


8月python岗位跳槽面试记录
其他
🌈MySQL真的就CRUD吗?✨来看看2k和12k之间的差距(上)
💛任职要求中的熟系Redis,你真的熟悉吗?💛
❤Git真的就是Pull和Push吗?❤
Git合并多次提交
8月找新工作所遇到的面试问题
- 其他
- 8月找新工作所遇到的面试问题
- 某公司面试题
- ✅处理上下文管理的
with方法内部实现了哪些方法 - ✅如何实现一个单例模式
- ✅
python中classmethod与staticmethod区别 - ✅为什么会有跨域
- ✅从
http协议角度分析,如何解决跨域问题 - ✅跨域是为了保护客户端还是服务端,为什么?
- ✅协程是如何实现的
- ✅线程和协程的区别是什么
- ✅JWT包含哪些部分和内容
- 🔴 如何编写一个测试用例(
pytest) - ✅设计表时
char和varchar有什么区别 http中有哪些网络安全方面的技术- 是否接触过
webSocket - ✅一个员工和组的多对多关系表,如何设计API实现在一个组中加员工和删员工
- ✅状态码400,401,403分别表示什么意思
- ✅如何用sql写,在a表中只查询一条数据,其中b字段是表中第二大的数据
- ✅如何查看一个日志文件倒数1000行,并且是error状态的数据
- ✅
git merge和git rebase的区别 - ✅
git中commit了一段代码,但是不想提交,又要提交接下来修改的代码,要怎么操作
- ✅处理上下文管理的
- 关于Mysql
✅python描述符
实现了 __get__、__set__ 或__delete__方法的类是描述符。描述符的用法是,创建一个实例,作为另一个类的类属性。
✅使用yeild写一个0~10的生成器
def main():
for i in range(10):
yield i
def main1():
yield from range(10)
✅django和flask的区别
-
Flask
小巧、灵活,让程序员自己决定定制哪些功能,非常适用于小型网站。对于普通的工人来说将毛坯房装修为城市综合体还是很麻烦的,使用Flask来开发大型网站也一样,开发的难度较大,代码架构需要自己设计,开发成本取决于开发者的能力和经验。
-
Django
大而全,功能极其强大,是Python web框架的先驱,用户多,第三方库极其丰富。非常适合企业级网站的开发,但是对于小型的微服务来说,总有“杀鸡焉有宰牛刀”的感觉,体量较大,非常臃肿,定制化程度没有Flask高,也没有Flask那么灵活。
✅django中有哪些中间件
MIDDLEWARE = [
'corsheaders.middleware.CorsMiddleware',
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.common.CommonMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
]
✅django中如何实现一个中间件
中间件 Middleware
-
中间件是 Django 请求/响应处理的钩子框架。它是一个轻量级的、低级的“插件”系统,用于全局改变 Django 的输入或输出。
-
每个中间件组件负责做一些特定的功能。例如,Django 包含一个中间件组件 AuthenticationMiddleware,它使用会话将用户与请求关联起来。
-
中间件类:
中间件类须继承自 django.utils.deprecation.MiddlewareMixin类
-
中间件类须实现下列五个方法中的一个或多个:
- def process_request(self, request):
- 执行路由之前被调用,在每个请求上调用,返回None或HttpResponse对象
- def process_view(self, request, callback, callback_args, callback_kwargs):
- 调用视图之前被调用,在每个请求上调用,返回None或HttpResponse对象
- def process_response(self, request, response):
- 所有响应返回浏览器之前被调用,在每个请求上调用,返回HttpResponse对象
- def process_exception(self, request, exception):
- 当处理过程中抛出异常时调用,返回一个HttpResponse对象
- def process_template_response(self, request, response):
- 在视图刚好执行完毕之后被调用,在每个请求上调用,返回实现了render方法的响应对象
- 注: 中间件中的大多数方法在返回None时表示忽略当前操作进入下一项事件,当返回HttpResponese对象时表示此请求结束,直接返回给客户端
- def process_request(self, request):
编写中间件类:
这是问题的答案,其他只是补充
file : middleware/mymiddleware.py
from django.http import HttpResponse, Http404
from django.utils.deprecation import MiddlewareMixin
class MyMiddleWare(MiddlewareMixin):
def process_request(self, request):
print("中间件方法 process_request 被调用")
def process_view(self, request, callback, callback_args, callback_kwargs):
print("中间件方法 process_view 被调用")
def process_response(self, request, response):
print("中间件方法 process_response 被调用")
return response
def process_exception(self, request, exception):
print("中间件方法 process_exception 被调用")
def process_template_response(self, request, response):
print("中间件方法 process_template_response 被调用")
return response
注册中间件:
file : settings.py
MIDDLEWARE = [
...
