
python——流畅的python阅读笔记
 乘以花色的个数,用来扩大位数的范围,避免相同误差,就很妙
乘以花色的个数,用来扩大位数的范围,避免相同误差,就很妙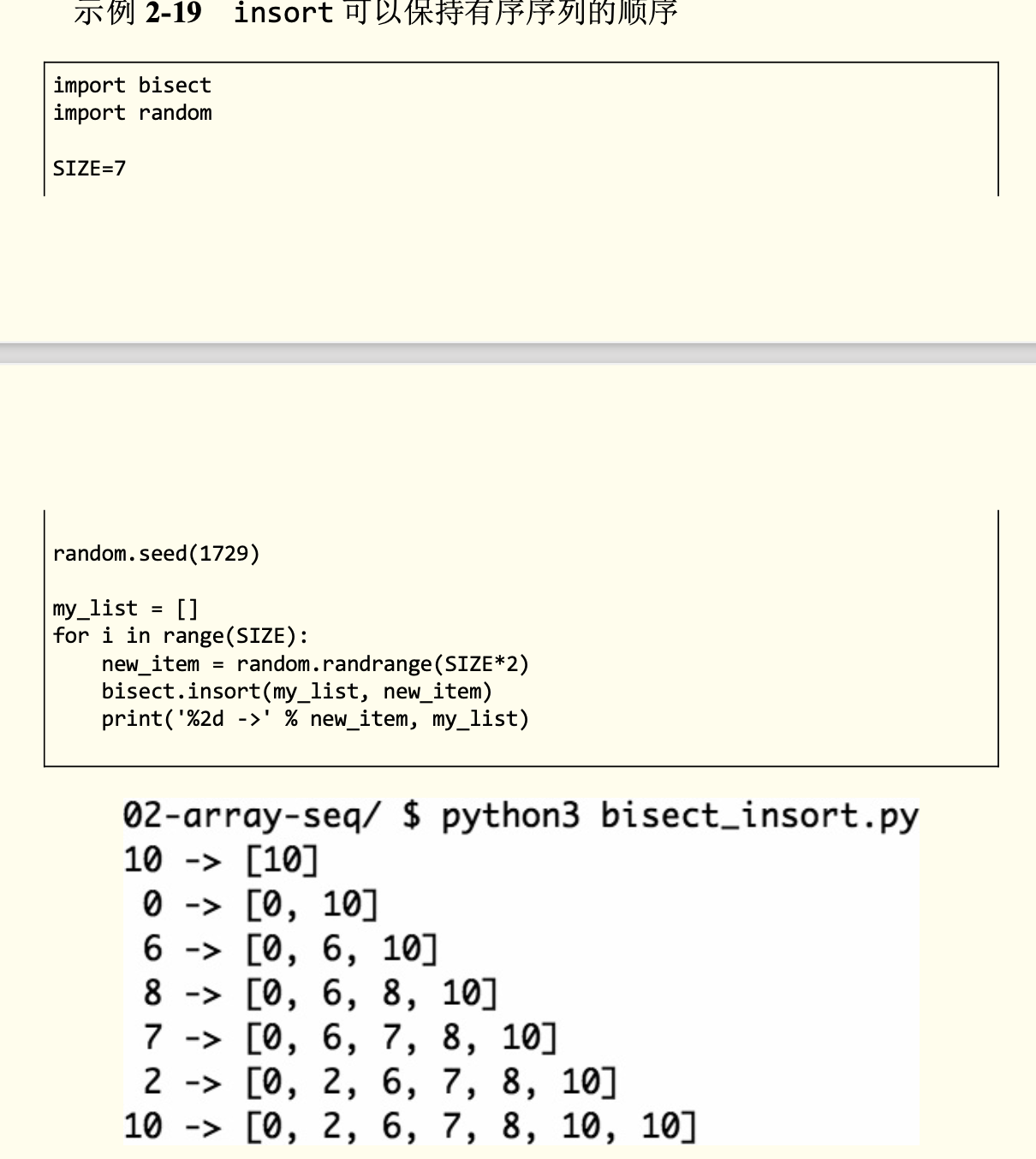




一摞有序的纸牌

扑克牌的排序
![扑克牌的排序]()
乘以花色的个数,用来扩大位数的范围,避免相同误差,就很妙
bisect的使用
分数与成绩的映射

向有序列表插入新的元素
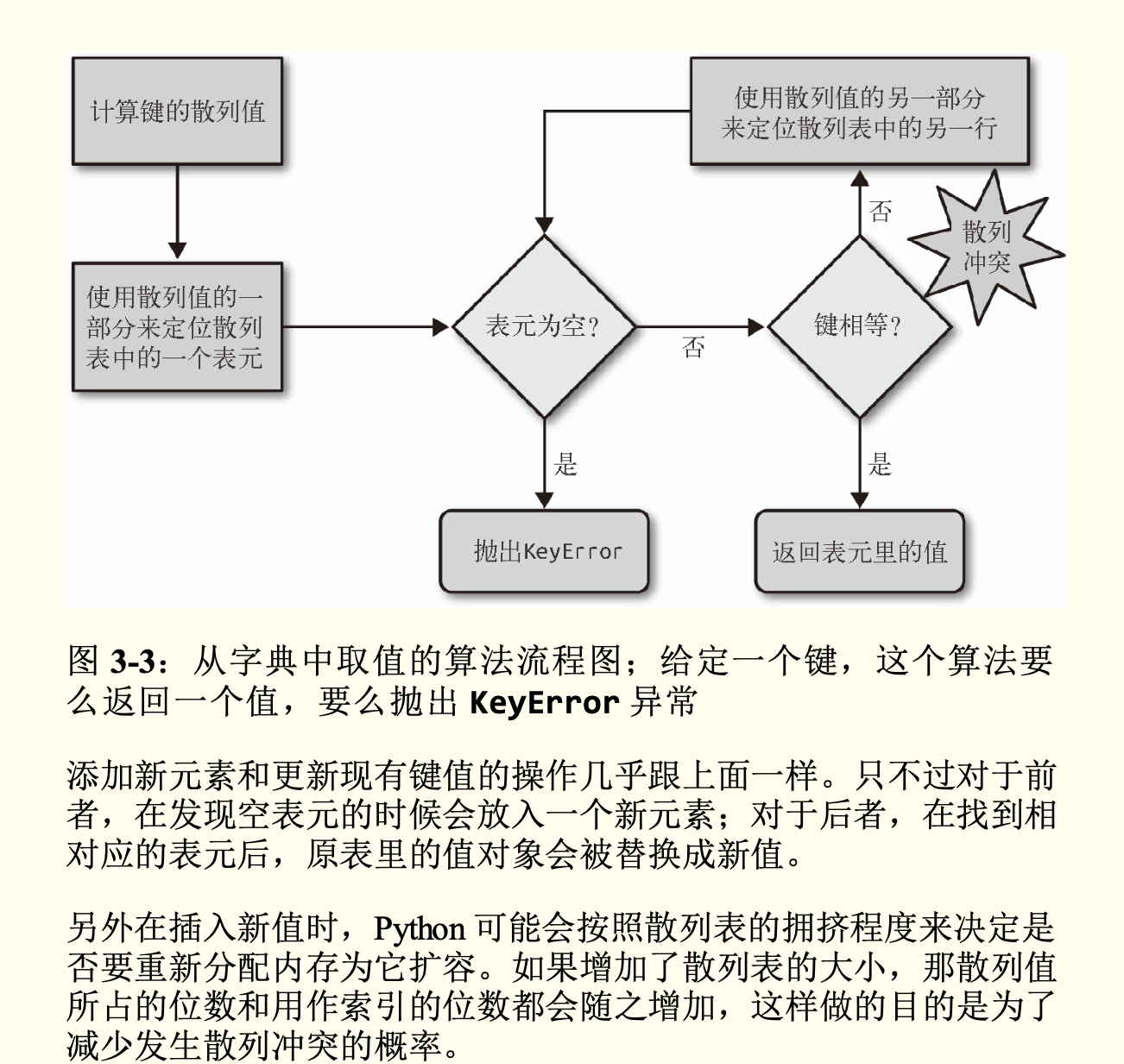
字典中的散列表
operator模块
itemgetter

