db
2个是1365,1个是1366
当你清空了一个master的hashslot时,redis cluster就会自动将其slave挂载到其他master上去
这个时候就只要删除掉master就可以了
------------恢复内容开始------------
redis cluster最最基础的一些知识
redis cluster: 自动,master+slave复制和读写分离,master+slave高可用和主备切换,支持多个master的hash slot支持数据分布式存储
停止之前所有的实例,包括redis主从和哨兵集群
1、redis cluster的重要配置
cluster-enabled <yes/no>
cluster-config-file <filename>:这是指定一个文件,供cluster模式下的redis实例将集群状态保存在那里,包括集群中其他机器的信息,比如节点的上线和下限,故障转移,不是我们去维护的,给它指定一个文件,让redis自己去维护的
cluster-node-timeout <milliseconds>:节点存活超时时长,超过一定时长,认为节点宕机,master宕机的话就会触发主备切换,slave宕机就不会提供服务
2、在三台机器上启动6个redis实例
(1)在eshop-cache03上部署目录
/etc/redis(存放redis的配置文件),/var/redis/6379(存放redis的持久化文件)
(2)编写配置文件
redis cluster集群,要求至少3个master,去组成一个高可用,健壮的分布式的集群,每个master都建议至少给一个slave,3个master,3个slave,最少的要求
正式环境下,建议都是说在6台机器上去搭建,至少3台机器
保证,每个master都跟自己的slave不在同一台机器上,如果是6台自然更好,一个master+一个slave就死了
3台机器去搭建6个redis实例的redis cluster
mkdir -p /etc/redis-cluster
mkdir -p /var/log/redis
mkdir -p /var/redis/7001
port 7001
cluster-enabled yes
cluster-config-file /etc/redis-cluster/node-7001.conf
cluster-node-timeout 15000
daemonize yes
pidfile /var/run/redis_7001.pid
dir /var/redis/7001
logfile /var/log/redis/7001.log
bind 192.168.31.187
appendonly yes
至少要用3个master节点启动,每个master加一个slave节点,先选择6个节点,启动6个实例
将上面的配置文件,在/etc/redis下放6个,分别为: 7001.conf,7002.conf,7003.conf,7004.conf,7005.conf,7006.conf
(3)准备生产环境的启动脚本
在/etc/init.d下,放6个启动脚本,分别为: redis_7001, redis_7002, redis_7003, redis_7004, redis_7005, redis_7006
每个启动脚本内,都修改对应的端口号
(4)分别在3台机器上,启动6个redis实例
将每个配置文件中的slaveof给删除
3、创建集群
下面方框内的内容废弃掉
=======================================================================
wget https://cache.ruby-lang.org/pub/ruby/2.3/ruby-2.3.1.tar.gz
tar -zxvf ruby-2.3.1.tar.gz
./configure -prefix=/usr/local/ruby
make && make install
cd /usr/local/ruby
cp bin/ruby /usr/local/bin
cp bin/gem /usr/local/bin
wget http://rubygems.org/downloads/redis-3.3.0.gem
gem install -l ./redis-3.3.0.gem
gem list --check redis gem
=======================================================================
因为,以前比如公司里面搭建集群,公司里的机器的环境,运维会帮你做好很多事情
在讲课的话,我们手工用从零开始装的linux虚拟机去搭建,那肯定会碰到各种各样的问题
yum install -y ruby
yum install -y rubygems
gem install redis
cp /usr/local/redis-3.2.8/src/redis-trib.rb /usr/local/bin
redis-trib.rb create --replicas 1 192.168.31.187:7001 192.168.31.187:7002 192.168.31.19:7003 192.168.31.19:7004 192.168.31.227:7005 192.168.31.227:7006
--replicas: 每个master有几个slave
6台机器,3个master,3个slave,尽量自己让master和slave不在一台机器上
yes
redis-trib.rb check 192.168.31.187:7001
4、读写分离+高可用+多master
读写分离:每个master都有一个slave
高可用:master宕机,slave自动被切换过去
多master:横向扩容支持更大数据量
================================开始搭建==================================
Cluster模式-3.0开始推出的
采用无中心结构,每个节点保存数据和整个集群状态,每个节点都和其他节点连接
官方要求:至少6个节点才可以保证高可用,3主3从;扩展性强,更好做到高可用
数据分散存储到各个节点上
集群环境准备:
旧版本需要使用ruby语言进行构建,新版本5之后直接使用redis-cli即可
6个节点,三主三从,主从节点会自动分配,不是人工指定
主节点故障后,从节点会替换主节点
#是否开启集群
cluster-enabled yes
#生成的node文件,记录集群节点信息,默认no
cluster-config-file nodes-6381.conf
#集群节点ip,当前节点ip
cluster-announce-ip 192.168.31.20
#集群节点映射端口
cluster-announce-port 6381
#集群节点总线端口,节点之间互相通信,常规端口+2w
cluster-announce-bus-port 26381
不过我们的是4.0版本使用ruby进行构建。
1.把集群相关的机器停止掉,包括哨兵
redis-cli -h 192.168.31.186 -a 123456 -p 6379 SHUTDOWN
redis-cli -h 192.168.31.186 -a 123456 -p 26379 SHUTDOWN
redis-cli -h 192.168.31.244 -a 123456 -p 6379 SHUTDOWN
redis-cli -h 192.168.31.244 -a 123456 -p 26379 SHUTDOWN