]
中间件的执行过程
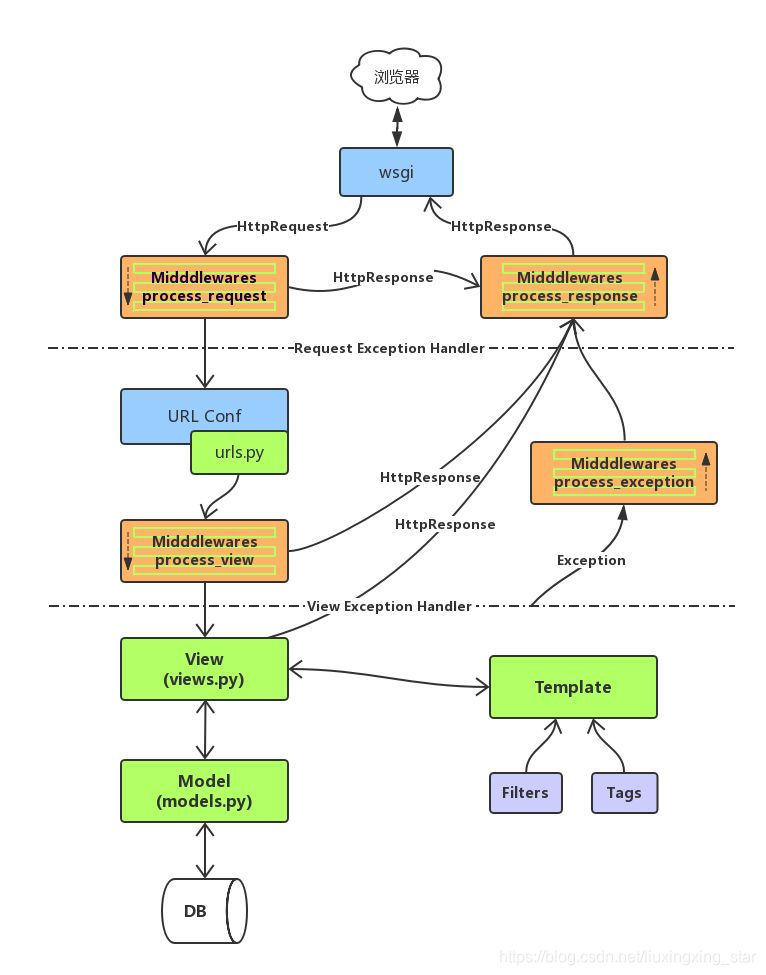
原文链接:https://blog.csdn.net/liuxingxing_star/article/details/104056884
✅mysql如何把一张表复制到另一张表
复制旧表的数据到新表中
CREATE TABLE 新表
SELECT * FROM 旧表
只复制表结构到新表
CREATE TABLE 新表
SELECT * FROM 旧表 WHERE 1 = 2 (让WHERE条件不成立)
复制旧表的数据到新表(假设两个表结构一样)
INSERT INTO 新表
SELECT * FROM 旧表
复制旧表的数据到新表(假设两个表结构不一样)
INSERT INTO 新表(字段1,字段2,…….)
SELECT 字段1,字段2,…… FROM 旧表
✅redis的hash数据结构可不可以嵌套
不可以
补充:
| 类型 | 简介 | 特性 | 场景 |
|---|---|---|---|
| String(字符串) | 二进制安全 | 可以包含任何数据,比如jpg图片或者序列化的对象,一个键最大能存储512M | --- |
| Hash(字典) | 键值对集合,即编程语言中的Map类型 | 适合存储对象,并且可以像数据库中update一个属性一样只修改某一项属性值(Memcached中需要取出整个字符串反序列化成对象修改完再序列化存回去) | 存储、读取、修改用户属性 |
| List(列表) | 链表(双向链表) | 增删快,提供了操作某一段元素的API | 1,最新消息排行等功能(比如朋友圈的时间线) 2,消息队列 |
| Set(集合) | 哈希表实现,元素不重复 | 1、添加、删除,查找的复杂度都是O(1) 2、为集合提供了求交集、并集、差集等操作 | 1、共同好友 2、利用唯一性,统计访问网站的所有独立ip 3、好友推荐时,根据tag求交集,大于某个阈值就可以推荐 |
| Sorted Set(有序集合) | 将Set中的元素增加一个权重参数score,元素按score有序排列 | 数据插入集合时,已经进行天然排序 | 1、排行榜 2、带权重的消息队列 |
String(字符串)
string 是 redis 最基本的类型,你可以理解成与 Memcached 一模一样的类型,一个 key 对应一个 value。
string 类型是二进制安全的。意思是 redis 的 string 可以包含任何数据。比如jpg图片或者序列化的对象。
string 类型是 Redis 最基本的数据类型,string 类型的值最大能存储 512MB。
redis 127.0.0.1:6379> SET runoob "菜鸟教程"
OK
redis 127.0.0.1:6379> GET runoob
"菜鸟教程"
在以上实例中我们使用了 Redis 的 SET 和 GET 命令。键为 runoob,对应的值为 菜鸟教程。
注意:一个键最大能存储 512MB。
Hash(哈希)
Redis hash 是一个键值(key=>value)对集合。
Redis hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象。
redis 127.0.0.1:6379> DEL runoob
redis 127.0.0.1:6379> HMSET runoob field1 "Hello" field2 "World"
"OK"
redis 127.0.0.1:6379> HGET runoob field1
"Hello"
redis 127.0.0.1:6379> HGET runoob field2
"World"
HMGET key field1 field2 field3 ... # 获取多个hash字段值
HGETALL key # 获取某个hash的所有键值
HKEYS key # 查看某个hash的所有键
HVALS key # 查看某个hash的所有值
HLEN key # 查看某个hash的长度
实例中我们使用了 Redis HMSET, HGET 命令,HMSET 设置了两个 field=>value 对, HGET 获取对应 field 对应的 value。
每个 hash 可以存储 232 -1 键值对(40多亿)。
List(列表)
Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。
redis 127.0.0.1:6379> DEL runoob
redis 127.0.0.1:6379> lpush runoob redis
(integer) 1
redis 127.0.0.1:6379> lpush runoob mongodb
(integer) 2
redis 127.0.0.1:6379> lpush runoob rabbitmq
(integer) 3
redis 127.0.0.1:6379> lrange runoob 0 -1
1) "rabbitmq"
2) "mongodb"
3) "redis"
redis 127.0.0.1:6379>
rpush list 1 2 3 4 5 # 右添加
llen list # 返回数量
lindex list 3 # 返回索引3,第四个元素
lpop list # 从左边开始删除一个元素
rpop list # 从右边开始删除一个元素
lrem list 3(个数) 5(元素)
# 表示从上往下(左到右)删除3个‘5’这个元素
# 如果是-3 则表示从下往上(从右向左)删除3个‘5’这个元素
列表最多可存储 232 - 1 元素 (4294967295, 每个列表可存储40多亿)。
Set(集合)
Redis 的 Set 是 string 类型的无序集合。
集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
sadd 命令
添加一个 string 元素到 key 对应的 set 集合中,成功返回 1,如果元素已经在集合中返回 0。
sadd key member
redis 127.0.0.1:6379> DEL runoob
redis 127.0.0.1:6379> sadd runoob redis
(integer) 1
redis 127.0.0.1:6379> sadd runoob mongodb
(integer) 1
redis 127.0.0.1:6379> sadd runoob rabbitmq
(integer) 1
redis 127.0.0.1:6379> sadd runoob rabbitmq
(integer) 0
redis 127.0.0.1:6379> smembers runoob
1) "redis"
2) "rabbitmq"
3) "mongodb"
注意:以上实例中 rabbitmq 添加了两次,但根据集合内元素的唯一性,第二次插入的元素将被忽略。
集合中最大的成员数为 232 - 1(4294967295, 每个集合可存储40多亿个成员)。
sadd set 1 2 3 4 5 6
