scrapy——3 crawlSpider——爱问
scrapy——3 crawlSpider
crawlSpider
- 爬取一般网站常用的爬虫类。其定义了一些规则(rule)来提供跟进link的方便的机制。
- 也许该spider并不是完全适合您的特定网站或项目,但其对很多情况都使用。因此您可以以其为起点,根据需求修改部分方法。当然您也可以实现自己的spider。

- CrawlSpider使用rules来决定爬虫的爬取规则,并将匹配后的url请求提交给引擎。所以在正常情况下,CrawlSpider不需要单独手动返回请求了。
- 在rules中包含一个或多个Rule对象,每个Rule对爬取网站的动作定义了某种特定操作,比如提取当前相应内容里的特定链接,是否对提取的链接跟进爬取,对提交的请求设置回调函数等。
- 如果多个rule匹配了相同的链接,则根据规则在本集合中被定义的顺序,第一个会被使用。

![]()
- link_extractor:是一个Link Extractor对象,用于定义需要提取的链接。
- callback: 从link_extractor中每获取到链接时,参数所指定的值作为回调函数,该回调函数接受一个response作为其第一个参数。
- 注意:当编写爬虫规则时,避免使用parse作为回调函数。由于CrawlSpider使用parse方法来实现其逻辑,如果覆盖了 parse方法,crawl spider将会运行失败。

- follow:是一个布尔(boolean)值,指定了根据该规则从response提取的链接是否需要跟进。 如果callback为None,follow 默认设置为True ,否则默认为False。
- process_links:指定该spider中哪个的函数将会被调用,从link_extractor中获取到链接列表时将会调用该函数。该方法主要用来过滤。
- process_request:指定该spider中哪个的函数将会被调用, 该规则提取到每个request时都会调用该函数。 (用来过滤request)


实战 爱问网站数据爬取
我们需要用crawlScrapy的规则匹配出每个问题的链接,对连接内的提问标题,和提问人进行爬取,以及匹配下一页的url
前面讲过scrapy shell ,可以在scrapy shell https://iask.sina.com.cn/c/1073.html 中,先进行匹配测试
先在scrapycrawl中导入LineExtractor再匹配,用extract_links(response)取出数据
In [1]: from scrapy.linkextractors import LinkExtractor In [2]: page = LinkExtractor(allow='/c/1073-all-\d+-new\.html').extract_links(response) # 匹配下一页url In [3]: page Out[3]: [Link(url='https://iask.sina.com.cn/c/1073-all-180-new.html', text='2', fragment='', nofollow=False), Link(url='https://iask.sina.com.cn/c/1073-all-191-new.html', text='3', fragment='', nofollow=False), ......... Link(url='https://iask.sina.com.cn/c/1073-all-8608-new.html', text='20', fragment='', nofollow=False), Link(url='https://iask.sina.com.cn/c/1073-all-8618-new.html', text='30', fragment='', nofollow=False)] In [4]: page = LinkExtractor(restrict_xpaths='//li[@class="list"]').extract_links(response) # 要获取标题和提问人,需要先找到这个贴的url In [5]: page Out[5]: [Link(url='https://iask.sina.com.cn/b/1SXKZurG8ST9.html', text='avg说猎杀潜航3主程序是backdoor.seed', fragment='', nofollow=False), Link(url='https://iask.sina.com.cn/b/1SWo9FvedMVJ.html', text='怎么去掉关于应用程序错误的提示???', fragment='', nofollow=False), Link(url='https://iask.sina.com.cn/b/gWP5Ttnm8NDB.html', text='在超声波测距仪的设计中用到了cx20106a,在protel中怎么找不 到啊?', fragment='', nofollow=False), .......... Link(url='https://iask.sina.com.cn/b/87xMZOVEB3Dr.html', text='景德镇哪家公司做网页设计比较靠谱?有电话吗?', fragment='', nofollow=False), Link(url='https://iask.sina.com.cn/b/87L5oCMvbsKB.html', text='景德镇有专业的做网页设计的公司吗?', fragment='', nofollow=False)]
方便看的话还可以用.url提取出url
In [7]: page[0].url Out[7]: 'https://iask.sina.com.cn/b/1SXKZurG8ST9.html' In [8]: page[1].url Out[8]: 'https://iask.sina.com.cn/b/1SWo9FvedMVJ.html' In [9]: page[2].url Out[9]: 'https://iask.sina.com.cn/b/gWP5Ttnm8NDB.html'
随便挑一个url继续scrapy shell url解析我们需要的数据
scrapy shell https://iask.sina.com.cn/b/gWP5Ttnm8NDB.html
In [1]: question = response.xpath('//h2[@class="question-title "]/text()').extract_first() In [2]: question Out[2]: '在超声波测距仪的设计中用到了cx20106a,在protel中怎么找不到啊?' In [3]: ask_people = response.xpath('//span[@class="user-name"]/text()').extract_first() In [4]: ask_people Out[4]: '距离会产生美只有时间不要太长'
准备完毕就可以开始写代码了
- 先创建项目
- 注意:crawl spider 创建项目方法略有不同 Scrapy genspider –t crawl “spider_name”“url”
- IAsk\items.py 确定需要的数据
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html import scrapy class IaskItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() question_title = scrapy.Field() ask_name = scrapy.Field()
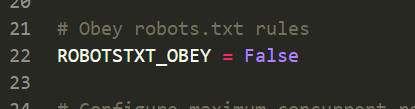
- IAsk\settings.py 激活管道,以及设置忽略爬虫协议(有些网站会设置爬虫协议,礼貌式反爬,可无视)

