

Python Scrapy 框架
- Python 爬虫框架介绍
- Windows 下安装 Scrapy
- Linux 下安装 Scrapy
- Scrapy 目录结构
- Scrapy 常用命令
- Scrapy 编写 Items
- Scrapy 编写 Spider
- Scrapy 类参数传递
1. 爬虫框架介绍
什么是爬虫框架:在前面的学习中,我们的爬虫项目都是一步一步手动写出来的,相对来说会慢一些,如果有一套开发相对完备的框架,那么写少量代码就是可以实现一样的功能。Python的爬虫框架就是一些爬虫项目的半成品。比如可以将一些常见爬虫功能的实现代码部分写好,然后留下一些接口,在做不同的爬虫项目时,我们只需要根据实际情况,编写少量需要变动的代码部分,并按照需求调用这些接口,即可以实现一个爬虫项目。
使用 Python 开发的常见的爬虫框架:
(1) Scrapy 框架:一套比较成熟的 Python 开源爬虫框架,可以应用于网络爬虫开发 、数据挖掘 、数据监测 、自动化测试等
(2) Crawley 框架:致力于使用多种方式从互联网中提取数据的爬虫框架,可以将数据存储到各种数据库,可以将数据导出为 Json 、XML格式
(3) Portia 框架:是一款允许没有任何编程基础的用户可视化地爬取网页的爬虫框架
(4) newspaper 框架:一套用来提取新闻 、文章以及内容分析的 Python 爬虫框架,比较简洁
(5) Python-goose 框架:致力于提取文章内容的一套框架,Goose 是用 Java 编写的,后来被人 Python 重写了,重命名为 Python-goose
2. Windows 下安装 Scrapy
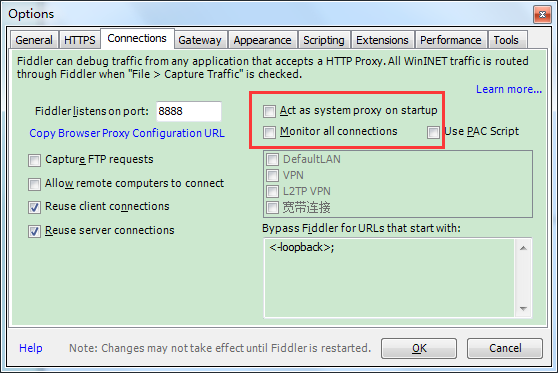
由于之前在 Windows 中安装了 Fiddler,客户端默认使用 Fiddler 作为代理服务器,为了避免对 Scrapy 的影响,我们需要取消一些配置
打开 Fiddler --- Tools --- Options --- Connections --- 如下,取消勾选 --- 最后重启 Fiddler
Windows 上打开命令行窗口,使用 pip 来安装 Scrapy,确保安装了 Python3 和 pip:
C:\Users\Administrator> pip install scrapy
安装过程出现如下错误,提醒我们没有安装 Visual Studio,下载地址:https://visualstudio.microsoft.com/downloads/
error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools": https://visualstudio.microsoft.com/downloads/
安装 Visual Studio 过程中如果出现如下错误,去 http://www.onlinedown.net/soft/120082.htm 下载 DirectX 修复一下
3. Linux 下安装 Scrapy
确保系统安装了 Python3 和 pip3,我们使用 pip3 来安装 Scrapy:
[root@localhost ~]$ yum install -y python36
[root@localhost ~]$ yum install -y python36-pip
[root@localhost ~]$ yum install -y python36-devel
[root@localhost ~]$ pip3.6 install scrapy
4. Scrapy 目录结构
[root@localhost ~]$ scrapy startproject myScrapy //创建一个爬虫项目
[root@localhost ~]$ tree myScrapy/ myScrapy/ ├── myScrapy //项目核心目录 │ ├── __init__.py //初始化文件 │ ├── items.py //主要用来存储我们要爬取的目标数据,比如我要爬取图片、文本、链接等都可以在这里定义 │ ├── middlewares.py //中间件,使用中间件可以在爬虫的请求发起之前或者请求返回之后对数据进行修改 │ ├── pipelines.py //爬虫项目的管道文件,主要用来对items里面定义的数据进一步加工处理,比如将爬取结果加工处理后存放到数据库 │ ├── __pycache__ //缓存文件 │ ├── settings.py //爬虫项目的设置文件 │ └── spiders //存放爬虫文件的目录,爬虫文件里面是一个类,它定义了怎样爬取一个网站, 包括怎样去跟踪连接、提取数据 │ ├── __init__.py //初始化文件 │ └── __pycache__ //缓存文件 └── scrapy.cfg //爬虫项目的全局配置文件
5. Scrapy 常用命令
[root@localhost myScrapy]$ scrapy -h Scrapy 1.6.0 - project: myScrapy Usage: scrapy <command> [options] [args] Available commands: bench 用于测试服务器硬件性能,也就是测试每分钟能爬取多少个网页 check 用于对某个爬虫文件进行检查,用法:scrapy check <spider_name> crawl 用于直接运行一个爬虫文件,用法:scrapy crawl <spider_name> edit 用于编辑指定的爬虫文件,可以先用 scrapy list 列出可以使用的爬虫文件 fetch 主要用来显示爬虫爬取的过程,如 scrapy fetch http://www.baidu.com/ genspider 可以基于现有的爬虫模板生成一个新的爬虫文件,可以用 scrapy genspider -l 列出可用的模板