smembers set
# 1 2 3 4 5 6
srem set 3 # 删除元素
# 还剩 1 2 4 5 6
移动:
sadd set2 3 4 5 6 7 8
smove set set2 1
# set (2 4 5 6)
# set2 (1 3 4 5 6 7 8)
是否存在于集合:
sismember set 5
# 返回1 于 0
交集:
sinter set set2
# 4 5 6
并集:
sunion set set2
# 1 2 3 4 5 6 7 8
差集:
sdiff set2 set
# 1 2 3 7 8
zset(sorted set:有序集合)
Redis zset 和 set 一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
zset的成员是唯一的,但分数(score)却可以重复。
zadd 命令
添加元素到集合,元素在集合中存在则更新对应score
zadd key score member
创建:(有序集合存在一个权重的概念)
zadd zset 1 a 2 b 3 c 4 d 5 e 6 f 7 g
# 输出:
# 1) "a"
# 2) "b"
# 3) "c"
# 4) "d"
# 5) "e"
# 6) "f"
# 7) "g"
# 左边权重,右边元素
查看:
zrange zset 0 -1 # 索引值,第一个和最后一个
倒序查看:
zrevrange zet 0 -1
# 输出:
# 1) "g"
# 2) "f"
# 3) "e"
# 4) "d"
# 5) "c"
# 6) "b"
# 7) "a"
删除:
zrem zset g(元素)
元素值查看查看对应索引值:
zrank zset a # 0(索引值)
倒叙查看元素值相对对索引值;
zrevrank zset a # 6 ('g'之前已被删除)
查看个数:
zcard zset # 6
查看权重:
zscore zset a # 1(权重)
zscore zset f # 6(权重)
返回有序集合中score(权重)在给定区间的元素:
zrangebyscore zset 3 5 withscores # 查看权重在3 和5之间的元素(闭区间)
# 输出:
1) "c"
2) "3"
3) "d"
4) "4"
5) "e"
6) "5"
返回有序集合中score(权重)在给定区间的数量:
zcount zset 3 5 # 权重在3和5之间的元素个数
# 输出: 3
删除有序集合中索引值在给定的区间的元素:
zremrangebyrank zset 3 5 # 删除索引值3到5之间的元素(闭区间)
# 返回数字3 表示d e f 已经被删除了
# 还剩a b c
删除有序集合中权重在给定区间的元素:
zremrangebyscore zset 1 3 # 删除权重在1到3的(闭区间)
# 返回数字3 表示a b c 已经被删除了
# 现有序集合zset为空
✅事务的特性和隔离级别
事务包含4个特性:原子性、一致性、隔离性和持久性
事务的隔离级别:读未提交,读已提交,可重复读,串行化
✅面对一个数据量很大的表,有哪些操作可以提高查找的效率
✅如何实现一个装饰器
装饰器本质上就是实现一个闭包,把一个方法对象当做参数,传入到另一个方法中,然后这个方法返回了一个增强功能的方法对象。
-
装饰不带参数的方法
# coding: utf8 def main(func): def inner(): # do some things func() # do some things return inner @main def test(): pass -
装饰带参数的方法
# coding: utf8 def main(func): def inner(*args, **kwargs): # 参数 # do some things func(*args, **kwargs) # do some things return inner @main def test(): pass -
带参数的装饰器
# coding: utf8 import time from functools import wraps def timeit(prefix): # 装饰器可传入参数 def decorator(func): # 多一层方法嵌套 @wraps(func) def wrapper(*args, **wargs): # do some things func(*args, **wargs) # do some things return wrapper return decorator @timeit('prefix1') def hello(name): pass
✅什么是生成器和迭代器,区别是什么
-
Iterator(迭代器)
迭代器是一个带状态的对象,它能在你调用next()方法时返回容器中的下一个值,任何实现了__iter__()和__next__()(Python2.x中实现next())方法的对象都是迭代器,__iter__()返回迭代器自身,__next__()返回容器中的下一个值,如果容器中没有更多元素了,则抛出StopIteration异常。 -
可以返回一个迭代器的对象都可以称之为可迭代对象
-
Generator(生成器)
生成器其实是一种特殊的迭代器,不过这种迭代器更加优雅,它不需要像普通迭代器一样实现__iter__()和__next__()方法了,只需要一个yield关键字。生成器一定是迭代器(反之不成立),因此任何生成器也是一种懒加载的模式生成值。 -
总结
- 可迭代对象(Iterable)是实现了
__iter__()方法的对象,通过调用iter()方法可以获得一个迭代器(Iterator)。- 迭代器(Iterator)是实现了
__iter__()方法和__next()__方法的对象。for...in...的迭代实际是将可迭代对象转换成迭代器,再重复调用next()方法实现的。- 生成器(Generator)是一个特殊的迭代器,它的实现更简单优雅。
yield是生成器实现__next__()方法的关键。它作为生成器执行的暂停恢复点,可以对yield表达式进行赋值,也可以将yield表达式的值返回。- 生成器一定是迭代器(反之不成立)
✅进程之间是怎么通信的
- 管道
- 消息队列
- 共享内存
- 信号量
- Socket
✅线程之间操作数据怎么保证数据不会串
from threading import Thread, Lock
number = 0
lock = Lock()
def target():
global number
for _ in range(1000000):
with lock:
number += 1
thread_01 = Thread(target=target)
thread_02 = Thread(target=target)
thread_01.start()
thread_02.start()
thread_01.join()
thread_02.join()
print(number)
此时,不管你执行多少遍,输出都是 2000000.