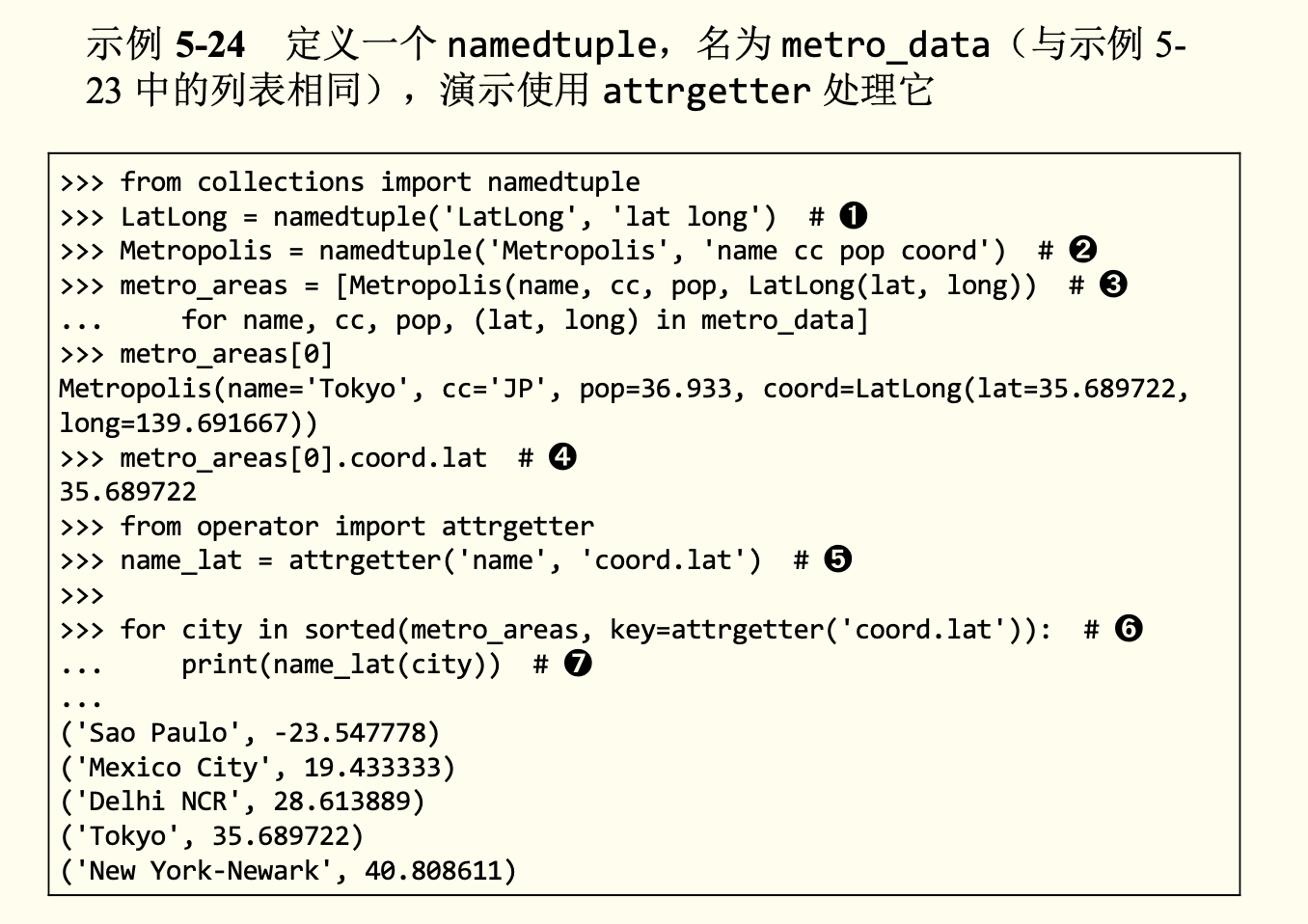
attrgetter
methodcaller
冻结参数
切片原理

slice.indices
等差数列



生成器函数
标准库中的生成器函数
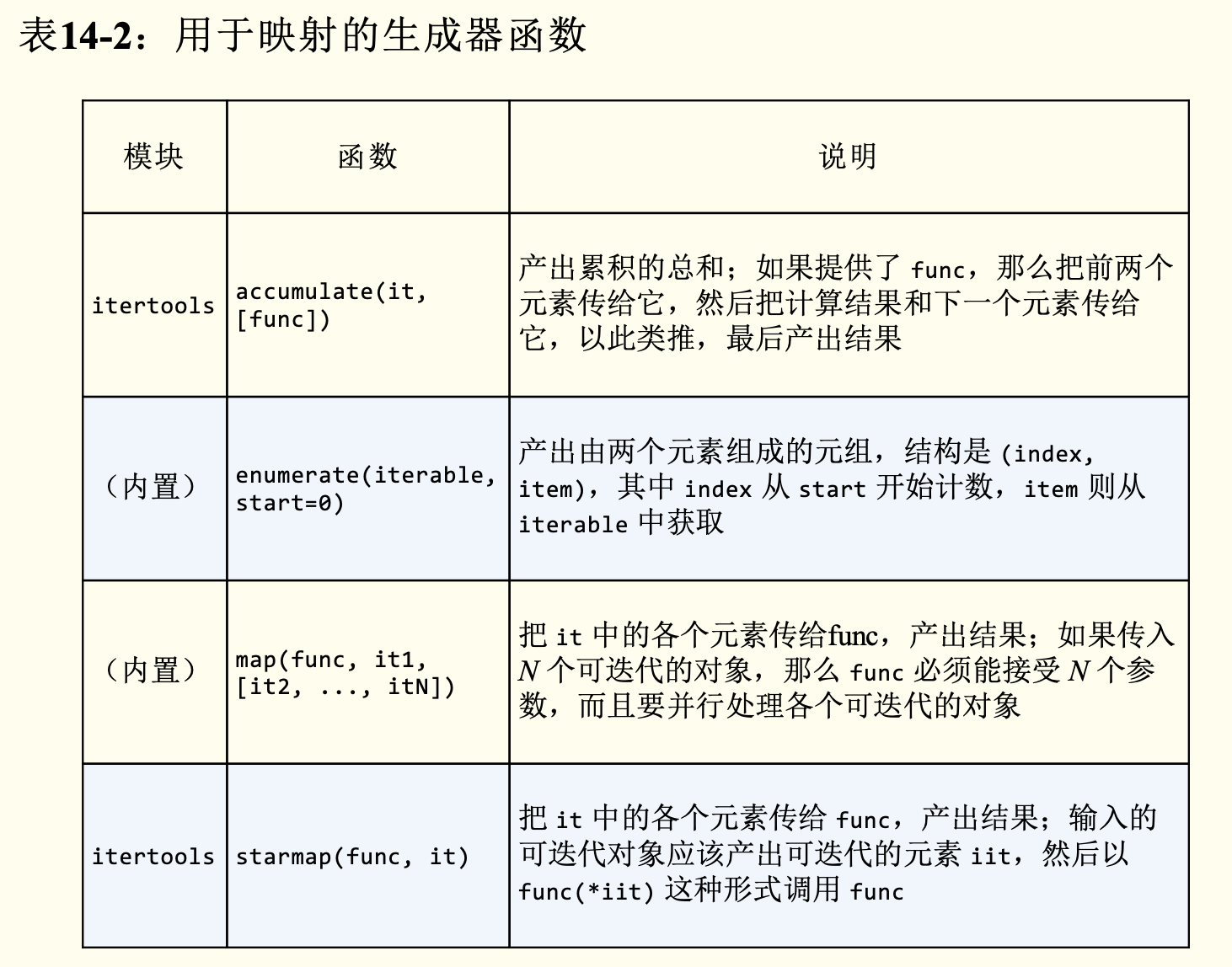
| 模块 | 函数 | 说明 |
|---|---|---|
| itertools | compress(it, selector_it) | 并行处理两个可迭代的对象;如果 selector_it 中的元素是真值,产出 it 中对应的元素 |
| itertools | dropwhile(predicate, it) | 处理 it,跳过 predicate 的计算结果为真值的元 素,然后产出剩下的各个元素(不再进一步检 查) |
| itertools | (内置) filter(predicate, it) | 把 it 中的各个元素传给 predicate,如果 predicate(item) 返回真值,那么产出对应的元 素;如果 predicate 是 None,那么只产出真值元 素 |
| itertools | filterfalse(predicate, it) | 与 filter 函数的作用类似,不过 predicate 的 逻辑是相反的:predicate 返回假值时产出对应 的元素 |
| itertools | islice(it, stop) 或 islice(it, start, stop, step=1) | 产出 it 的切片,作用类似于 s[:stop] 或 s[start:stop:step],不过 it 可以是任何可迭代 的对象,而且这个函数实现的是惰性操作 |
| itertools | takewhile(predicate, it) | predicate 返回真值时产出对应的元素,然后立 即停止,不再继续检查 |

