ISO-8859-1, ASCII, GB 2312, Unicode字符集解析
在编程方面经常遇到字符编码的问题,由于对字符集没有一个系统的认识,总是被乱码搞得一头雾水,这篇博文则是对字符编码方面的进行了一下整理,以便日后复习。在学习字符集的过程中,我主要从字符集的(a)编码方式,(b)占用字节,两个方面来进行分析的。
ISO-8859-1/ASCII
参考资料:ISO-8859-1
ISO-8859-1(Latin1)编码是单字节编码,向下兼容ASCII,其编码范围是0x00-0xFF,0x00-0x7F之间完全和ASCII一致,0x80-0x9F之间是控制字符,0xA0-0xFF之间是文字符号。因为ISO-8859-1编码范围使用了单字节内的所有空间,在支持ISO-8859-1的系统中传输和存储其他任何编码的字节流都不会被抛弃。换言之,把其他任何编码的字节流当作ISO-8859-1编码看待都没有问题。下图为ISO-8859-1字符集(包括ASCII字符集,图片来自百科)的编码表,编码方式

在下面代码中,字符串str"úù§ABD"的前三个字符由于不在ASCII编码范围内,故变量asc不能还原为源字符串。由byte数组的长度来看,ISO-8859-1和ASCII为单字节编码。
1 public static void iso(){ 2 String str = "úù§ABD"; 3 try { 4 byte[] ch = str.getBytes("ISO-8859-1"); 5 String asc = new String(ch, "ASCII"); 6 String iso = new String(ch, "ISO-8859-1"); 7 System.out.println(str+" length:"+ch.length+" bytecode:"+byte2hex(ch)+"\nASCII:"+asc +"\nISO-8859-1:"+iso); 8 } catch (UnsupportedEncodingException e) { 9 // TODO Auto-generated catch block 10 e.printStackTrace(); 11 } 12 }
OUTPUT:
úù§ABD length:6 bytecode: fa f9 a7 41 42 44
ASCII:???ABD
ISO-8859-1:úù§ABD
GBK/GB2312
GBK全称《汉字内码扩展规范》,GBK编码,是在GB2312-80标准基础上的内码扩展规范,使用了双字节编码方案,其编码范围从8140至FEFE(剔除xx7F),共23940个码位,共收录了21003个汉字。GBK为对GB2312的一次扩充,其高位字节不再要求区号加0xA0,低位字节甚至不要求首位bit为1,这样大大扩充了GB2312的可编码范围。
1 public static void gb(){ 2 String str = "啊aA"; 3 byte[] ch; 4 try { 5 ch = str.getBytes("GB2312"); 6 System.out.println("ch length:"+ch.length+" bytecode:"+byte2hex(ch)); 7 ch = str.getBytes("GBK"); 8 System.out.println("ch length:"+ch.length+" bytecode:"+byte2hex(ch)); 9 } catch (UnsupportedEncodingException e) { 10 // TODO Auto-generated catch block 11 e.printStackTrace(); 12 } 13 }
OUTPUT:
ch length:4 bytecode: b0 a1 61 41
ch length:4 bytecode: b0 a1 61 41
从程序可以看出GB2312,GBK是不定长的,汉字为2个字节,英文字符为一个字节。由于表示汉字或图形符号的“高位字节”的首个bit都为1,而ASCII首个bit为0,而实现了这两种字符集对ASCII的兼容。
Unicode/UTF-8/UTF-16/UTF-32
参考资料:Unicode, UTF-8, UTF-16, UTF-32, 通用字符集
Unicode伴随着通用字符集的标准而发展,Unicode至今仍在不断增修,每个新版本都加入更多新的字符。目前最新的版本为2014年6月16日公布的7.0.0。实际应用的Unicode版本对应于UFT-16。Unicode通常会用“U+”然后紧接着4个十六进制的数字来对应一个常用字符,如”U+4EA0“代表某一个字符,若需要表示更多的字符则需要使用五位或六位十六进制数,这是Unicode对字符的表示方式。
UTF(Unicode transfromation format)是Unicode的不同实现,这里的实现指的是字符在计算机中的表示方式。