redis-cli -h 192.168.31.20 -a 123456 -p 6379 SHUTDOWN
redis-cli -h 192.168.31.20 -a 123456 -p 26379 SHUTDOWN
2.config需要增加重要的配置,修改如下,3个文件变成6个文件,修改启动测脚本,配置多个
31.20 机器上:
mkdir -p /etc/redis-cluster
mkdir -p /var/redis/7001
mkdir -p /var/redis/7002
将etc/redis中的配置文件复制,cp 6379.conf 7001.conf
更改配置:
port 7001
cluster-enabled yes
cluster-config-file /etc/redis-cluster/node-7001.conf
cluster-node-timeout 15000
daemonize yes
pidfile /var/run/redis_7001.pid
dir /var/redis/7001
logfile "/usr/local/redis/log/7001.log"
bind 192.168.31.20
appendonly yes
cp 7001.conf 7002.conf
rm -rf 6379.conf
在当前目录
scp 7002.conf root@192.168.31.186:/etc/redis/7003.conf
scp 7002.conf root@192.168.31.186:/etc/redis/7004.conf
修改31.186的conf相关配置和上面的数据匹配,包括
mkdir -p /etc/redis-cluster
mkdir -p /var/redis/7003
mkdir -p /var/redis/7004
7003和7004都需要进行更改对应数据
port 7003
cluster-enabled yes
cluster-config-file /etc/redis-cluster/node-7003.conf
cluster-node-timeout 15000
daemonize yes
pidfile /var/run/redis_7003.pid
dir /var/redis/7003
logfile "/usr/local/redis/log/7003.log"
bind 192.168.31.186
appendonly yes
31.244服务器上继续重复上面操作
scp 7004.conf root@192.168.31.244:/etc/redis/7005.conf
scp 7004.conf root@192.168.31.244:/etc/redis/7006.conf
准备生产环境的启动脚本
修改etc/init.d,把redis_6379,复制俩,删除源文件,修改redis_7001,redis_7002
主要修改文件这俩地方改为对应文件的端口地址
REDISPORT=7001
RESOURCE="/var/redis/7001"
都给start起来看一下
查看:/usr/local/redis/log/7003.log
:C 04 Feb 16:30:21.683 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
15733:C 04 Feb 16:30:21.683 # Redis version=4.0.11, bits=64, commit=00000000, modified=0, pid=15733, just started
15733:C 04 Feb 16:30:21.683 # Configuration loaded
15734:M 04 Feb 16:30:21.685 * Increased maximum number of open files to 10032 (it was originally set to 1024).
15734:M 04 Feb 16:30:21.686 * No cluster configuration found, I'm 0dae0a094e826e02ab8cb8362c1e1976939326a8
15734:M 04 Feb 16:30:21.688 * Running mode=cluster, port=7003.
15734:M 04 Feb 16:30:21.688 # Server initialized
15734:M 04 Feb 16:30:21.688 # WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.
15734:M 04 Feb 16:30:21.688 # WARNING you have Transparent Huge Pages (THP) support enabled in your kernel. This will create latency and memory usage issues with Redis. To fix this issue run the command 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' as root, and add it to your /etc/rc.local in order to retain the setting after a reboot. Redis must be restarted after THP is disabled.
15734:M 04 Feb 16:30:21.688 * DB loaded from append only file: 0.000 seconds
15734:M 04 Feb 16:30:21.688 # I have keys for unassigned slot 449. Taking responsibility for it.
15734:M 04 Feb 16:30:21.688 # I have keys for unassigned slot 12706. Taking responsibility for it.
15734:M 04 Feb 16:30:21.689 * Ready to accept connections
15734:M 04 Feb 16:45:22.101 * 1 changes in 900 seconds. Saving...
15734:M 04 Feb 16:45:22.102 * Background saving started by pid 15870
15870:C 04 Feb 16:45:22.131 * DB saved on disk
15870:C 04 Feb 16:45:22.131 * RDB: 8 MB of memory used by copy-on-write
15734:M 04 Feb 16:45:22.222 * Background saving terminated with success
[root@MiWiFi-R4CM-srv log]#
安装插件:
yum install -y ruby
yum install -y rubygems
gem install redis
后面报错:
[root@MiWiFi-R4CM-srv redis]# gem install redis
Fetching: redis-4.6.0.gem (100%)
ERROR: Error installing redis:
redis requires Ruby version >= 2.4.0.