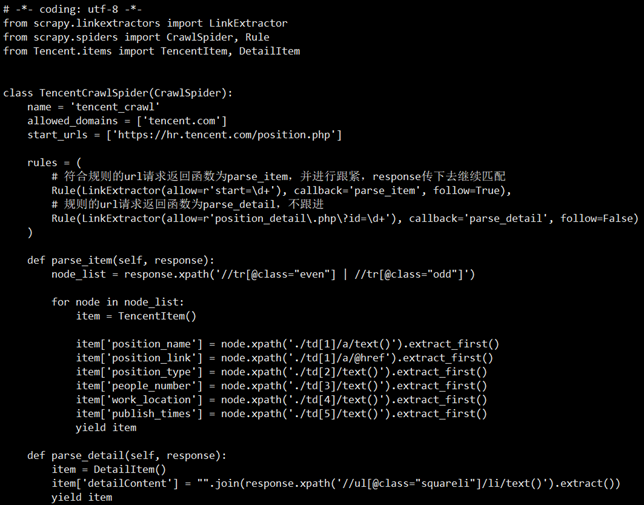
- IAsk\spiders\iask.py 编写代码
# -*- coding: utf-8 -*- import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from ..items import IaskItem class IaskSpider(CrawlSpider): name = 'iask' allowed_domains = ['iask.sina.com.cn'] start_urls = ['https://iask.sina.com.cn/c/1073.html'] rules = ( Rule(LinkExtractor(allow='/c/1073-all-\d+-new\.html'), callback='parse_item', follow=True), # 设置规则匹配下一页url,无需跳转方法,此处只是打印出来看 Rule(LinkExtractor(restrict_xpaths='//li[@class="list"]'), callback='parse_item1', follow=True), # 设置匹配每一个贴的url,再跳转匹配问题和提问人 ) def parse_item(self, response): print(response.url,) def parse_item1(self, response): ask_item = IaskItem() # 创建管道对象 ask_item['question_title'] = response.xpath('//h2[@class="question-title "]/text()').extract_first() ask_item['ask_name'] = response.xpath('//span[@class="user-name"]/text()').extract_first() yield ask_item # 将数据以字典形式传给管道
- IAsk\pipelines.py 在保存数据,json格式
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html import json class IaskPipeline(object): def __init__(self): self.f = open('ask.json', 'w', encoding='utf-8') def start_spider(self): pass def process_item(self, item, spider): s = json.dumps(dict(item), ensure_ascii=False) + '\n' self.f.write(s) return item def close_spider(self): self.f.close()
- 在scrapy——2中,实战介绍的是scrapy spider 的实现方法,点此查看, 这里展示crawl spider的方法,做个对比

 浙公网安备 33010602011771号
浙公网安备 33010602011771号