✅浅拷贝和深拷贝的区别
在浅拷贝时,拷贝出来的新对象的地址和原对象是不一样的,但是新对象里面的可变元素(如列表)的地址和原对象里的可变元素的地址是相同的,也就是说浅拷贝它拷贝的是浅层次的数据结构(不可变元素),对象里的可变元素作为深层次的数据结构并没有被拷贝到新地址里面去,而是和原对象里的可变元素指向同一个地址,所以在新对象或原对象里对这个可变元素做修改时,两个对象是同时改变的,但是深拷贝不会这样,这个是浅拷贝相对于深拷贝最根本的区别。
from copy import deepcopy
a = [1, 2, [3, 4], (5, 6)]
b = a.copy()
c = deepcopy(a)
id(a[2]) == id(b[2]) != id(c[2])
✅一个列表,里面全是数量为1的字典,怎么先按照值排序,在按照键排序
d = [
{'a': 1},
{'a': 2},
{'b': 1},
{'b': 23},
{'v': 2},
{'v': 1},
{'y': 32},
{'y': 33}
]
result = sorted(d, key=lambda dd: (list(dd.values())[0], list(dd.keys())[0]))
print(result)
"""
[{'a': 1},
{'b': 1},
{'v': 1},
{'a': 2},
{'v': 2},
{'b': 23},
{'y': 32},
{'y': 33}]
"""
✅关于后端缓存
这么问的内容特别多,学一点是一点吧。
某公司面试题
✅处理上下文管理的with方法内部实现了哪些方法
上下文管理器协议包含__enter__和__exit__两个方法。with 语句 开始运行时,会在上下文管理器对象上调用__enter__方法。with 语 句运行结束后,会在上下文管理器对象上调用 __exit__ 方法,以此扮 演 finally 子句的角色。
调用 __enter__ 方法时,除了隐式的 self 之外,不会传入任何 参数。传给__exit__方法的三个参数列举如下。
-
exc_type
异常类(例如 ZeroDivisionError)。 -
exc_value
异常实例。有时会有参数传给异常构造方法,例如错误消息,这些 参数可以使用 exc_value.args 获取。
-
traceback
traceback 对象
✅如何实现一个单例模式
-
使用函数装饰器实现单例模式
def singleton(cls): _instance = {} def inner(): if cls not in _instance: _instance[cls] = cls() return _instance[cls] return inner @singleton class Cls(object): def __init__(self): pass cls1 = Cls() cls2 = Cls() print(id(cls1) == id(cls2)) # True -
使用类装饰器实现单例模式
class Singleton: def __init__(self, cls): self._cls = cls self._instance = {} def __call__(self): if self._cls not in self._instance: self.instance[self._cls] = self._cls() return self._instance[self._cls] @Singleton class Cls2(object): def __init__(self): pass cls1 = Cls2() cls2 = Cls2() print(id(cls1) == id(cls2)) # True # -------------------------- class Cls3(): pass Cls3 = Singleton(Cls3) cls3 = Cls3() cls4 = Cls3() print(id(cls3) == id(cls4)) # True -
使用 new 关键字实现单例模式
class Single: _instance = None def __new__(cls, *args, **kwargs): if cls._instance is None: cls._instance = super().__new__(cls) return cls._instance def __init__(self): pass s1 = Single() s2 = Single() s3 = Single() s1 == s2 == s3 # True -
使用 metaclass 实现单例模式
首先:
元类(metaclass) 可以通过方法 metaclass 创造了类(class),而类(class)通过方法 new 创造了实例(instance)
同样,我们在类的创建时进行干预,从而达到实现单例的目的。
在实现单例之前,需要了解使用 type 创造类的方法,代码如下:def func(self): print("do sth") Klass = type("Klass", (), {"func": func}) c = Klass() c.func() # do sthclass Single(type): _instance = {} def __call__(cls, *args, **kwargs): if cls not in cls._instance: cls._instance[cls] = super().__call__(*args, **kwargs) return cls._instance[cls] class Cls1(metaclass=Single): pass cls1 = Cls1() cls2 = Cls1() cls1 == cls2 # True
✅python中classmethod与staticmethod区别
-
classmethod与staticmethod的返回值:
>>> class Demo: @classmethod def klassmeth(*args): return args @staticmethod def statmeth(*args): return args >>> Demo.klassmeth() (<class '__main__.Demo'>,) >>> Demo.klassmeth('spam') (<class '__main__.Demo'>, 'spam') >>> Demo.statmeth() () >>> Demo.statmeth('spam') ('spam',) -
classmethod
-
- 定义操作类,而不是 操作实例的方法
- 返回值第一个永远是类本身
-
-
staticmethod
-
- 静态方法就是普通的函数,只是碰巧在类的定义体 中,而不是在模块层定义
- 返回值与普通函数相似
-
-
有一个点是,classmethod可以在调用staticmethod方法:
class Pizza(object): def __init__(self, radius, height): self.radius = radius self.height = height @staticmethod def compute_area(radius): return math.pi * (radius ** 2) @classmethod def compute_volume(cls, height, radius): return height * cls.compute_area(radius) # 再调用静态类方法
✅为什么会有跨域
浏览器从一个域名的网页去请求另一个域名的资源时,域名、端口、协议任一不同,都会出现跨域的问题。
✅从http协议角度分析,如何解决跨域问题
在HTTP请求头中增加一系列HTTP请求参数(例如Access-Control-Allow-Origin等),来限制哪些域的请求和哪些请求类型可以接受。
✅跨域是为了保护客户端还是服务端,为什么?