说需要版本升级:
https://www.ruby-lang.org/zh_cn/downloads/
官网最新3.1版本
目前是
ruby 2.0.0p648 (2015-12-16) [x86_64-linux]
升级下载需要
RVM 是一个命令行工具,可以提供一个便捷的多版本 Ruby 环境的管理和切换。
升级版本需要依赖rvm: rvm 安装
我的redis安装目录中的
cp /root/redis-4.0.11/src/redis-trib.rb /usr/local/bin
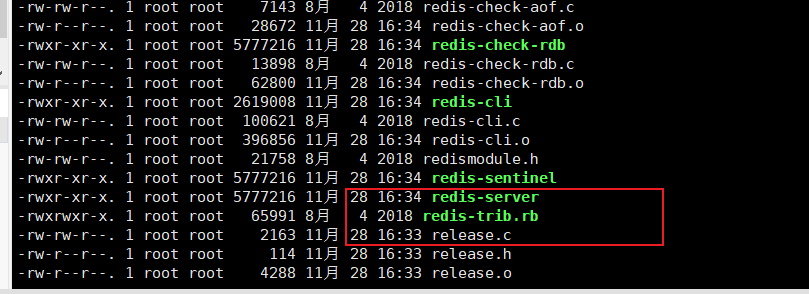

redis-trib.rb create --replicas 1 192.168.31.20:7001 192.168.31.20:7002 192.168.31.186:7003 192.168.31.186:7004 192.168.31.244:7005 192.168.31.244:7006

把几份配置文件修改,protected-mode,和密码访问注释,还有复制的ip信息注释bind注释了。
加了开机自启。
再次访问命令后报错不一样了,哭...

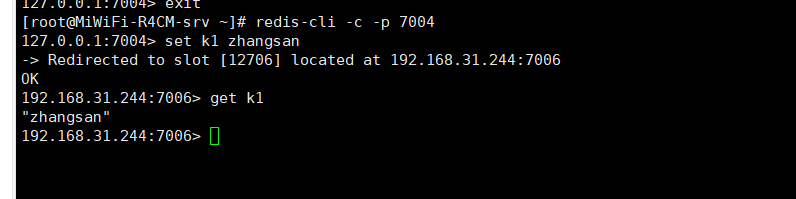
进入命令行想set值,不好意思,报错,没有分配槽
(error) CLUSTERDOWN Hash slot not served
清空每个redis里面的数据,flushdb命令,这还真是体力活。
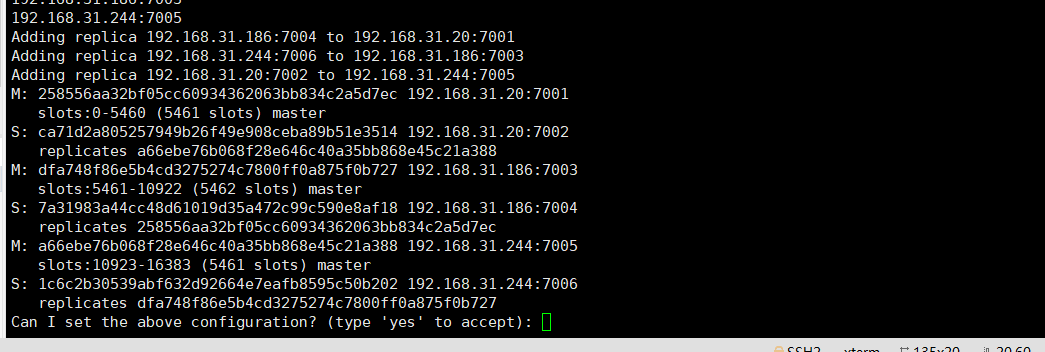
搭建成功!