UTF-8是一种针对Unicode的可变长度字符编码,它可以用来表示Unicode标准中的任何字元,且其编码中的第一个字节仍与ASCII兼容。下图是字符在UTF-8中的编码方式,UTF-8可能使用3、4或更多个字节表示一个字符。
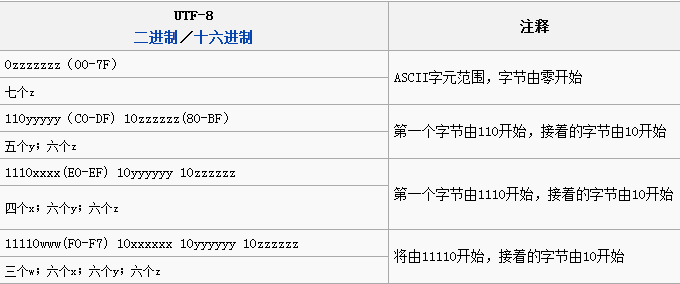
UTF-16使用两个字节表示常用的字符(码位从U+0000至U+FFFF),对于超出U+FFFF外的字符需要4字节表示,这里仅表示大致理解,深入了解请查看维基百科UTF-16。
UTF-32是另一种将Unicode字符编码的协议,对每一个Unicode码位均使用定长的4字节来表示。
1 public static void unicode(){ 2 String str1 = "中文测试"; 3 byte[] ch; 4 try { 5 ch = str1.getBytes("unicode"); 6 System.out.println(str1+" length:"+ch.length+" unicode:"+byte2hex(ch)); 7 ch = str1.getBytes("utf-8"); 8 System.out.println(str1+" length:"+ch.length+" utf-8:"+byte2hex(ch)); 9 ch = str1.getBytes("utf-16"); 10 System.out.println(str1+" length:"+ch.length+" utf-16:"+byte2hex(ch)); 11 ch = str1.getBytes("utf-32"); 12 System.out.println(str1+" length:"+ch.length+" utf-32:"+byte2hex(ch)); 13 str1 = "test"; 14 ch = str1.getBytes("unicode"); 15 System.out.println(str1+" length:"+ch.length+" unicode:"+byte2hex(ch)); 16 ch = str1.getBytes("utf-8"); 17 System.out.println(str1+" length:"+ch.length+" utf-8:"+byte2hex(ch)); 18 ch = str1.getBytes("utf-16"); 19 System.out.println(str1+" length:"+ch.length+" utf-16:"+byte2hex(ch)); 20 ch = str1.getBytes("utf-32"); 21 System.out.println(str1+" length:"+ch.length+" utf-32:"+byte2hex(ch)); 22 } catch (UnsupportedEncodingException e) { 23 // TODO Auto-generated catch block 24 e.printStackTrace(); 25 } 26 }
OUTPUT:
中文测试 length:10 unicode: fe ff 4e 2d 65 87 6d 4b 8b d5
中文测试 length:12 utf-8: e4 b8 ad e6 96 87 e6 b5 8b e8 af 95
中文测试 length:10 utf-16: fe ff 4e 2d 65 87 6d 4b 8b d5
中文测试 length:16 utf-32: 00 00 4e 2d 00 00 65 87 00 00 6d 4b 00 00 8b d5
test length:10 unicode: fe ff 00 74 00 65 00 73 00 74
test length:4 utf-8: 74 65 73 74
test length:10 utf-16: fe ff 00 74 00 65 00 73 00 74
test length:16 utf-32: 00 00 00 74 00 00 00 65 00 00 00 73 00 00 00 74
从实验结果来看,UTF-8使用3个字节表示中文字符,1字节表示英文字符。UTF-32使用4个字节来表示每一种字符。在Unicode和UTF-16用两个字节表示中英文字符,且前端均有一个feff字节,该字节为BOM(Byte Order Mark)表示字节读取顺序。
本文主要记录了作者学习字符集的过程,如有错误,望谅解指正。想要了解下字符集的发展过程,这篇风趣的文章有所介绍:http://blog.csdn.net/aisq2008/article/details/6298170

 浙公网安备 33010602011771号
浙公网安备 33010602011771号