为了保护客户端
如果没有同源策略,不同源的数据和资源(如HTTP头、Cookie、DOM、localStorage等)就能相互随意访问,根本没有隐私和安全可言。为了安全起见和资源的有效管理,浏览器当然要采用这种策略。
✅协程是如何实现的
字典为动词“to yield”给出了两个释义:产出和让步。对于 Python 生成器 中的 yield 来说,这两个含义都成立。yield item 这行代码会产出一 个值,提供给 next(...) 的调用方;此外,还会作出让步,暂停执行 生成器,让调用方继续工作,直到需要使用另一个值时再调用 next()。调用方会从生成器中拉取值。
从句法上看,协程与生成器类似,都是定义体中包含 yield 关键字的 函数。可是,在协程中,yield 通常出现在表达式的右边(例 如,datum = yield),可以产出值,也可以不产出——如果 yield 关键字后面没有表达式,那么生成器产出 None。协程可能会从调用方 接收数据,不过调用方把数据提供给协程使用的是 .send(datum) 方 法,而不是 next(...) 函数。通常,调用方会把值推送给协程。
yield 关键字甚至还可以不接收或传出数据。不管数据如何流 动,yield 都是一种流程控制工具,使用它可以实现协作式多任务:协程可以把控制器让步给中心调度程序,从而激活其他的协程。
从根本上把 yield 视作控制流程的方式,这样就好理解协程了。
>>> def simle_coroutine(): # 协程使用生成器函数定义:定义体中有 yield 关键字。
print('-> coroutine started')
# yield 在表达式中使用;如果协程只需从客户那里接收数据,那么 产出的值是 None——这个值是隐式指定的,因为 yield 关键字右边没 有表达式。
x=yield
print('-> coroutine received:', x)
>>> my_coro = simple_coroutine()
# 与创建生成器的方式一样,调用函数得到生成器对象。
>>> my_coro
<generator object simple_coroutine at 0x100c2be10>
# 首先要调用 next(...) 函数,因为生成器还没启动,没在 yield 语句处暂停,所以一开始无法发送数据。
>>> next(my_coro)
-> coroutine started
# 调用这个方法后,协程定义体中的 yield 表达式会计算出 42;现在,协程会恢复,一直运行到下一个 yield 表达式,或者终止。
>>> my_coro.send(42)
-> coroutine received: 42
# 这里,控制权流动到协程定义体的末尾,导致生成器像往常一样抛 出 StopIteration 异常。
Traceback (most recent call last):
... StopIteration
✅线程和协程的区别是什么
- 协程,英文Coroutines,是一种比线程更加轻量级的存在
- 由于GIL的存在,导致Python多线程性能甚至比单线程更糟。
- 正如一个进程可以拥有多个线程一样,一个线程也可以拥有多个协程
- 协程的调度完全由用户控制
- 协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快
协程与线程主要区别是它将不再被内核调度,而是交给了程序自己。而线程是将自己交给内核调度;因此,协程的开销远远小于线程的开销。
✅JWT包含哪些部分和内容
JWT是由三段信息构成的,将这三段信息文本用.链接一起就构成了Jwt字符串。就像这样:
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiYWRtaW4iOnRydWV9.TJVA95OrM7E2cBab30RMHrHDcEfxjoYZgeFONFh7HgQ
-
一:header
-
jwt的头部承载两部分信息:
- 声明类型,这里是jwt
- 声明加密的算法 通常直接使用 HMAC SHA256
-
完整的头部就像下面这样的JSON:
{ 'typ': 'JWT', 'alg': 'HS256' } -
然后将头部进行base64加密(该加密是可以对称解密的),构成了第一部分.
eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9
-
-
二:payload
载荷就是存放有效信息的地方。这个名字像是特指飞机上承载的货品,这些有效信息包含三个部分
-
标准中注册的声明(建议但不强制使用)
- iss: jwt签发者
- sub: jwt所面向的用户
- aud: 接收jwt的一方
- exp: jwt的过期时间,这个过期时间必须要大于签发时间
- nbf: 定义在什么时间之前,该jwt都是不可用的.
- iat: jwt的签发时间
- jti: jwt的唯一身份标识,主要用来作为一次性token,从而回避重放攻击。
-
公共的声明
- 公共的声明可以添加任何的信息,一般添加用户的相关信息或其他业务需要的必要信息.但不建议添加敏感信息,因为该部分在客户端可解密.