用于映射的生成器函数


用于合并的生成器函数
| 模块 | 函数 | 说明 |
|---|---|---|
| itertools | chain(it1, ..., itN) | 先产出 it1 中的所有元素,然后产出 it2 中的 所有元素,以此类推,无缝连接在一起 |
| itertools | chain.from_iterable(it) | 产出 it 生成的各个可迭代对象中的元素,一个 接一个,无缝连接在一起;it 应该产出可迭代 的元素,例如可迭代的对象列表 |
| itertools | product(it1, ..., itN, repeat=1) | 计算笛卡儿积:从输入的各个可迭代对象中获 取元素,合并成由 N 个元素组成的元组,与嵌 套的 for 循环效果一样;repeat 指明重复处理 多少次输入的可迭代对象 |
| (内置) | zip(it1, ..., itN) | 并行从输入的各个可迭代对象中获取元素,产 出由 N 个元素组成的元组,只要有一个可迭代 的对象到头了,就默默地停止 |
| itertools | zip_longest(it1, ..., itertools itN, fillvalue=None) | 并行从输入的各个可迭代对象中获取元素,产 出由 N 个元素组成的元组,等到最长的可迭代 对象到头后才停止,空缺的值使用 fillvalue 填充 |


计算笛卡儿积的惰性生成器


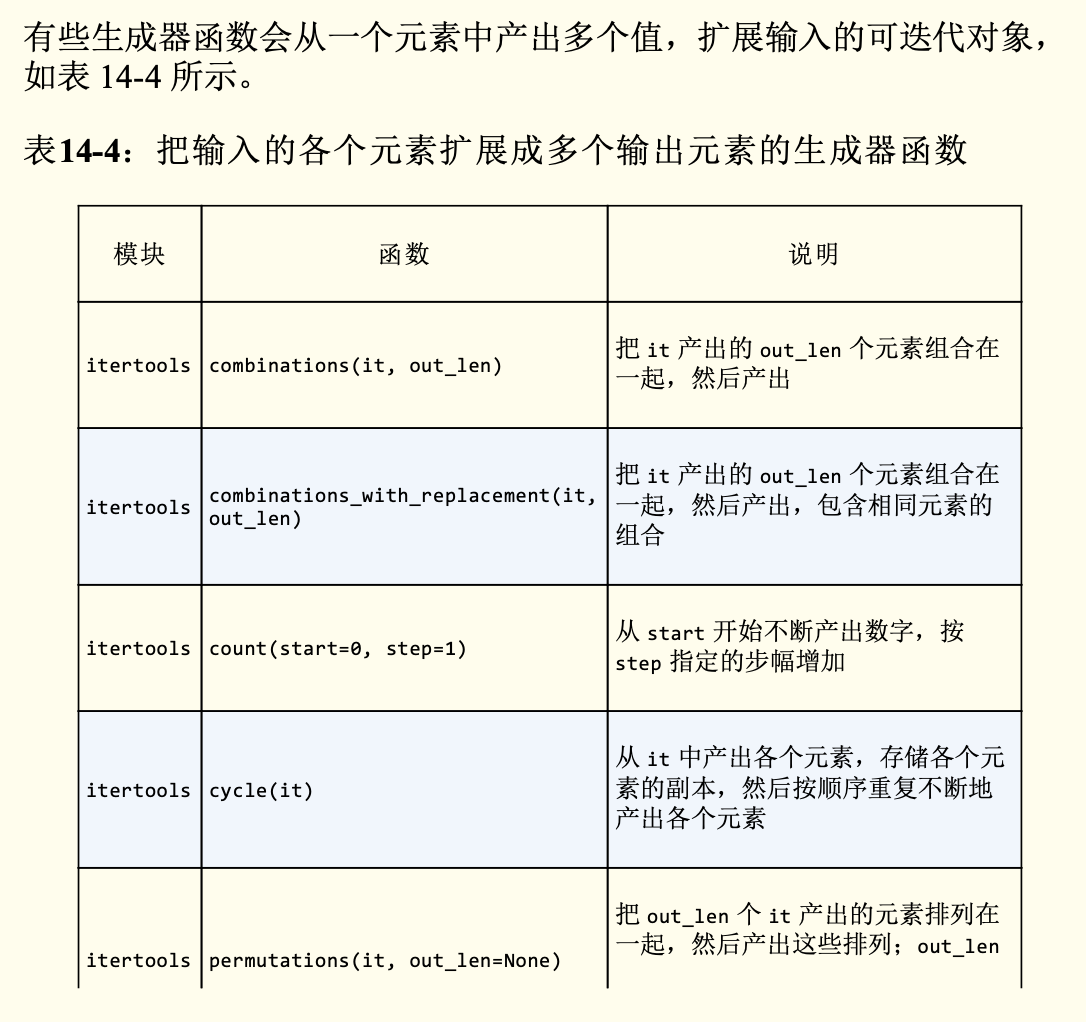





重新排列元素的生成器函数
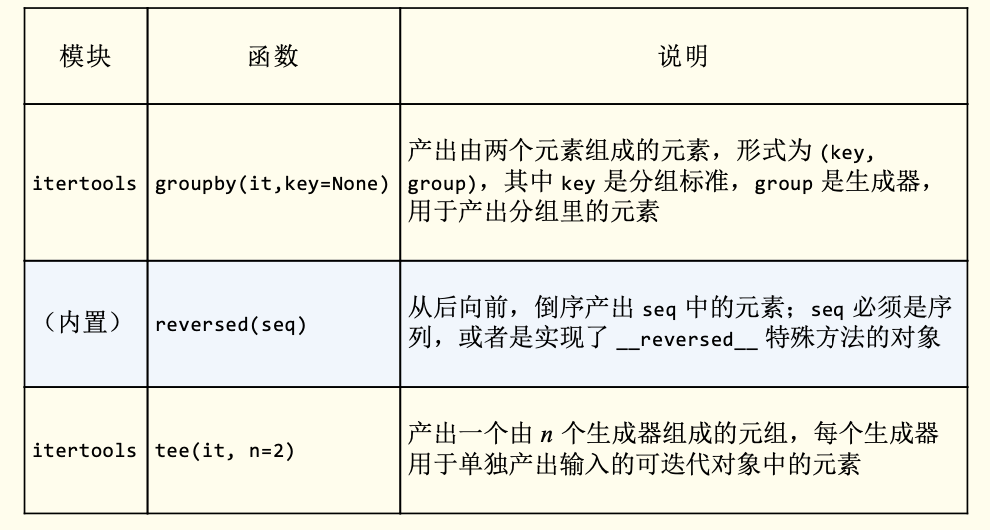


可迭代的归约函数

使用yield from



from collections import namedtuple
Result = namedtuple('Result', 'count average')
# 子生成器
def averager():
total = 0.0
count = 0
average = None
while True:
# main 函数中的客户代码发送的各个值绑定到这里的 term 变量上
term = yield
# 至关重要的终止条件。如果不这么做,使用 yield from 调用这个协程的生成器会永远阻塞
if term is None:
break
total += term
count += 1
average = total / count
# 返回的 Result 会成为 grouper 函数中 yield from 表达式的值
return Result(count, average)
# 委派生成器
def grouper(results, key): # grouper 是委派生成器
# 这个循环每次迭代时会新建一个 averager 实例;每个实例都是作为 协程使用的生成器对象
while True:
# grouper 发送的每个值都会经由 yield from 处理,通过管道传给 averager 实例。
# grouper 会在 yield from 表达式处暂停,等待 averager 实例处理客户端发来的值。
# averager 实例运行完毕后,返 回的值绑定到 results[key] 上。
# while 循环会不断创建 averager 实 例,处理更多的值
results[key] = yield from averager()
# main 函数是客户端代码,用 PEP 380 定义的术语来说,是“调用 方”。这是驱动一切的函数
# 客户端代码,即调用方
def main(data):
results = {}
for key, values in data.items():
# group 是调用 grouper 函数得到的生成器对象,传给 grouper 函数 的第一个参数是 results,
# 用于收集结果;第二个参数是某个键。group 作为协程使用
group = grouper(results, key)
# 预激 group 协程
next(group)
for value in values:
# 把各个 value 传给 grouper。传入的值最终到达 averager 函数中 term = yield 那一行;
# grouper 永远不知道传入的值是什么
group.send(value)
# 把 None 传入 grouper,导致当前的 averager 实例终止,也让grouper继续运行,再创建一个 averager 实例,处理下一组值
group.send(None) # 重要!
# print(results) # 如果要调试,去掉注释
report(results)
# 输出报告
def report(results):
for key, result in sorted(results.items()):
group, unit = key.split(';')
print('{:2} {:5} averaging {:.2f}{}'.format(result.count, group, result.average, unit))
data = {
'girls;kg': [40.9, 38.5, 44.3, 42.2, 45.2, 41.7, 44.5, 38.0, 40.6, 44.5],
'girls;m': [1.6, 1.51, 1.4, 1.3, 1.41, 1.39, 1.33, 1.46, 1.45, 1.43],
'boys;kg': [39.0, 40.8, 43.2, 40.8, 43.1, 38.6, 41.4, 40.6, 36.3],
'boys;m': [1.38, 1.5, 1.32, 1.25, 1.37, 1.48, 1.25, 1.49, 1.46]
}
if __name__ == '__main__':
main(data)
"""
return:
9 boys averaging 40.42kg
9 boys averaging 1.39m
10 girls averaging 42.04kg
10 girls averaging 1.43m
"""
使用期物处理并发
实验Executor.map方法
from time import sleep, strftime
from concurrent import futures
"""
建议自行复制出去修改max_workers参数或者range(5)的次数体验一下,得到不同的延迟效果
"""
def display(*args):
print(strftime('[%H:%M:%S]'), end=' ')
print(*args)
def loiter(n):
msg = '{}loiter({}): doing nothing for {}s...'
display(msg.format('\t'*n, n, n))
sleep(n)
msg = '{}loiter({}): done.'
display(msg.format('\t'*n, n))
return n * 10
def main():
display('Script starting.')
executor = futures.ThreadPoolExecutor(max_workers=3)
results = executor.map(loiter, range(5))
display('results:', results)
display('Waiting for individual results:')
for i, result in enumerate(results):
display('result {}: {}'.format(i, result))
main()
"""
[11:04:00] Script starting.
[11:04:00] loiter(0): doing nothing for 0s...
[11:04:00] loiter(0): done.
[11:04:00] loiter(1): doing nothing for 1s...
[11:04:00] results: <generator object Executor.map.<locals>.result_iterator at 0x10bf437b0>
[11:04:00] loiter(3): doing nothing for 3s...
[11:04:00] Waiting for individual results:
[11:04:00] loiter(2): doing nothing for 2s...
[11:04:00] result 0: 0
[11:04:01] loiter(1): done.
[11:04:01] loiter(4): doing nothing for 4s...
[11:04:01] result 1: 10
[11:04:02] loiter(2): done.
[11:04:02] result 2: 20
[11:04:03] loiter(3): done.
[11:04:03] result 3: 30
[11:04:05] loiter(4): done.
[11:04:05] result 4: 40
"""
这样写的话,有一个问题,最后输出结果的顺序是根据前面创建期物的可迭代序列range(5)的顺序来的(返回结果的顺序与调动开始的顺序一致),如果第一个调用生成结果的用时10秒,而其他的只用1秒,代码会阻塞10秒,获取map返回的生成器产出的第一个结果。在此之后,获取后续结果时不会阻塞,因为后续的调用已经结束。
为此,要把Executor.submit方法和futures.as_complated函数结合起来使用。
"""
executor.map方法,传入range(5, -1, -1)时
返回的结果(注意看返回的时间,result,全在同一秒钟输出的)
[12:16:16] Script starting.
[12:16:16] loiter(5): doing nothing for 5s...
[12:16:16] loiter(4): doing nothing for 4s...
[12:16:16] loiter(3): doing nothing for 3s...
[12:16:16] results: <generator object Executor.map.<locals>.result_iterator at 0x106f27820>
[12:16:16] Waiting for individual results:
[12:16:19] loiter(3): done.
[12:16:19] loiter(2): doing nothing for 2s...
[12:16:20] loiter(4): done.
[12:16:20] loiter(1): doing nothing for 1s...
[12:16:21] loiter(5): done.
[12:16:21] loiter(0): doing nothing for 0s...
[12:16:21] loiter(0): done.
[12:16:21] result 0: 50
[12:16:21] result 1: 40
[12:16:21] result 2: 30
[12:16:21] loiter(2): done.
[12:16:21] loiter(1): done.
[12:16:21] result 3: 20
[12:16:21] result 4: 10
[12:16:21] result 5: 0
"""
使用Executor.submit方法和futures.as_complated方法
from concurrent import futures
from test import display, loiter
with futures.ThreadPoolExecutor(max_workers=3) as executor:
todo = []
# for i in range(5):
for i in range(5, -1, -1):
future = executor.submit(loiter, i)
todo.append(future)
display('results:', todo)
display('Waiting for individual results:')
for i, future in enumerate(futures.as_completed(todo)):
display('result {}: {}'.format(i, future.result()))
"""
返回结果没有阻塞
[12:25:19] loiter(5): doing nothing for 5s...
[12:25:19] loiter(4): doing nothing for 4s...
[12:25:19] loiter(3): doing nothing for 3s...
[12:25:19] results: [<Future at 0x108d66eb0 state=running>, <Future at 0x108d7cee0 state=running>, <Future at 0x108d882b0 state=running>, <Future at 0x108d88640 state=pending>, <Future at 0x108d88760 state=pending>, <Future at 0x108d88850 state=pending>]
[12:25:19] Waiting for individual results:
[12:25:22] loiter(3): done.
[12:25:22] loiter(2): doing nothing for 2s...
[12:25:22] result 0: 30
[12:25:23] loiter(4): done.
[12:25:23] loiter(1): doing nothing for 1s...
[12:25:23] result 1: 40
[12:25:24] loiter(5): done.
[12:25:24] loiter(0): doing nothing for 0s...
[12:25:24] loiter(0): done.
[12:25:24] result 2: 50
[12:25:24] result 3: 0
[12:25:24] loiter(1): done.
[12:25:24] loiter(2): done.
[12:25:24] result 4: 10
[12:25:24] result 5: 20
"""
线程版 国旗下载
# flags2_threadpool.py
"""Download flags of countries (with error handling).
ThreadPool version
Sample run::
$ python3 flags2_threadpool.py -s ERROR -e
ERROR site: http://localhost:8003/flags
Searching for 676 flags: from AA to ZZ
30 concurrent connections will be used.
--------------------
150 flags downloaded.
361 not found.
165 errors.
Elapsed time: 7.46s
"""
# BEGIN FLAGS2_THREADPOOL
import collections
from concurrent import futures
import requests
import tqdm # <1>
from flags2_common import main, HTTPStatus # <2>
from flags2_sequential import download_one # <3>
DEFAULT_CONCUR_REQ = 30 # <4>
MAX_CONCUR_REQ = 1000 # <5>
def download_many(cc_list, base_url, verbose, concur_req):
counter = collections.Counter()
with futures.ThreadPoolExecutor(max_workers=concur_req) as executor: # <6>
to_do_map = {} # <7>
for cc in sorted(cc_list): # <8>
future = executor.submit(download_one,
cc, base_url, verbose) # <9>
to_do_map[future] = cc # <10>
done_iter = futures.as_completed(to_do_map) # <11>
if not verbose:
done_iter = tqdm.tqdm(done_iter, total=len(cc_list)) # <12>
for future in done_iter: # <13>
try:
res = future.result() # <14>
except requests.exceptions.HTTPError as exc: # <15>
error_msg = 'HTTP {res.status_code} - {res.reason}'
error_msg = error_msg.format(res=exc.response)
except requests.exceptions.ConnectionError as exc:
error_msg = 'Connection error'
else:
error_msg = ''
status = res.status
if error_msg:
status = HTTPStatus.error
counter[status] += 1
if verbose and error_msg:
cc = to_do_map[future] # <16>
print('*** Error for {}: {}'.format(cc, error_msg))
return counter
if __name__ == '__main__':
main(download_many, DEFAULT_CONCUR_REQ, MAX_CONCUR_REQ)
# END FLAGS2_THREADPOOL
asyncio
asyncio协程版 国旗下载
# flags2_common.py
"""Utilities for second set of flag examples.
"""
import os
import time
import sys
import string
import argparse
from collections import namedtuple
from enum import Enum
Result = namedtuple('Result', 'status data')
HTTPStatus = Enum('Status', 'ok not_found error')
POP20_CC = ('CN IN US ID BR PK NG BD RU JP '
'MX PH VN ET EG DE IR TR CD FR').split()
DEFAULT_CONCUR_REQ = 1
MAX_CONCUR_REQ = 1
SERVERS = {
'REMOTE': 'http://flupy.org/data/flags',
'LOCAL': 'http://localhost:8001/flags',
'DELAY': 'http://localhost:8002/flags',
'ERROR': 'http://localhost:8003/flags',
}
DEFAULT_SERVER = 'LOCAL'
DEST_DIR = 'downloads/'
COUNTRY_CODES_FILE = 'country_codes.txt'
def save_flag(img, filename):
path = os.path.join(DEST_DIR, filename)
with open(path, 'wb') as fp:
fp.write(img)
def initial_report(cc_list, actual_req, server_label):
if len(cc_list) <= 10:
cc_msg = ', '.join(cc_list)
else:
cc_msg = 'from {} to {}'.format(cc_list[0], cc_list[-1])
print('{} site: {}'.format(server_label, SERVERS[server_label]))
msg = 'Searching for {} flag{}: {}'
plural = 's' if len(cc_list) != 1 else ''
print(msg.format(len(cc_list), plural, cc_msg))
plural = 's' if actual_req != 1 else ''
msg = '{} concurrent connection{} will be used.'
print(msg.format(actual_req, plural))
def final_report(cc_list, counter, start_time):
elapsed = time.time() - start_time
print('-' * 20)
msg = '{} flag{} downloaded.'
plural = 's' if counter[HTTPStatus.ok] != 1 else ''
print(msg.format(counter[HTTPStatus.ok], plural))
if counter[HTTPStatus.not_found]:
print(counter[HTTPStatus.not_found], 'not found.')
if counter[HTTPStatus.error]:
plural = 's' if counter[HTTPStatus.error] != 1 else ''
print('{} error{}.'.format(counter[HTTPStatus.error], plural))
print('Elapsed time: {:.2f}s'.format(elapsed))
def expand_cc_args(every_cc, all_cc, cc_args, limit):
codes = set()
A_Z = string.ascii_uppercase
if every_cc:
codes.update(a+b for a in A_Z for b in A_Z)
elif all_cc:
with open(COUNTRY_CODES_FILE) as fp:
text = fp.read()
codes.update(text.split())
else:
for cc in (c.upper() for c in cc_args):
if len(cc) == 1 and cc in A_Z:
codes.update(cc+c for c in A_Z)
elif len(cc) == 2 and all(c in A_Z for c in cc):
codes.add(cc)
else:
msg = 'each CC argument must be A to Z or AA to ZZ.'
raise ValueError('*** Usage error: '+msg)
return sorted(codes)[:limit]
def process_args(default_concur_req):
server_options = ', '.join(sorted(SERVERS))
parser = argparse.ArgumentParser(
description='Download flags for country codes. '
'Default: top 20 countries by population.')
parser.add_argument('cc', metavar='CC', nargs='*',
help='country code or 1st letter (eg. B for BA...BZ)')
parser.add_argument('-a', '--all', action='store_true',
help='get all available flags (AD to ZW)')
parser.add_argument('-e', '--every', action='store_true',
help='get flags for every possible code (AA...ZZ)')
parser.add_argument('-l', '--limit', metavar='N', type=int,
help='limit to N first codes', default=sys.maxsize)
parser.add_argument('-m', '--max_req', metavar='CONCURRENT', type=int,
default=default_concur_req,
help='maximum concurrent requests (default={})'
.format(default_concur_req))
parser.add_argument('-s', '--server', metavar='LABEL',
default=DEFAULT_SERVER,
help='Server to hit; one of {} (default={})'
.format(server_options, DEFAULT_SERVER))
parser.add_argument('-v', '--verbose', action='store_true',
help='output detailed progress info')
args = parser.parse_args()
if args.max_req < 1:
print('*** Usage error: --max_req CONCURRENT must be >= 1')
parser.print_usage()
sys.exit(1)
if args.limit < 1:
print('*** Usage error: --limit N must be >= 1')
parser.print_usage()
sys.exit(1)
args.server = args.server.upper()
if args.server not in SERVERS:
print('*** Usage error: --server LABEL must be one of',
server_options)
parser.print_usage()
sys.exit(1)
try:
cc_list = expand_cc_args(args.every, args.all, args.cc, args.limit)
except ValueError as exc:
print(exc.args[0])
parser.print_usage()
sys.exit(1)
if not cc_list:
cc_list = sorted(POP20_CC)
return args, cc_list
def main(download_many, default_concur_req, max_concur_req):
args, cc_list = process_args(default_concur_req)
actual_req = min(args.max_req, max_concur_req, len(cc_list))
initial_report(cc_list, actual_req, args.server)
base_url = SERVERS[args.server]
t0 = time.time()
counter = download_many(cc_list, base_url, args.verbose, actual_req)
assert sum(counter.values()) == len(cc_list), \
'some downloads are unaccounted for'
final_report(cc_list, counter, t0)
# flags2_asyncio.py
"""Download flags and names of countries.
asyncio version
"""
import asyncio
import collections
from os import wait
import aiohttp
from aiohttp import web
import tqdm
from flags2_common import main, HTTPStatus, Result, save_flag
# default set low to avoid errors from remote site, such as
# 503 - Service Temporarily Unavailable
DEFAULT_CONCUR_REQ = 5
MAX_CONCUR_REQ = 1000
class FetchError(Exception):
def __init__(self, country_code):
self.country_code = country_code
# BEGIN FLAGS3_ASYNCIO
async def http_get(url):
async with aiohttp.ClientSession() as client:
res = await client.get(url)
if res.status == 200:
ctype = res.headers.get('Content-type', '').lower()
if 'json' in ctype or url.endswith('json'):
data = await res.json() # <1>
else:
data = await res.read() # <2>
return data
elif res.status == 404:
raise web.HTTPNotFound()
else:
raise aiohttp.errors.HttpProcessingError(
code=res.status, message=res.reason,
headers=res.headers)
async def get_country(base_url, cc):
url = '{}/{cc}/metadata.json'.format(base_url, cc=cc.lower())
metadata = await http_get(url) # <3>
return metadata['country']
async def get_flag(base_url, cc):
url = '{}/{cc}/{cc}.gif'.format(base_url, cc=cc.lower())
return (await http_get(url)) # <4>
async def download_one(cc, base_url, semaphore, verbose):
try:
async with semaphore: # <5>
image = await get_flag(base_url, cc)
async with semaphore:
country = await get_country(base_url, cc)
except web.HTTPNotFound:
status = HTTPStatus.not_found
msg = 'not found'
except Exception as exc:
raise FetchError(cc) from exc
else:
country = country.replace(' ', '_')
filename = '{}-{}.gif'.format(country, cc)
loop = asyncio.get_event_loop()
loop.run_in_executor(None, save_flag, image, filename)
status = HTTPStatus.ok
msg = 'OK'
if verbose and msg:
print(cc, msg)
return Result(status, cc)
# END FLAGS3_ASYNCIO
async def downloader_coro(cc_list, base_url, verbose, concur_req):
counter = collections.Counter()
semaphore = asyncio.Semaphore(concur_req)
to_do = [download_one(cc, base_url, semaphore, verbose)
for cc in sorted(cc_list)]
to_do_iter = asyncio.as_completed(to_do)
if not verbose:
to_do_iter = tqdm.tqdm(to_do_iter, total=len(cc_list))
for future in to_do_iter:
try:
res = await future
except FetchError as exc:
country_code = exc.country_code
try:
error_msg = exc.__cause__.args[0]
except IndexError:
error_msg = exc.__cause__.__class__.__name__
if verbose and error_msg:
msg = '*** Error for {}: {}'
print(msg.format(country_code, error_msg))
status = HTTPStatus.error
else:
status = res.status
counter[status] += 1
return counter
def download_many(cc_list, base_url, verbose, concur_req):
loop = asyncio.get_event_loop()
coro = downloader_coro(cc_list, base_url, verbose, concur_req)
counts = loop.run_until_complete(coro)
loop.close()
return counts
if __name__ == '__main__':
main(download_many, DEFAULT_CONCUR_REQ, MAX_CONCUR_REQ)
使用asyncio包编写TCP服务器
# charfinder.py 方便后面使用
#!/usr/bin/env python3
"""
Unicode character finder utility:
find characters based on words in their official names.
This can be used from the command line, just pass words as arguments.
Here is the ``main`` function which makes it happen::
>>> main('rook') # doctest: +NORMALIZE_WHITESPACE
U+2656 ♖ WHITE CHESS ROOK
U+265C ♜ BLACK CHESS ROOK
(2 matches for 'rook')
>>> main('rook', 'black') # doctest: +NORMALIZE_WHITESPACE
U+265C ♜ BLACK CHESS ROOK
(1 match for 'rook black')
>>> main('white bishop') # doctest: +NORMALIZE_WHITESPACE
U+2657 ♗ WHITE CHESS BISHOP
(1 match for 'white bishop')
>>> main("jabberwocky's vest")
(No match for "jabberwocky's vest")
For exploring words that occur in the character names, there is the
``word_report`` function::
>>> index = UnicodeNameIndex(sample_chars)
>>> index.word_report()
3 SIGN
2 A
2 EURO
2 LATIN
2 LETTER
1 CAPITAL
1 CURRENCY
1 DOLLAR
1 SMALL
>>> index = UnicodeNameIndex()
>>> index.word_report(10)
75821 CJK
75761 IDEOGRAPH
74656 UNIFIED
13196 SYLLABLE
11735 HANGUL
7616 LETTER
2232 WITH
2180 SIGN
2122 SMALL
1709 CAPITAL
Note: characters with names starting with 'CJK UNIFIED IDEOGRAPH'
are indexed with those three words only, excluding the hexadecimal
codepoint at the end of the name.
"""
import sys
import re
import unicodedata
import pickle
import warnings
import itertools
import functools
from collections import namedtuple
RE_WORD = re.compile(r'\w+')
RE_UNICODE_NAME = re.compile('^[A-Z0-9 -]+$')
RE_CODEPOINT = re.compile('U\+([0-9A-F]{4,6})')
INDEX_NAME = 'charfinder_index.pickle'
MINIMUM_SAVE_LEN = 10000
CJK_UNI_PREFIX = 'CJK UNIFIED IDEOGRAPH'
CJK_CMP_PREFIX = 'CJK COMPATIBILITY IDEOGRAPH'
sample_chars = [
'$', # DOLLAR SIGN
'A', # LATIN CAPITAL LETTER A
'a', # LATIN SMALL LETTER A
'\u20a0', # EURO-CURRENCY SIGN
'\u20ac', # EURO SIGN
]
CharDescription = namedtuple('CharDescription', 'code_str char name')
QueryResult = namedtuple('QueryResult', 'count items')
def tokenize(text):
"""return iterable of uppercased words"""
for match in RE_WORD.finditer(text):
yield match.group().upper()
def query_type(text):
text_upper = text.upper()
if 'U+' in text_upper:
return 'CODEPOINT'
elif RE_UNICODE_NAME.match(text_upper):
return 'NAME'
else:
return 'CHARACTERS'
class UnicodeNameIndex:
def __init__(self, chars=None):
self.load(chars)
def load(self, chars=None):
self.index = None
if chars is None:
try:
with open(INDEX_NAME, 'rb') as fp:
self.index = pickle.load(fp)
except OSError:
pass
if self.index is None:
self.build_index(chars)
if len(self.index) > MINIMUM_SAVE_LEN:
try:
self.save()
except OSError as exc:
warnings.warn('Could not save {!r}: {}'
.format(INDEX_NAME, exc))
def save(self):
with open(INDEX_NAME, 'wb') as fp:
pickle.dump(self.index, fp)
def build_index(self, chars=None):
if chars is None:
chars = (chr(i) for i in range(32, sys.maxunicode))
index = {}
for char in chars:
try:
name = unicodedata.name(char)
except ValueError:
continue
if name.startswith(CJK_UNI_PREFIX):
name = CJK_UNI_PREFIX
elif name.startswith(CJK_CMP_PREFIX):
name = CJK_CMP_PREFIX
for word in tokenize(name):
index.setdefault(word, set()).add(char)
self.index = index
def word_rank(self, top=None):
res = [(len(self.index[key]), key) for key in self.index]
res.sort(key=lambda item: (-item[0], item[1]))
if top is not None:
res = res[:top]
return res
def word_report(self, top=None):
for postings, key in self.word_rank(top):
print('{:5} {}'.format(postings, key))
def find_chars(self, query, start=0, stop=None):
stop = sys.maxsize if stop is None else stop
result_sets = []
for word in tokenize(query):
chars = self.index.get(word)
if chars is None: # shortcut: no such word
result_sets = []
break
result_sets.append(chars)
if not result_sets:
return QueryResult(0, ())
result = functools.reduce(set.intersection, result_sets)
result = sorted(result) # must sort to support start, stop
result_iter = itertools.islice(result, start, stop)
return QueryResult(len(result),
(char for char in result_iter))
def describe(self, char):
code_str = 'U+{:04X}'.format(ord(char))
name = unicodedata.name(char)
return CharDescription(code_str, char, name)
def find_descriptions(self, query, start=0, stop=None):
for char in self.find_chars(query, start, stop).items:
yield self.describe(char)
def get_descriptions(self, chars):
for char in chars:
yield self.describe(char)
def describe_str(self, char):
return '{:7}\t{}\t{}'.format(*self.describe(char))
def find_description_strs(self, query, start=0, stop=None):
for char in self.find_chars(query, start, stop).items:
yield self.describe_str(char)
@staticmethod # not an instance method due to concurrency
def status(query, counter):
if counter == 0:
msg = 'No match'
elif counter == 1:
msg = '1 match'
else:
msg = '{} matches'.format(counter)
return '{} for {!r}'.format(msg, query)
def main(*args):
index = UnicodeNameIndex()
query = ' '.join(args)
n = 0
for n, line in enumerate(index.find_description_strs(query), 1):
print(line)
print('({})'.format(index.status(query, n)))
if __name__ == '__main__':
if len(sys.argv) > 1:
main(*sys.argv[1:])
else:
print('Usage: {} word1 [word2]...'.format(sys.argv[0]))
<!-- http_charfinder.html -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Charfinder</title>
</head>
<body>
Examples: {links}
<p>
<form action="/">
<input type="search" name="query" value="{query}">
<input type="submit" value="find"> {message}
</form>
</p>
<table>
{result}
</table>
</body>
</html>
#tcp_charfinder.py
#!/usr/bin/env python3
# BEGIN TCP_CHARFINDER_TOP
import sys
import asyncio
from charfinder import UnicodeNameIndex # <1>
CRLF = b'\r\n'
PROMPT = b'?> '
index = UnicodeNameIndex() # <2>
async def handle_queries(reader, writer): # <3>
while True: # <4>
writer.write(PROMPT) # <5>
await writer.drain() # <6>
data = await reader.readline() # <7>
try:
query = data.decode().strip()
except UnicodeDecodeError: # <8>
query = '\x00'
client = writer.get_extra_info('peername') # <9>
print('Received from {}: {!r}'.format(client, query)) # <10>
if query:
if ord(query[:1]) < 32: # <11>
break
lines = list(index.find_description_strs(query)) # <12>
if lines:
writer.writelines(line.encode() + CRLF for line in lines) # <13>
writer.write(index.status(query, len(lines)).encode() + CRLF) # <14>
await writer.drain() # <15>
print('Sent {} results'.format(len(lines))) # <16>
print('Close the client socket') # <17>
writer.close() # <18>
# END TCP_CHARFINDER_TOP
# BEGIN TCP_CHARFINDER_MAIN
def main(address='127.0.0.1', port=2323): # <1>
port = int(port)
loop = asyncio.get_event_loop()
server_coro = asyncio.start_server(handle_queries, address, port,
loop=loop) # <2>
server = loop.run_until_complete(server_coro) # <3>
host = server.sockets[0].getsockname() # <4>
print('Serving on {}. Hit CTRL-C to stop.'.format(host)) # <5>
try:
loop.run_forever() # <6>
except KeyboardInterrupt: # CTRL+C pressed
pass
print('Server shutting down.')
server.close() # <7>
loop.run_until_complete(server.wait_closed()) # <8>
loop.close() # <9>
if __name__ == '__main__':
main(*sys.argv[1:]) # <10>