用法:scrapy genspider -t basic s1 baidu.com
解释:-t 用于指定模板名,basic 是基础模板,s1 指定要生成的爬虫文件名,最后加上要爬取的域名,注意不能写成 http://www.baidu.com list 可以列出当前爬虫项目下可以使用的爬虫文件 parse 可以实现获取指定的URL地址,并使用对应的爬虫文件进行处理和分析 runspider 直接运行一个自定义的爬虫文件,而不需要创建爬虫项目,如 scrapy runspider myscrapy.py settings 用于获取爬虫项目的settings.py文件的值,如 scrapy settings --get BOT_NAME shell 启动Scrapy的交互终端,通常在开发或调试的时候使用,如 scrapy shell http://www.baidu.com/ startproject 用于创建一个爬虫项目,如 scrapy startproject myScrapy version 用于查看Scrapy版本信息,如 scrapy version -v view 用于下载指定的URL网页,并自动打开浏览器查看,不过只能用在Windows系统,如 scrapy view http://www.baidu.com Use "scrapy <command> -h" to see more info about a command
6. Scrapy 编写 Items
items主要用来存储我们要爬取的目标数据,定义格式如下,只需要将 scrapy 下的 Field 类实例化即可,类似于 Django 中的数据模型:
[root@localhost myScrapy]$ cat myScrapy/items.py # -*- coding: utf-8 -*- import scrapy class MyscrapyItem(scrapy.Item): userid = scrapy.Field() username = scrapy.Field() password = scrapy.Field()
我们可以使用 python shell 来模拟如何存储数据:
In [1]: import scrapy In [2]: class UserInfo(scrapy.Item): //先定义格式,需要先继承scrapy.Item类,在该类中可以定义要存储的结构化数据 ...: userid = scrapy.Field() ...: username = scrapy.Field() ...: password = scrapy.Field() ...: In [3]: info = UserInfo(userid=1, username="Tom", password="123456") //要存储数据时,只需要实例化该类即可 In [4]: info['userid'] //查看数据 Out[4]: 1 In [5]: info['userid'] = 2 //修改数据 In [6]: info.keys() //查看所有keys Out[6]: dict_keys(['userid', 'username', 'password']) In [7]: info.items() //查看所有items Out[7]: ItemsView({'password': '123456', 'userid': 2, 'username': 'Tom'})
7. Scrapy 编写 Spider
Spider 也就是具体的爬虫文件,爬虫文件定义了怎样爬取一个网站, 包括怎样去跟踪连接、提取数据,格式如下:
[root@localhost myScrapy]$ cat myScrapy/items.py //编写Spider前先定义好items,这里我们定义一个title字段来存储数据 # -*- coding: utf-8 -*- import scrapy class MyscrapyItem(scrapy.Item): title = scrapy.Field()
[root@localhost myScrapy]$ cat myScrapy/spiders/s1.py //爬虫文件 # -*- coding: utf-8 -*- import scrapy from myScrapy.items import MyscrapyItem //导入items,格式:from 项目名.itmes import item类名 class S1Spider(scrapy.Spider): //创建一个爬虫类,该类继承了scrapy.Spider类,所以爬虫类都必须继承这个基类 name = 's1' //定义爬虫名称,运行爬虫文件的时候需要使用到这个名称 allowed_domains = ['sina.com.cn'] //定义允许爬取的域名,非允许的域名会自动过滤掉,注意只写域名,不要写上http协议和主机名 start_urls = [ //定义要爬取的网页,如果有多个可以用逗号隔开,这里我爬取三个新闻页 'http://astro.sina.com.cn/e/2019-03-07/doc-ihsxncvh0646848.shtml', 'https://news.sina.com.cn/s/2019-03-10/doc-ihsxncvh1275502.shtml', 'http://fashion.sina.com.cn/l/wa/2019-03-10/0006/doc-ihsxncvh0921919.shtml', ] def parse(self, response): //定义回调函数,该方法可以对爬虫爬取完之后响应的内容进行修改,如下我们把<title>标签下的内容提取出来 item = MyscrapyItem() //实例化items item["title"] = response.xpath("/html/head/title/text()") //把<title>标签下的内容提取出来并存储到title字段中 print(item["title"]) //查看存储内容
