
C++ 编程中 的性能问题
摘抄于《C++ API 设计》 第七章 - 性能
Api性能主题
1.编译时速度:API对于编译客户程序所消耗时间影响。会影响用户的生产率
2.运行时速度:调用api的耗时,需要考虑到不同的输入规模
3.运行时内存开销:api的内存开销,影响CPU缓存性能
4.库的大小:影响客户应用程序所需的磁盘空间总量和内存占用
5.启动时间:加载并初始化实现API的动态库所需的时间。
性能优化经验:
绝不应该相信你的 “那些部分会比较慢” 的直觉,而应该在时间环境中测量api的真实性能概况,将优化精力集中在影响最大的部分。
可以没有必要一开始就实现最高效的api:先用一种简单的方式实现,在一切正常工作后,再找出需要优化的部分。
1.通过 const & 传递输入参数
默认情况下,C++中的函数参数 是 以传值方式传递的。说明,传递给函数的对象 会被复制,并在函数返回后销毁。
如此一来,传递给函数的原始对象就不会被修改。然而,这样会带来 调用对象的复制构造和析构函数的开销(内存、性能)。这个对应 栈空间非常有限的嵌入式系统尤为重要
对应 内置类型(int,bool,float......)不适用,原因:因为他们已经很小,能够放入CPU寄存器中。STL迭代器 和 函数对象 是采用传值方式 ,也不适用。
避免以传值方式传递参数 有另一个原因:切割问题:
如果函数参数 以 传值方式 接受一个基类参数,如果传入一个派生类对象,那么派生类中任何超出范围的字段都会被切掉,因为传递的时候,对象大小在编译时,被确定为基类的大小。
2.最小化#include依赖
编译 一个 工程 花费的时间 很大程度上取决于 #include 文件数量和深度
1.避免“无所不包型”头文件
这样的头文件会增加客户代码和API的编译耦合度
2.前置声明
使用场景:
(1).不需要知道类的大小。如果包含类要作为成员变量 或 打算从包含类 派生紫烈,那么编译器需要知道类的大小
(2).没有引用类的任何成员方法。引用类的成员方法需要知道方法原先,即参数和返回值类型
(3).没有引用 类的任何成员变量。但是一般 类的成员变量是私有的。
3. 声明常量
可能 设置常量时,会在头文件的全局作用域 以这种方式声明 一些常量:
const int MAX_NAME_LENGTH = 128;
const float LOG_2E = log2(2.71828183.f);
const std::string LOG_FILENAME = "filename.log";
默认情况下,这种方式 定义的变量会初始编译器为每个包含该头文件的模块分配变量存储空间。
如果定义了很多常量,并且api头文件被很多.cpp文件包含,会导致客户的目标文件 和 最终二进制文件膨胀。
解决办法:用extern声明常量:
extern const int MAX_NAME_LENGTH;
extern const float LOG_2E;
extern const std::string LOG_FILENAME;
这种方式,变量的空间只会被分配一次,另一个优势:在头文件中隐藏实际的常量值。
更好的办法:在类中声明常量,并将其声明为静态const -----静态 内存中只有一份。
// myapi.h
class MyAPI
{
public:
static const int MAX_NAME_LENGTH;
static const std::string LOG_FILENAME;
};
// myapi.cpp 定义常量值
const int MyAPI::MAX_NAME_LENGTH = 128;
const std::string MyAPI::LOG_FILENAME = "filename.log";