# END TCP_CHARFINDER_MAIN
# Mac安装telnet
# brew install telnet
# 运行python脚本,再用telnet连接测试 : telnet localhost 2323
使用aiohttp包编写Web服务器
#!/usr/bin/env python3
import tqdm
import sys
import asyncio
from aiohttp import web
from charfinder import UnicodeNameIndex
TEMPLATE_NAME = 'http_charfinder.html'
CONTENT_TYPE = 'text/html;' # 这里修改过
SAMPLE_WORDS = ('bismillah chess cat circled Malayalam digit'
' Roman face Ethiopic black mark symbol dot'
' operator Braille hexagram').split()
ROW_TPL = '<tr><td>{code_str}</td><th>{char}</th><td>{name}</td></tr>'
LINK_TPL = '<a href="/?query={0}" title="find "{0}"">{0}</a>'
LINKS_HTML = ', '.join(LINK_TPL.format(word) for word in
sorted(SAMPLE_WORDS, key=str.upper))
index = UnicodeNameIndex()
with open(TEMPLATE_NAME) as tpl:
template = tpl.read()
template = template.replace('{links}', LINKS_HTML)
# BEGIN HTTP_CHARFINDER_HOME
def home(request): # <1>
query = request.query_string.split('=')[-1].strip() # <2> 这里修改过
print('Query: {!r}'.format(query)) # <3>
if query: # <4>
descriptions = list(index.find_descriptions(query))
todo_list = tqdm.tqdm(descriptions)
res = '\n'.join(ROW_TPL.format(**descr._asdict())
for descr in todo_list)
msg = index.status(query, len(descriptions))
else:
descriptions = []
res = ''
msg = 'Enter words describing characters.'
html = template.format(query=query, result=res, # <5>
message=msg)
print('Sending {} results'.format(len(descriptions))) # <6>
return web.Response(content_type=CONTENT_TYPE, text=html) # <7>
# END HTTP_CHARFINDER_HOME
# BEGIN HTTP_CHARFINDER_SETUP
async def init(loop, address, port): # <1>
app = web.Application(loop=loop) # <2>
app.router.add_route('GET', '/', home) # <3>
handler = app.make_handler() # <4>
server = await loop.create_server(handler,
address, port) # <5>
return server.sockets[0].getsockname() # <6>
def main(address="127.0.0.1", port=8887):
port = int(port)
loop = asyncio.get_event_loop()
host = loop.run_until_complete(init(loop, address, port)) # <7>
print('Serving on {}. Hit CTRL-C to stop.'.format(host))
try:
loop.run_forever() # <8>
except KeyboardInterrupt: # CTRL+C pressed
pass
print('Server shutting down.')
loop.close() # <9>
if __name__ == '__main__':
main(*sys.argv[1:])
# END HTTP_CHARFINDER_SETUP
动态属性
使用动态属性访问Json
import typing
class FrozenJSON:
"""一个只读接口,使用属性表示法访问JSON类对象 """
def __init__(self, mapping):
self.__data = dict(mapping)
def __getattr__(self, name):
if hasattr(self.__data, name):
return getattr(self.__data, name)
else:
return FrozenJSON.build(self.__data[name])
@classmethod
def build(cls, obj):
if isinstance(obj, typing.Mapping):
return cls(obj)
elif isinstance(obj, typing.MutableSequence):
return [cls.build(item) for item in obj]
else:
return obj
使用 new 方法以灵活的方式创建对象
import typing
class FrozenJSON:
"""一个只读接口,使用属性表示法访问JSON类对象 """
# __new__ 是类方法,第一个参数是类本身,余下的参数与 __init__方法一样,只不过没有 self。
def __new__(cls, arg):
if isinstance(arg, typing.Mapping):
# 默认的行为是委托给超类的 __new__ 方法。这里调用的是 object基类的 __new__ 方法,把唯一的参数设为 FrozenJSON。
return super().__new__(cls)
elif isinstance(arg, typing.MutableSequence):
# __new__ 方法中余下的代码与原先的 build 方法完全一样
return [cls(item) for item in arg]
else:
return arg
def __init__(self, mapping):
self.__data = {}
for key, value in mapping.items():
if iskeyword(key):
key += '_'
self.__data[key] = value
def __getattr__(self, name):
if hasattr(self.__data, name):
return getattr(self.__data, name)
else:
return FrozenJSON(self.__data[name])
特性
使用特性
class LineItem:
def __init__(self, description, weight, price):
self.description = description
# 这里已经使用特性的设值方法了,确保所创建实例的 weight 属性不 能为负值。
self.weight = weight
self.price = price
def subtotal(self):
return self.weight * self.price
# @property 装饰读值方法。
# 实现特性的方法,其名称都与公开属性的名称一样——weight
@property
def weight(self):
# 真正的值存储在私有属性 __weight 中。
return self.__weight
# 被装饰的读值方法有个 .setter 属性,这个属性也是装饰器;这个 装饰器把读值方法和设值方法绑定在一起。
@weight.setter
def weight(self, value):
if value > 0:
# 如果值大于零,设置私有属性 __weight
self.__weight = value
else:
# 否则,抛出 ValueError 异常。
raise ValueError('value must be > 0')
"""
>>> walnuts = LineItem('walnuts', 0, 10.00)
Traceback (most recent call last):
...
ValueError: value must be > 0
"""
特性全解析
property 构造方法的完整签名如下:
property(fget=None, fset=None, fdel=None, doc=None)
如下示例和上面的示例效果一样
class LineItem:
def __init__(self, description, weight, price):
self.description = description
self.weight = weight
self.price = price
def subtotal(self):
return self.weight * self.price
def get_weight(self):
# 普通的读值方法。
return self.__weight
def set_weight(self, value):
# 普通的设值方法。
if value > 0:
self.__weight = value
else:
raise ValueError('value must be > 0')
# 构建 property 对象,然后赋值给公开的类属性
weight = property(get_weight, set_weight)
特性会覆盖实例属性
- 如果实例和所属的类有同名数据属性,那么实例属性会覆 盖(或称遮盖)类属性
- 实例属性不会遮盖类特性
优先级:特性的读值方法 > 实例属性 > 类属性
影响属性处理方式的特殊属性
-
__class__对象所属类的引用(即
obj.__class__与type(obj)的作用相 同)。Python 的某些特殊方法,例如__getattr__,只在对象的类中寻 找,而不在实例中寻找。 -
__dict__一个映射,存储对象或类的可写属性。有
__dict__属性的对象, 任何时候都能随意设置新属性。如果类有 _slots_ 属性,它的实例 可能没有__dict__属性。参见下面对__slots__属性的说明。 -
__slots__类可以定义这个这属性,限制实例能有哪些属性。
__slots__属性 的值是一个字符串组成的元组,指明允许有的属性。如果__slots__中没有__dict__,那么该类的实例没有__dict__属 性,实例只允许有指定名称的属性。
处理属性的内置函数
下述 5 个内置函数对对象的属性做读、写和内省操作。
-
dir([object])列出对象的大多数属性。官方文档 (https://docs.python.org/3/library/functions.html#dir)说,
dir函数的目的 是交互式使用,因此没有提供完整的属性列表,只列出一组“重要的”属 性名。dir函数能审查有或没有__dict__属性的对象。dir函数不会 列出__dict__属性本身,但会列出其中的键。dir函数也不会列出类 的几个特殊属性,例如__mro__、__bases__和__name__。如果没有 指定可选的 object 参数,dir函数会列出当前作用域中的名称。 -
getattr(object, name[, default])从 object 对象中获取 name 字符串对应的属性。获取的属性可能 来自对象所属的类或超类。如果没有指定的属性,
getattr函数抛出AttributeError异常,或者返回default参数的值(如果设定了这 个参数的话)。 -
hasattr(object, name)如果
object对象中存在指定的属性,或者能以某种方式(例如继 承)通过 object 对象获取指定的属性,返回 True。文档 (https://docs.python.org/3/library/functions.html#hasattr)说道:“这个函数 的实现方法是调用getattr(object, name)函数,看看是否抛出AttributeError异常。” -
setattr(object, name, value)
把object对象指定属性的值设为value,前提是object对象能接受那个值。这个函数可能会创建一个新属性,或者覆盖现有的属性。 -
vars([object])返回
object对象的__dict__属性;如果实例所属的类定义了__slots__属性,实例没有__dict__属性,那么vars函数不能处理 那个实例(相反,dir函数能处理这样的实例)。如果没有指定参数, 那么vars()函数的作用与locals()函数一样:返回表示本地作用域的字典。
处理属性的特殊方法
在用户自己定义的类中,下述特殊方法用于获取、设置、删除和列出属性。
使用点号或内置的 getattr、hasattr 和 setattr 函数存取属性都会 触发下述列表中相应的特殊方法。但是,直接通过实例的__dict__属 性读写属性不会触发这些特殊方法——如果需要,通常会使用这种方式 跳过特殊方法。
Python 文档“Data model”一章中的“3.3.9. Special method lookup”一节 (https://docs.python.org/3/reference/datamodel.html#special-method- lookup)警告说:
对用户自己定义的类来说,如果隐式调用特殊方法,仅当特殊方法在对象所属的类型上定义,而不是在对象的实例字典中定义时,才能确保调用成功。
也就是说,要假定特殊方法从类上获取,即便操作目标是实例也是如此。
因此,特殊方法不会被同名实例属性遮盖。
在下述示例中,假设有个名为 Class 的类,obj 是 Class 类的实 例,attr 是 obj 的属性。
不管是使用点号存取属性,还是使用 19.6.2 节列出的某个内置函数,都 会触发下述特殊方法中的一个。例如,obj.attr 和 getattr(obj, 'attr', 42) 都会触发 Class.__getattribute__(obj, 'attr') 方 法。
-
__delattr__(self, name)
只要使用 del 语句删除属性,就会调用这个方法。例如,del obj.attr 语句触发Class.__delattr__(obj, 'attr')方法。 -
__dir__(self)
把对象传给 dir 函数时调用,列出属性。例如,dir(obj)触发Class.__dir__(obj)方法。 -
__getattr__(self, name)仅当获取指定的属性失败,搜索过 obj、Class 和超类之后调用。 表达式
obj.no_such_attr、getattr(obj, 'no_such_attr')和hasattr(obj, 'no_such_attr')可能会触发Class.__getattr__(obj, 'no_such_attr')方法,但是,仅当在 obj、Class 和超类中找不到指定的属性时才会触发。 -
__getattribute__(self, name)尝试获取指定的属性时总会调用这个方法,不过,寻找的属性是特 殊属性或特殊方法时除外。点号与 getattr 和 hasattr 内置函数会触 发这个方法。调用
__getattribute__方法且抛出 AttributeError 异常时,才会调用__getattr__方法。为了在获取 obj 实例的属性时 不导致无限递归,__getattribute__方法的实现要使用super().__getattribute__(obj, name)。 -
__setattr__(self, name, value)尝试设置指定的属性时总会调用这个方法。点号和 setattr 内置 函数会触发这个方法。例如,obj.attr = 42 和 setattr(obj, 'attr', 42) 都会触发
Class.__setattr__(obj, ‘attr’, 42)方 法。
其实,特殊方法__getattribute__和__setattr__不管 怎样都会调用,几乎会影响每一次属性存取,因此比__getattr__方法(只处理不存在的属性名)更难正确使用。与 定义这些特殊方法相比,使用特性或描述符相对不易出错。
描述符

