
信息量、信息熵、相对熵,交叉熵 简单理解
信息量:
假设X是一个离散型随机变量,其取值集合为X,概率分布函数为p(x)=Pr(X=x),x∈X,我们定义事件X=x0的信息量为: I(x0)=−log(p(x0)),可以理解为,一个事件发生的概率越大,则它所携带的信息量就越小,而当p(x0)=1时,熵将等于0,也就是说该事件的发生不会导致任何信息量的增加。
事件A:小明考试及格,对应的概率P(xA)=0.1,信息量为I(xA)=−log(0.1)=3.3219
事件B:小王考试及格,对应的概率P(xB)=0.999,信息量为I(xB)=−log(0.999)=0.0014
也就是说,一件事发生不出所料,那么它的发生多我们来说没有任何惊喜,没有新的信息。当一件不太可能的事发生,出乎意料,我们大概率会去仔细看看,所能获得的信息也就很多了。
一个具体事件的信息量应该是随着其发生概率而递减的,且不能为负。随着概率增大而减少的函数形式太多了,为什么是log呢,log计算性质:2lg3+3lg2=lg3^2+lg2^3=lg9+lg8=lg(9x8)=lg72.(对数的系数写成真数的指数,再根据对数运算的法则,对数相加,底数不变,真数相乘)
如果我们有俩个不相关的事件x和y,那么我们观察到的俩个事件同时发生时获得的信息应该等于观察到的事件各自发生时获得的信息之和,即:
h(x,y) = h(x) + h(y)
由于x,y是俩个不相关的事件,那么满足p(x,y) = p(x)*p(y).
根据上面推导,我们很容易看出h(x)一定与p(x)的对数有关(因为只有对数形式的真数相乘之后,能够对应对数的相加形式)。因此我们有信息量公式如下:
(1)为什么有一个负号
其中,负号是为了确保信息一定是正数或者是0,总不能为负数吧!
还有一个理解就是信息量取概率的负对数,其实是因为信息量的定义是概率的倒数的对数。用概率的倒数,是为了使概率越大,信息量越小,同时因为概率的倒数大于1,其对数自然大于0了。
(2)为什么底数为2
这是因为,我们只需要信息量满足低概率事件x对应于高的信息量。那么对数的选择是任意的。我们只是遵循信息论的普遍传统,使用2作为对数的底!
信息熵:
信息量度量的是一个具体事件发生了所带来的信息,而熵则是在结果出来之前对可能产生的信息量的期望——考虑该随机变量的所有可能取值,即所有可能发生事件所带来的信息量的期望。即
从信息传播的角度来看,信息熵可以表示信息的价值。为了求得信息的价值,我们通过求信息期望的方式,来求得信息熵。公式如下:

也就是说H(x) = E[I(xi)] = E[ log(1/p(xi)) ] = -∑p(xi)log(p(xi)) 其中,x表示随机变量,与之相对应的是所有可能输出的集合,定义为符号集,随机变量的输出用x表示。P(x)表示输出概率函数。变量的不确定性越大,熵也就越大,把它搞清楚所需要的信息量也就越大。为了保证有效性,这里约定当p(x)→0时,有p(x)logp(x)→0
当X为0-1分布时,熵与概率p的关系如下图:

当两种取值的可能性相等时,不确定度最大(此时没有任何先验知识),这个结论可以推广到多种取值的情况。在图中也可以看出,当p=0或1时,熵为0,即此时X完全确定。 熵的单位随着公式中log运算的底数而变化,当底数为2时,单位为“比特”(bit),底数为e时,单位为“奈特”。
还有一个对信息熵的理解。信息熵还可以作为一个系统复杂程度的度量,如果系统越复杂,出现不同情况的种类越多,那么他的信息熵是比较大的。
如果一个系统越简单,出现情况种类很少(极端情况为1种情况,那么对应概率为1,那么对应的信息熵为0),此时的信息熵较小。
相对熵
又称KL散度( Kullback–Leibler divergence),是描述两个概率分布P和Q差异的一种方法。它是非对称的,这意味着D(P||Q) ≠ D(Q||P)。
特别的,在信息论中,D(P||Q)表示当用概率分布Q来拟合真实分布P时,产生的信息损耗,其中P表示真实分布,Q表示P的拟合分布。有人将KL散度称为KL距离,但事实上,KL散度并不满足距离的概念,因为:(1)KL散度不是对称的;(2)KL散度不满足三角不等式。
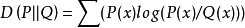

显然,当p=q 时,两者之间的相对熵DKL(p||q)=0 。上式最后的Hp(q)表示在p分布下,使用q进行编码需要的bit数,而H(p)表示对真实分布p所需要的最小编码bit数。基于此,相对熵的意义就很明确了:DKL(p||q)表示在真实分布为p的前提下,使用q分布进行编码相对于使用真实分布p进行编码(即最优编码)所多出来的bit数。并且为了保证连续性,做如下约定:

对于两个概率分布和
,其相对熵的计算公式为:
上式的前半部分 就是交叉熵(cross entropy)。
若 是数据的真实概率分布,
是由数据计算得到的概率分布。机器学习的目的就是希望
尽可能地逼近甚至等于
,从而使得相对熵接近最小值0. 由于真实的概率分布是固定的,相对熵公式的后半部分
就成了一个常数。那么相对熵达到最小值的时候,也意味着交叉熵达到了最小值。对
的优化就等效于求交叉熵的最小值。另外,对交叉熵求最小值,也等效于求最大似然估计(maximum likelihood estimation)
【交叉熵】
交叉熵是表示两个概率分布p,q,其中p表示真实分布,q表示非真实分布,在相同的一组事件中,其中,用非真实分布q来表示某个事件发生所需要的平均比特数。从这个定义中,我们很难理解交叉熵的定义。
假设现在有一个样本集中两个概率分布p,q,其中p为真实分布,q为非真实分布。假如,按照真实分布p来衡量识别一个样本所需要的编码长度的期望为:
H(p)=
但是,如果非真实分布q来表示来自真实分布p的平均编码长度,则应该是:
H(p,q)=
此时就将H(p,q)称之为交叉熵。交叉熵的计算方式如下:
CEH(p,q)= 


对所有训练样本取均值得:

三者相对关系理解:
1)信息熵:编码方案完美时,最短平均编码长度的是多少。
2)交叉熵:编码方案不一定完美时(由于对概率分布的估计不一定正确),平均编码长度的是多少。
平均编码长度 = 最短平均编码长度 + 一个增量 (上文理解中的是减法)
3)相对熵:编码方案不一定完美时,平均编码长度相对于最小值的增加值。(即上面那个增量)
参考:
https://www.zhihu.com/question/41252833/answer/141598211
https://www.cnblogs.com/raorao1994/p/8872073.html
https://zhuanlan.zhihu.com/p/26486223


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 一个费力不讨好的项目,让我损失了近一半的绩效!
· 清华大学推出第四讲使用 DeepSeek + DeepResearch 让科研像聊天一样简单!
· 实操Deepseek接入个人知识库
· CSnakes vs Python.NET:高效嵌入与灵活互通的跨语言方案对比
· Plotly.NET 一个为 .NET 打造的强大开源交互式图表库