-
私有的声明
- 私有声明是提供者和消费者所共同定义的声明,一般不建议存放敏感信息,因为base64是对称解密的,意味着该部分信息可以归类为明文信息。
-
定义一个payload
{ "sub": "1234567890", "name": "John Doe", "admin": true } -
然后将其进行base64加密,得到JWT的第二部分。
eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiYWRtaW4iOnRydWV9
-
-
三:signature
-
JWT的第三部分是一个签证信息,这个签证信息由三部分组成:
- header (base64后的)
- payload (base64后的)
- secret
-
这个部分需要base64加密后的header和base64加密后的payload使用
.连接组成的字符串,然后通过header中声明的加密方式进行加盐secret组合加密,然后就构成了jwt的第三部分。// javascript var encodedString = base64UrlEncode(header) + '.' + base64UrlEncode(payload); var signature = HMACSHA256(encodedString, 'secret'); // TJVA95OrM7E2cBab30RMHrHDcEfxjoYZgeFONFh7HgQ将这三部分用
.连接成一个完整的字符串,构成了最终的jwt:eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiYWRtaW4iOnRydWV9.TJVA95OrM7E2cBab30RMHrHDcEfxjoYZgeFONFh7HgQ注意:secret是保存在服务器端的,jwt的签发生成也是在服务器端的,secret就是用来进行jwt的签发和jwt的验证,所以,它就是你服务端的私钥,在任何场景都不应该流露出去。一旦客户端得知这个secret, 那就意味着客户端是可以自我签发jwt了。
-
🔴 如何编写一个测试用例(pytest)
✅设计表时char和varchar有什么区别
- 固定长度 & 可变长度
- VARCHAR类型用于存储
可变长度字符串 - char类型用于存储
固定长度字符串
- VARCHAR类型用于存储
- 存储方式
- VARCHAR节省了存储空间,所以对性能也有帮助。但是,由于行是变长的,在UPDATE时可能使行变得比原来更长,这就导致需要做额外的工作。如果一个行占用的空间增长,并且在页内没有更多的空间可以存储,在这种情况下,不同的存储引擎的处理方式是不一样的。
- CHAR适合存储很短或长度近似的字符串。例如,CHAR非常适合存储密码的MD5值,因为这是一个定长的值。对于经常变更的数据,CHAR也比VARCHAR更好,因为定长的CHAR类型不容易产生碎片。对于非常短的列,CHAR比VARCHAR在存储空间上也更有效率。例如用CHAR(1)来存储只有Y和N的值,如果采用单字节字符集只需要一个字节,但是VARCHAR(1)却需要两个字节,因为还有一个记录长度的额外字节。
- 存储容量
- 对于char类型来说,最多只能存放的字符个数为255,和编码无关,任何编码最大容量都是255。
- MySQL
行默认最大65535字节,是所有列共享(相加)的,所以VARCHAR的最大值受此限制。
http中有哪些网络安全方面的技术
是否接触过webSocket
✅一个员工和组的多对多关系表,如何设计API实现在一个组中加员工和删员工
-
添加员工到组
POST: /v1/api/group/{id}/user/{id} -
删除组中的员工
DELETE: /v1/api/group/{id}/user/{id} -
为某个组新建员工
POST: /v1/api/group/{id}/user
✅状态码400,401,403分别表示什么意思
| 状态码 | 使用场景 |
|---|---|
| 400 bad request | 常用在参数校验 |
| 401 unauthorized | 未经验证的用户,常见于未登录。如果经过验证后依然没权限,应该 403(即 authentication 和 authorization 的区别)。 |
| 403 forbidden | 无权限 |
| 404 not found | 资源不存在 |
| 500 internal server error | 非业务类异常 |
| 503 service unavaliable | 由容器抛出,自己的代码不要抛这个异常 |
✅如何用sql写,在a表中只查询一条数据,其中b字段是表中第二大的数据
select a.b from a order by a.b desc offset 1 limit 1
✅如何查看一个日志文件倒数1000行,并且是error状态的数据
tail -fn 1000 file | grep error
✅git merge和git rebase的区别
git rebase 与 merge 的那些事儿~(详细图解,通俗易懂)
这两种整合方法的最终结果没有任何区别,但是变基使得提交历史更加整洁。 你在查看一个经过变基的分支的历史记录时会发现,尽管实际的开发工作是并行的, 但它们看上去就像是串行的一样,提交历史是一条直线没有分叉。
一般我们这样做的目的是为了确保在向远程分支推送时能保持提交历史的整洁——例如向某个其他人维护的项目贡献代码时。 在这种情况下,你首先在自己的分支里进行开发,当开发完成时你需要先将你的代码变基到 origin/master 上,然后再向主项目提交修改。 这样的话,该项目的维护者就不再需要进行整合工作,只需要快进合并便可。
请注意,无论是通过变基,还是通过三方合并,整合的最终结果所指向的快照始终是一样的,只不过提交历史不同罢了。 变基是将一系列提交按照原有次序依次应用到另一分支上,而合并是把最终结果合在一起。
变基的风险
如果提交存在于你的仓库之外,而别人可能基于这些提交进行开发,那么不要执行变基。
变基 vs. 合并