用描述符实现特性中的示例代码
class Quantity:
"""描述符基于协议实现,无需创建子类。"""
def __init__(self, storage_name):
# Quantity 实例有个 storage_name 属性,这是托管实例中存储值的属性的名称。
self.storage_name = storage_name
# 尝试为托管属性赋值时,会调用 __set__ 方法。这里,self 是描述 符实例(即 LineItem.weight 或 LineItem.price),instance 是 托管实例(LineItem 实例),value 是要设定的值。
def __set__(self, instance, value):
if value > 0:
# 这里,必须直接处理托管实例的 __dict__ 属性;如果使用内置的 setattr 函数,会再次触发 __set__ 方法,导致无限递归。
instance.__dict__[self.storage_name] = value
else:
raise ValueError('value must be > 0')
class LineItem:
# 第一个描述符实例绑定给 weight 属性。
weight = Quantity('weight')
# 第二个描述符实例绑定给 price 属性。
price = Quantity('price')
def __init__(self, description, weight, price):
self.description = description
self.weight = weight
self.price = price
def subtotal(self):
return self.weight * self.price
描述符实现特性且自动获取存储属性名称
class Quantity:
# __counter 是 Quantity 类的类属性,统计 Quantity 实例的数量。
__counter = 0
def __init__(self):
# cls 是 Quantity 类的引用
cls = self.__class__
prefix = cls.__name__
index = cls.__counter
# 每个描述符实例的 storage_name 属性都是独一无二的,因为其值 由描述符类的名称和 __counter 属性的当前值构成(例 如,_Quantity#0)。
self.storage_name = '_{}#{}'.format(prefix, index)
# 递增 __counter 属性的值。
cls.__counter += 1
def __get__(self, instance, owner):
"""
注意,__get__ 方法有三个参数:self、instance 和 owner。owner 参数是托管类(如 LineItem)的引用,通过描述符从托管类中获取属 性时用得到。如果使用 LineItem.weight 从类中获取托管属性(以 weight 为例),描述符的 __get__ 方法接收到的 instance 参数值是None,会抛出 AttributeError 异常
"""
if instance is None:
# 如果不是通过实例调用,返回描述符自身
return self
else:
# 我们要实现 __get__ 方法,因为托管属性的名称与 storage_name不同
# 使用内置的 getattr 函数从 instance 中获取储存属性的值。
return getattr(instance, self.storage_name)
def __set__(self, instance, value):
# 使用内置的 setattr 函数把值存储在 instance 中。
if value > 0:
setattr(instance, self.storage_name, value)
else:
raise ValueError('value must be > 0')
class LineItem:
# 现在,不用把托管属性的名称传给 Quantity 构造方法。这是这一版 的目标。
weight = Quantity()
price = Quantity()
def __init__(self, description, weight, price):
self.description = description
self.weight = weight
self.price = price
def subtotal(self):
return self.weight * self.price
"""
>>> from bulkfood_v4 import LineItem
>>> coconuts = LineItem('Brazilian coconut', 20, 17.95)
>>> coconuts.weight, coconuts.price
(20, 17.95)
>>> getattr(coconuts, '_Quantity#0'), getattr(coconuts, '_Quantity#1') (20, 17.95)
"""
特性工厂函数与描述符类比较
使用特性工厂函数实现与描述符类相同的功能
def quantity(): # 没有 storage_name 参数。
try:
# 不能依靠类属性在多次调用之间共享 counter,因此把它定义为 quantity 函数自身的属性。
quantity.counter += 1
except AttributeError:
# 如果 quantity.counter 属性未定义,把值设为 0。
quantity.counter = 0
# 我们也没有实例变量,因此创建一个局部变量 storage_name, 借助闭包保持它的值,供后面的 qty_getter 和 qty_setter 函数 使用。
storage_name = '_{}:{}'.format('quantity', quantity.counter)
def qty_getter(instance):
# 这里可以使用内置的 getattr 和 setattr 函数,而不用处理 instance.__dict__ 属 性。
return getattr(instance, storage_name)
def qty_setter(instance, value):
if value > 0:
setattr(instance, storage_name, value)
else:
raise ValueError('value must be > 0')
return property(qty_getter, qty_setter)
区别
- 描述符类可以使用子类扩展;若想重用工厂函数中的代码,除了复制粘贴,很难有其他方法。
- 与使用函数属性和闭包保持状态相比,在类属性 和实例属性中保持状态更易于理解。
- 从某种程度上来讲,特性工厂函数模式较简单,可是描述符类方式更易扩展,而且应用也更广泛。
多种检验的描述符
import abc
class AutoStorage: # AutoStorage 类提供了之前 Quantity 描述符的大部分功能......
__counter = 0
def __init__(self):
cls = self.__class__
prefix = cls.__name__
index = cls.__counter
self.storage_name = '_{}#{}'.format(prefix, index)
cls.__counter += 1
def __get__(self, instance, owner):
if instance is None:
return self
else:
return getattr(instance, self.storage_name)
def __set__(self, instance, value):
setattr(instance, self.storage_name, value) # ......验证除外
# Validated 是抽象类,不过也继承自 AutoStorage 类
class Validated(abc.ABC, AutoStorage):
def __set__(self, instance, value):
# __set__ 方法把验证操作委托给 validate 方法......
value = self.validate(instance, value)
# ......然后把返回的 value 传给超类的 __set__ 方法,存储值。
super().__set__(instance, value)
@abc.abstractmethod
def validate(self, instance, value):
# 在这个类中,validate 是抽象方法。
"""return validated value or raise ValueError"""
class Quantity(Validated):
# Quantity 和 NonBlank 都继承自 Validated 类。
"""a number greater than zero"""
def validate(self, instance, value):
if value <= 0:
raise ValueError('value must be > 0')
return value
class NonBlank(Validated):
"""a string with at least one non-space character"""
def validate(self, instance, value):
value = value.strip()
if len(value) == 0:
raise ValueError('value cannot be empty or blank')
# 要求具体的 validate 方法返回验证后的值,借机可以清理、转换或 规范化接收的数据。这里,我们把 value 首尾的空白去掉,然后将其 返回。
return value
class LineItem:
description = model.NonBlank() # 使用 model.NonBlank 描述符
weight = model.Quantity()
price = model.Quantity()
def __init__(self, description, weight, price):
self.description = description
self.weight = weight
self.price = price
def subtotal(self):
return self.weight * self.price
覆盖型与非覆盖型描述符对比
写在前面
根据是否定义
__set__方法,描述符可以分为覆盖型和非覆盖型描述符
现有三个类