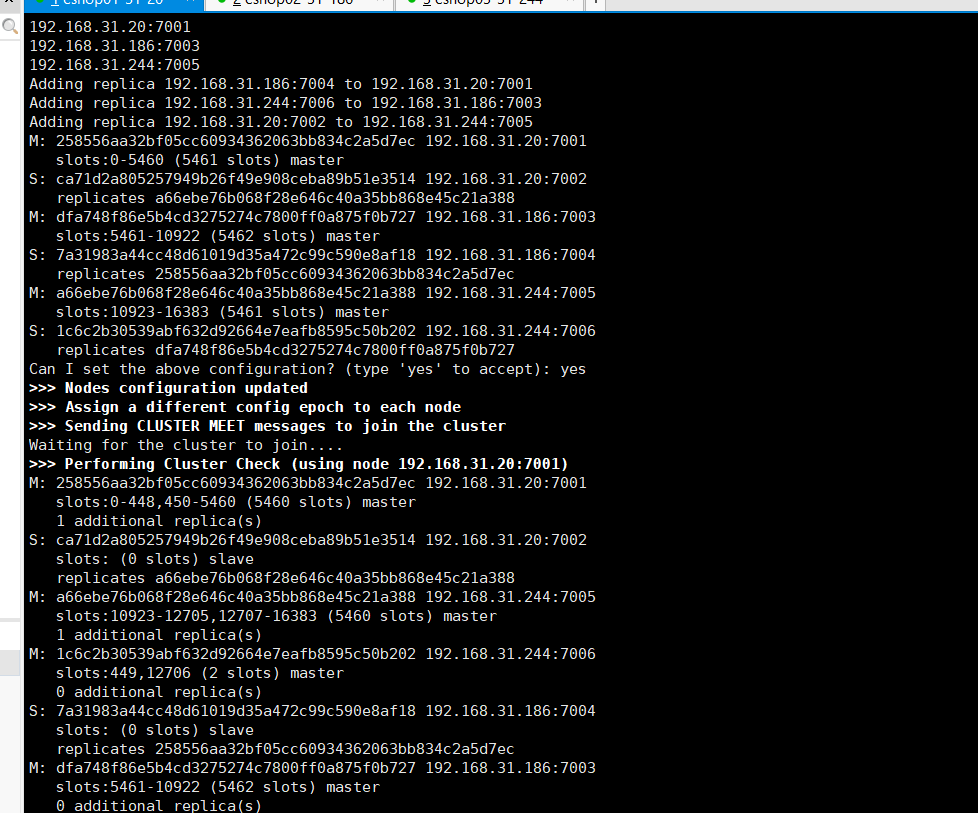
又失败了,我这分片分的就离谱,添加数据只能7006添加,别的添加报错,添加一条数据库都有一份,别的库还看不了
redis-cli报错:(error) MOVED 12706 (未以集群模式连接)
需要改变思维了,用集群的方式连接才不会报错。
客户端连接的方式也是一样的。
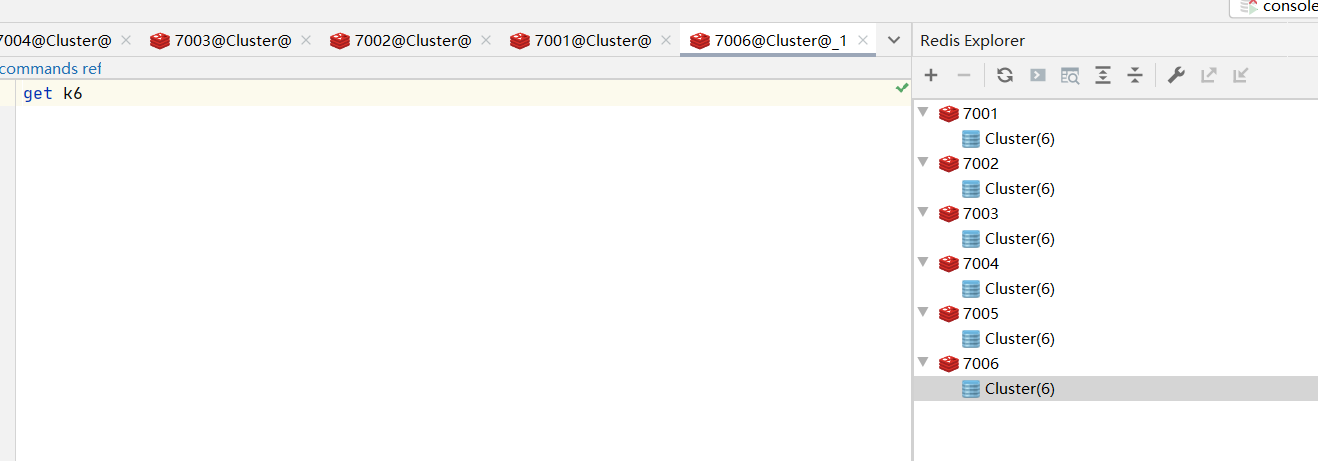
每个都能读,每个都能写
---------------------------------------------------------------------------
国之殇,未敢忘!
南京大屠杀!
731部队!
(有关书籍《恶魔的饱食》)以及核污染水排海等一系列全无人性的操作,购买他们的食品和为它们提供帮助只会更加变本加厉的害你,呼吁大家不要购买日本相关产品
昭昭前事,惕惕后人
吾辈当自强,方使国不受他人之侮!
---------------------------------------------------------------------------
作者:三号小玩家
出处:https://www.cnblogs.com/q1359720840/
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。 版权信息