至此,你已在实战中学习了变基和合并的用法,你一定会想问,到底哪种方式更好。 在回答这个问题之前,让我们退后一步,想讨论一下提交历史到底意味着什么。
有一种观点认为,仓库的提交历史即是 记录实际发生过什么。 它是针对历史的文档,本身就有价值,不能乱改。 从这个角度看来,改变提交历史是一种亵渎,你使用 谎言 掩盖了实际发生过的事情。 如果由合并产生的提交历史是一团糟怎么办? 既然事实就是如此,那么这些痕迹就应该被保留下来,让后人能够查阅。
另一种观点则正好相反,他们认为提交历史是 项目过程中发生的事。 没人会出版一本书的第一版草稿,软件维护手册也是需要反复修订才能方便使用。 持这一观点的人会使用 rebase 及 filter-branch 等工具来编写故事,怎么方便后来的读者就怎么写。
现在,让我们回到之前的问题上来,到底合并还是变基好?希望你能明白,这并没有一个简单的答案。 Git 是一个非常强大的工具,它允许你对提交历史做许多事情,但每个团队、每个项目对此的需求并不相同。 既然你已经分别学习了两者的用法,相信你能够根据实际情况作出明智的选择。
总的原则是,只对尚未推送或分享给别人的本地修改执行变基操作清理历史, 从不对已推送至别处的提交执行变基操作,这样,你才能享受到两种方式带来的便利。
✅git中commit了一段代码,但是不想提交,又要提交接下来修改的代码,要怎么操作
git reset --head <commit id>
git stath
修改接下来的代码
add commit push
git stash pop
继续之前的修改
撤销git add: git reset head filename
撤销commit: git reset --soft head~数字(上个版本就是1,两个就是2,也可以用head,head^)
修改最新的commit内容:git commit --amend -m "new commit message"
合并多个commit为一个commit内容: git rebase -i logid 将多余的设置为squash
关于Mysql
join理论
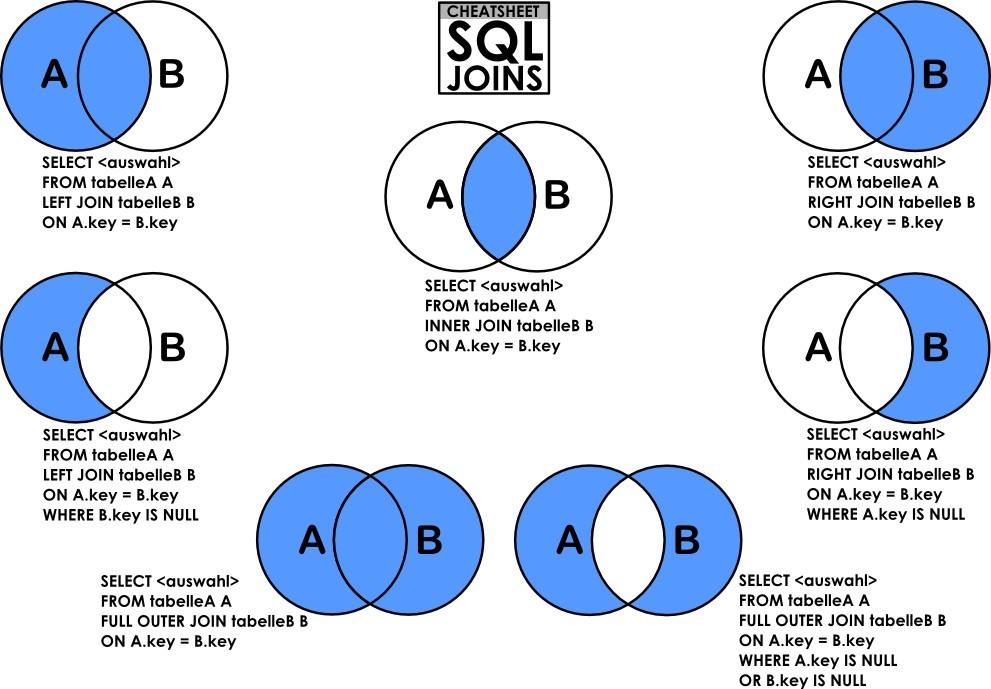
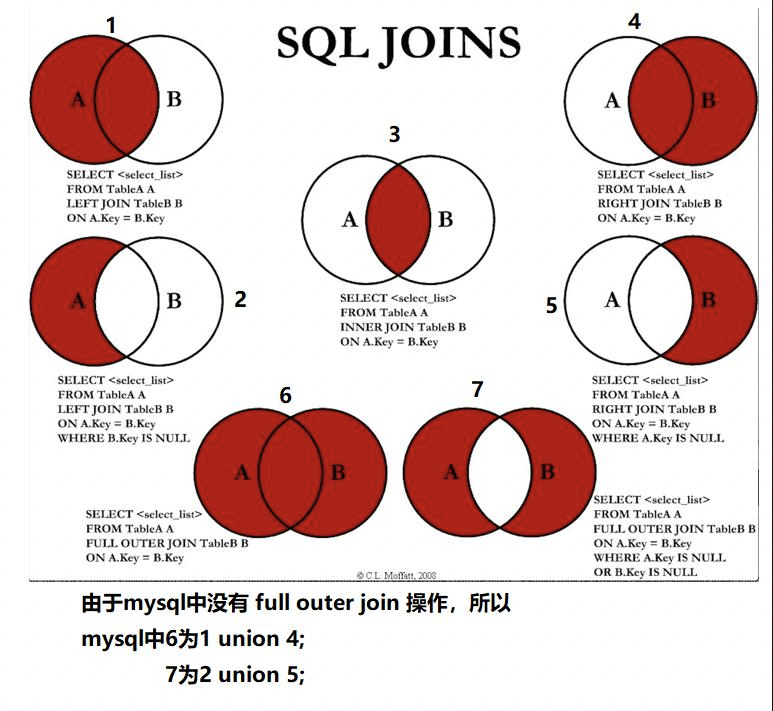
- 左连结时在右表建立索引能提高查询效率
- 右连结在左表建立索引能提高效率(但是结合上一条情况,将左右表互换一下,就不用考虑现在的情况)
- 永远用小结果集驱动大的结果集,保证join语句中被驱动的表上join字段已经被索引
什么是索引
MySQL 官方对索引的定义为:索引(Index)是帮助 MySQL 高效获取数据的数据结构。可以得到索引的本质:索引是数据结构。可以简单理解为排好序的快速查找数据结构。
在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。
哪些情况适合创建索引
- 主键自动建立唯- -索引
- 频繁作为查询条件的字段应该创建索引
- 查询中与其它表关联的字段,外键关系建立索引
- 单键/组合索引的选择问题,who? (在高并发下倾向创建组合索引)
- 查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度
- 查询中统计或者分组字段
哪些情况不适合创建索引
- 表记录太少
- 经常增删改的表
- Why: 提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELEDE,因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件
- 数据重复且分布平均的表字段,因此应该只为最经常查询和最经常排序的数据列建立索引。注意,如果某个数据列包含许多重复的内容,为它建立索引就没有太大的实际效果。
- Where条件里用不到的字段不创建索引
Explain 性能分析
使用 EXPLAIN 关键字可以模拟优化器执行 SQL 查询语句,从而知道 MySQL 是如何处理你的 SQL 语句的。分 析你的查询语句或是表结构的性能瓶颈。
用法: Explain+SQL 语句。
Explain 执行后返回的信息:
| id | Select_type | Table | Type | Possible_keys | Key | Key_len | ref | Rows | extra |
|---|
-
id:select 查询的序列号,包含一组数字,表示查询中执行 select 子句或操作表的顺序。
- id 相同,执行顺序由上至下
- id 不同,如果是子查询,id 的序号会递增,id 值越大优先级越高,越先被执行
- id 如果相同,可以认为是一组,从上往下顺序执行;在所有组中,id 值越大,优先级越高,越先执行衍生 = DERIVED
- 关注点:id 号每个号码,表示一趟独立的查询。一个 sql 的查询趟数越少越好。
-
select_type:select_type 代表查询的类型,主要是用于区别普通查询、联合查询、子查询等的复杂查询。
-
select_type 属性 含义 SIMPLE 简单的 select 查询,查询中不包含子查询或者 UNION PRIMARY 查询中若包含任何复杂的子部分,最外层查询则被标记为 Primary DERIVED 在 FROM 列表中包含的子查询被标记为 DERIVED(衍生) MySQL 会递归执行这些子查询, 把结果放在临时表里。 SUBQUERY 在SELECT或WHERE列表中包含了子查询 DEPEDENT SUBQUERY 在SELECT或WHERE列表中包含了子查询,子查询基于外层 UNCACHEABLE SUBQUERY 无法使用缓存的子查询 UNION 若第二个SELECT出现在UNION之后,则被标记为UNION; 若UNION包含在FROM子句的子查询中,外层SELECT将被标记为:DERIVED UNION RESULT 从UNION表获取结果的SELECT
-
-
table:这个数据是基于哪张表的。
-