constexpr关键字:用来标识已知为恒定不变的函数或变量,以便编译器执行更好的优化
int GetSize(int elems){return elems*2;}
double myTable[GetSize(2)]; // 在 C++ 98 非法
////////
constexpr int GetSize(int elems){return elems*2;}
double myTable[GetSize(2)]; // 在 C++ 0x 合法
能够标识函数结果是编译时常量 ,所有我们可以通过函数调用定义常量。
4.初始化列表
构造函数初始化列表,相比在构造函数中初始化每个成员变量,性能有提升。
在构造函数中 初始化 成员变量:会先调用成员变量的默认构造函数,用于初始化 成员变量,然后再构造函数内部调用 赋值操作符。
初始化列表:只调用了复制构造函数。可以避免列表中每个成员变量调用默认构造函数的开销。
初始化列表注意事项:
1.初始化列表中的变量顺序必须与类中指定的顺序一致
2.不能在初始化列表指定数组,但可以指定std::vector
3.如果声明的是派生类,每个基类的默认构造函数 都会被隐式调用。也可以使用初始化列表调用非默认构造函数。
4.如果成员变量声明为引用或const,必须通过初始化列表来初始化他们,从而避免有默认构造函数定义其初始值
5.内存优化
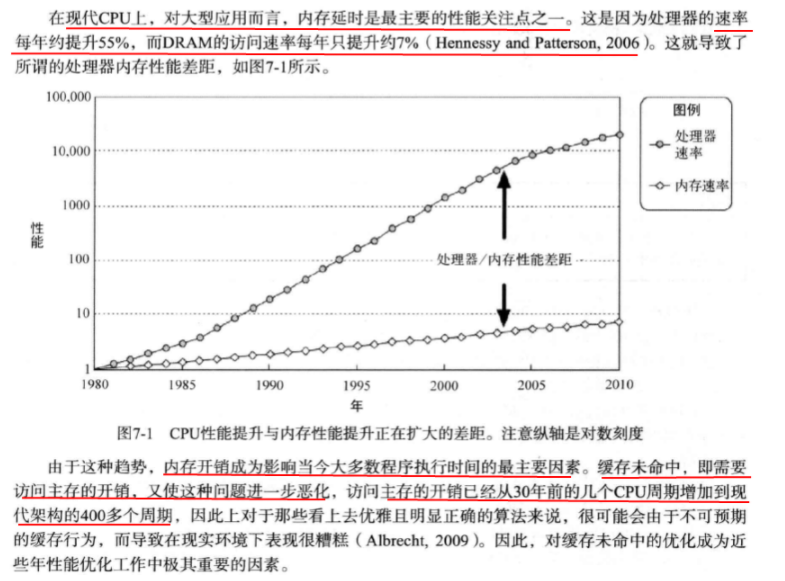
提升数据缓存效率:
重要技巧:缩小对象的大小,对象越小,越适合缓存。
1.根据类型聚集成员变量:C++编译器会对齐某些数据成员,使他们的内存 地址落在字长边界。会有一些无用的填充字节会被添加到数据结构中。
通过聚集所有相同类型的成员变量,使其紧密相连,可以最小化这些填充字节导致的内存损失。
2.使用位域 :指定 变量所占 位数。压缩空间
struct CHAR
{
unsigned int ch : 8; //8位
unsigned int font : 6; //6位
unsigned int size : 18; //18位
};
struct CHAR ch1;
3.使用联合:联合是数据成员共享相同内存空间的一种结构。支持将多个绝不会同时使用的值共享相同的内存区域,从而揭示内存空间。分配给一个union对象的存储空间至少要能容纳它的最大数据成员。
4.除非必要,不要添加虚方法。一旦给类添加虚方法,类需要维护一个虚表。每个对象 都会存储 一个指向虚表的指针。对象总体上增加了 一个指针的开销
C++虚函数表,虚表指针,内存分布:https://blog.csdn.net/li1914309758/article/details/79916414
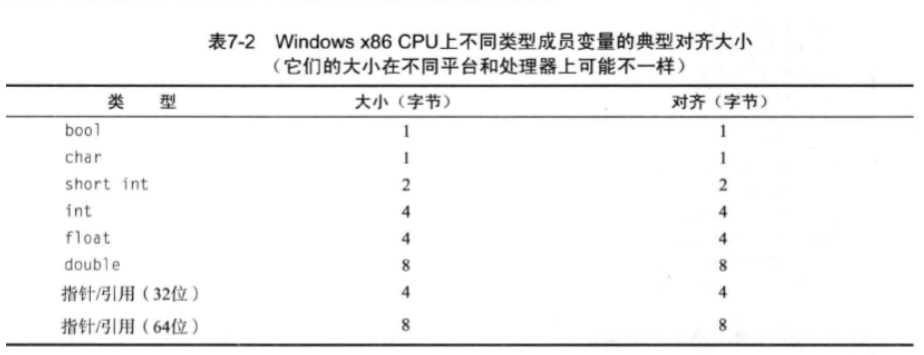
5.使用大小明确的类型。很多类型的大小会随着平台、编译器,机器字长(32bit、64bit)的不同而不同。不要认为bool、short和int是特定大小。
如int8_t、uint32_t、int64_t 等等
例子 在32机器上:

大小 48字节
聚集处理:

减少到32字节,减少量为33%
使用位域:
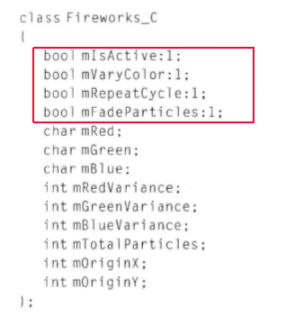
降低到28字节,即42%的减少量
明确大小:

降低到 16字节
四种写法内存分布图:

6.内联的使用
缺点:

使用建议:
适用于短小、简单、频繁调用的函数

7.写时复制
目的:节省内存,允许所有客户共享一份唯一的资源,知道他们中的一个需要修改这份资源为止。只有这个时间点 采用构造副本。
实现方法:共享指针