其他可用的方法:
__init__() //主要负责爬虫的初始化,为构造函数 closed(reason) //关闭Spider时,该方法会被调用 start_requests() //该方法默认读取start_urls属性,为每一个网址生成一个Request请求对象,并返回可迭代对象 make_requests_from_url(url) //该方法会被start_requests()调用,负责实现生成Request对象 log(message[,level,component]) //该方法可以实现在Spider中添加log
定义好爬虫文件之后就可以运行了:
[root@localhost myScrapy]$ scrapy crawl s1 --nolog //s1表示爬虫名称,在爬虫文件的name属性中定义 [<Selector xpath='/html/head/title/text()' data='天外来客 欢迎流浪到地球|陨石|腕表|机芯_新浪时尚_新浪网'>] [<Selector xpath='/html/head/title/text()' data='二月二龙抬头开运祈福习俗(组图)|周易|二月二|龙抬头_新浪星座_新浪网'>] [<Selector xpath='/html/head/title/text()' data='中国炒房团不见了?这国27年“经济神话”恐将破灭|澳大利亚|悉尼|炒房团_新浪新'>]
扩展内容:XPath
(1) 我们手写网络爬虫的时候,通常使用正则表达式对爬取到的数据进行筛选和提取,而在 Scrapy 框架中,则使用 XPath 表达式进行数据的筛选和提取
(2) 在 XPath 表达式中,使用 "/" 可以选择某个标签,如下,如果我们要提取出 <h2></h2>标签对应的内容,使用 XPath 表达式写成:/html/body/h2/text()
(3) 在 XPath 表达式中,使用 "//" 可以提取某个标签的所有内容,如 //p 表示提取所有 <p></p>标签的内容,//img[@class="f1"] 表示提取 class 值为 f1 的 <img> 标签的内容
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>首页</title> </head> <body> <p>床前明月光</p> <p>疑是地上霜</p> <h2>举头望明月</h2> <h2>低头思故乡</h2> </body> </html>
8. Spider 类参数传递
上面我们写爬虫文件都是在类中定义好了要爬取的网址,如果我们想通过命令行的方式把要爬取的网址当做参数传递进去,可以通过重写 __init__() 来实现:
[root@localhost myScrapy]# cat myScrapy/spiders/s1.py # -*- coding: utf-8 -*- import scrapy from myScrapy.items import MyscrapyItem class S1Spider(scrapy.Spider): name = 's1' start_urls = [ 'http://astro.sina.com.cn/e/2019-03-07/doc-ihsxncvh0646848.shtml', 'https://news.sina.com.cn/s/2019-03-10/doc-ihsxncvh1275502.shtml', 'http://fashion.sina.com.cn/l/wa/2019-03-10/0006/doc-ihsxncvh0921919.shtml', ] def __init__(self, url=None, *args, **kwargs): super(S1Spider, self).__init__(*args, **kwargs) self.start_urls = ["%s" % url] def parse(self, response): item = MyscrapyItem() item["title"] = response.xpath("/html/head/title/text()") print(item["title"])
[root@localhost myScrapy]# scrapy crawl s1 -a url="http://astro.sina.com.cn/e/2019-03-07/doc-ihsxncvh0646848.shtml" --nolog //执行爬虫文件时使用-a来传递参数 [<Selector xpath='/html/head/title/text()' data='二月二龙抬头开运祈福习俗(组图)|周易|二月二|龙抬头_新浪星座_新浪网'>]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号