🔥type:type 是查询的访问类型。是较为重要的一个指标,结果值从最好到最坏依次是:
- system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index >all。一般来说,得保证查询至少达到 range 级别,最好能达到 ref。
-
possible_keys:显示可能应用在这张表中的索引,一个或多个。查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询实际使用。
-
🔥key:实际使用的索引。如果为NULL,则没有使用索引。
-
key_len:表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。 key_len 字段能够帮你检查是否充分的 利用上了索引。ken_len 越长,说明索引使用的越充分。相同的产出,len越小越好
-
ref:显示索引的哪一列被使用了,如果可能的话,是一个常数。哪些列或常量被用于查找索引列上的值。
-
rows:rows 列显示 MySQL 认为它执行查询时必须检查的行数。越少越好!
-
extra:其他的额外重要的信息。
- 🔥❌using filesort:说明 mysql 会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取。MySQL 中无法利用索引 完成的排序操作称为“文件排序”。
- 🔥❌using temporary:使了用临时表保存中间结果,MySQL 在对查询结果排序时使用临时表。常见于排序 order by 和分组查询 group by。
- 🔥✅using index:Using index 代表表示相应的 select 操作中使用了覆盖索引(Covering Index),避免访问了表的数据行,效率不错! 😊如果同时出现 using where,表明索引被用来执行索引键值的查找;如果没有同时出现 using where,表明索引只是 用来读取数据而非利用索引执行查找。利用索引进行了排序或分组。
- Using where:表明使用了 where 过滤。
- using join buffer:使用了连接缓存。
- impossible where:where 子句的值总是 false,不能用来获取任何元组。
- select tables optimized away:在没有 GROUPBY 子句的情况下,基于索引优化 MIN/MAX 操作或者对于 MyISAM 存储引擎优化 COUNT(*)操 作,不必等到执行阶段再进行计算,查询执行计划生成的阶段即完成优化。
- distinct:优化distinct的操作,咋找到第一匹配的元组后即停止找同样值的动作
关于sql的优化
system > const > eq_ref > ref > range > index > all
- system: 表只有一条数据(等于系统表)这是const类型的特例,平时会出现,这个也可以忽略不计
- const:表示通过索引一次就找到了,const用于比较primary kry或者unique索引,因为之匹配一行数据,所以很快,如将主键置于where列表中,mysql就能将查询转换为一个常量
- eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键或者唯一索引扫描。
- ref:非唯一性索引扫描,返回匹配某个单独值的所有行,本质上也是一种索引访问,它返回所有匹配某个单独值的行,然而,它可能会找到多个符合条件的行,所以他应该属于查找和扫描的混合体
- range:只检索给定范围的行,使用一个索引来选择行。key 列显示使用了哪个索引一.般就是在你的where语句中出现了between、<、>、in等的查询,这种范围扫描索引扫描比全表扫描要好,因为它只需要开始于索引的某-一点,而结束语另一点,不用扫描全部索引。
- index:Full Index Scan,index 与ALL区别为index类型只遍历索引树。这通常比ALL快,因为索引文件通常比数据文件小。(也就是说虽然all和Index都是读全表,但index是 从索引中读取的,而all是 从硬盘中读的)
- all:FullTableScan,将遍历全表以找到匹配的行
一般来说,得保证查询至少到达range级别,最好能到达ref
索引失效
- 过滤条件要使用索引必须按照索引建立时的顺序,依次满足,一旦跳过某个字段,索引后面的字段都无法被使用。
- 不要在索引列上做任何计算
- 在查询列上使用了函数等号左边无计算
- 在查询列上做了转换(字符串不加单引号,则会在 name 列上做一次转换!)等号左边无转换
- 索引列上不能有范围查询;将可能做范围查询的字段的索引顺序放在最后
- mysql 在使用不等于(!= 或者<>)时,有时会无法使用索引会导致全表扫描。
- like 的前后模糊匹配 前缀不能出现模糊匹配
- 减少使用 or 使用 union all 或者 union 来替代
索引是否失效练习
假设 index(a,b,c);
| Where | 索引是否被使用 |
|---|---|
| where a = 3 | Y,使用到a |
| where a = 3 and b = 5 | Y,使用到a,b |
| where a = 3 and b = 5 and c = 4 | Y,使用到 a,b,c |
| whereb=3或者whereb=3andc=4 或者 where c = 4 | N |
| where a = 3 and c = 5 | 使用到 a, 但是 c 不可以,b 中间断了 |
| where a = 3 and b > 4 and c = 5 | 使用到 a 和 b, c 不能用在范围之后,b 断了 |
| where a is null and b is not null | is null 支持索引 但是 is not null 不支持,所 以 a 可以使用索引,但是 b 不可以使用 |
| where a <> 3 | 不能使用索引 |
| where abs(a) =3 | 不能使用 索引 |

