

| 这个作业属于哪个课程 | 软件四班> |
|---|---|
| 这个作业要求在哪里 | 编程作业 |
| 这个作业的目标 | 完成项目 |
| 学号 | 20188504 |
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 20 | 20 |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 40 | 60 |
| • Design Spec | • 生成设计文档 | 30 | 30 |
| • Design Review | • 设计复审 | 20 | 30 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| • Design | • 具体设计 | 20 | 20 |
| • Coding | • 具体编码 | 600 | 720 |
| • Code Review | • 代码复审 | 20 | 30 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 20 | 60 |
| Reporting | 报告 | ||
| • Test Repor | • 测试报告 | 10 | 20 |
| • Size Measurement | • 计算工作量 | 10 | 15 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 15 | 30 |
| 合计 | 825 | 1055 |
解题思路
第一遍看完题目,我首先想到的是对单词的判定,以及如何编写代码可以提升自己程序的性能。在充分理解完需求之后,我决定按三个核心模块来重新分析需求。
1、统计字符数
由于助教已经确认过不会出现ACSII范围外的字符,且需求是除了英文、数字外,空格、制表符和换行符都算作字符,所以我的思路是在读取文件后直接遍历文件获取字符数。
2、统计单词数
需求是至少以4个英文字母开头,以分隔符分割,其中除英文字母和数字外的任意字符均算作分隔符,其中单词不区分大小写。
我的思路是在遍历文件的同时,维护一个单词标记位,当标记位满足要求时,将其判定为单词。
3、统计最多的10个单词及词频
我对统计词频的思路就是维护一个以单词为key、出现次数为value的map,同时这个map需要按value降序排序,当value相同时,按key的字典序排序。
设计与实现
类设计
public class Lib{ public static int lineNum; //文件工具类,用于读取文件和写入文件 public static class FileUtil{...} //统计字符数,返回long public static long countChars(String inputPath); //统计单词数 public static long countWords(String inputPath); //统计词频,返回string public static String countWordFrequency(String inputPath); //统计每行单词,返回map private static Hashtable<String,Long> countLineWords (String line,Hashtable<String,Long> mapWord,boolean countWords); //map排序,将值按升序排序,当值相同时键按字典序排序 返回map private static Map<String, Long> sortWord(Map<String,Long> map); //遍历文件统计单词 private static Hashtable<String,Long> countWordsTable (BufferedReader tempReader,boolean countLine); }
I/O设计
选用BufferedReader,最初的想法是用BufferedReader的readLine()方法处理文件每行的字符串,用每行字符串的长度来统计字符数,但发现在统计字符时readLine()方法无法统计到换行时的换行符号,后来又发现用read()方法读取每个字符可以读到换行符,所以统计字符模块使用read()方法,统计单词数和词频模块使用readLine()方法。
性能改进
改进思路
我认为可以从以下几个方面改进程序的性能。
I/O方面
读取文件采用了带缓存的BufferedReader,减少了I/O操作。
判断单词
我的程序采用的方式是用BufferedReader一次读取一行,每行独立判断单词的数量、出现频率等。在与同学交流之后我发现还可以采用按分割符分割字符串,后再单独进行判定单词的方式,可以进一步提高性能。但因为我已经在测试阶段,所以没有修改我的程序。
词频的输出
由于我是按map来存单词的出现次数的,所以需要单独对整个存单词的map进行一次按value排序,在参考了其博客后,选择用流式编程来排序。
三个模块多线程运行
我让三个模块开三个线程同时处理文件,而不是等一个模块处理完后轮到下一个模块处理,该方法极大得缩短了处理时间,但缺点是运行时可能会造成内存占用过高的问题。
程序测试
覆盖率
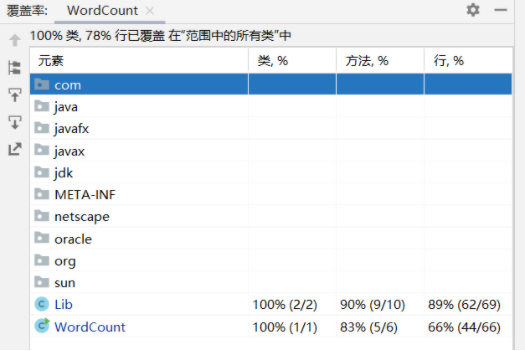
异常处理说明
程序的异常基本上是文件处理异常,如果找不到输入文件、输出文件错误等等。
当输入文件错误时,抛出找不到文件异常。

心路历程与收获
通过这一次的作业,我更加的认识到了自己的不足,许多地方都搞不明白,还需更加努力。