Overriding类(实现了get和set)
实现__set__方法的描述符属于覆盖型描述符,因为虽然描述符是类 属性,但是实现__set__方法的话,会覆盖对实例属性的赋值操作。

注意看5~8
实现了__get__方法的描述符,会覆盖实例的属性
OverridingNoGet(只实现了__set__方法)
通常,覆盖型描述符既会实现__set__方法,也会实现__get__方 法,不过也可以只实现__set__方法,此时,只有 写操作由描述符处理。通过实例读取描述符会返回描述符对象本身,因 为没有处理读操作的 __get__ 方法。如果直接通过实例的__dict__属性创建同名实例属性,以后再设置那个属性时,仍会由 __set__ 方 法插手接管,但是读取那个属性的话,就会直接从实例中返回新赋予的 值,而不会返回描述符对象。也就是说,实例属性会遮盖描述符,不过 只有读操作是如此。



未实现__get__方法的描述符,获取属性时会被实例的属性所覆盖
NonOverriding非覆盖型描述符(只有__get__方法)
没有实现__set__方法的描述符是非覆盖型描述符。如果设置了同名 的实例属性,描述符会被遮盖,致使描述符无法处理那个实例的那个属 性。方法是以非覆盖型描述符实现的。

方法也是描述符
在类中定义的函数属于绑定方法(bound method),因为用户定义的函 数都有 get 方法,所以依附到类上时,就相当于描述符

obj.spam 和 Managed.spam 获取的是不同的对象。与描述符一样,通过托管类访问 时,函数的__get__方法会返回自身的引用。但是,通过实例访问 时,函数的__get__方法返回的是绑定方法对象:一种可调用的对 象,里面包装着函数,并把托管实例(例如 obj)绑定给函数的第一个 参数(即 self),这与 functools.partial 函数的行为一致
如下例子

>>> word = Text('forward')
>>> word # Text 实例的 repr 方法返回一个类似 Text 构造方法调用的字符串, 可用于创建相同的实例。
Text('forward')
>>> word.reverse() # reverse 方法返回反向拼写的单词。
Text('drawrof')
>>> Text.reverse(Text('backward')) # 在类上调用方法相当于调用函数。
Text('drawkcab')
>>> type(Text.reverse), type(word.reverse) # 注意类型是不同的,一个是 function,一个是 method。
(<class 'function'>, <class 'method'>)
>>> list(map(Text.reverse, ['repaid', (10, 20, 30), Text('stressed')])) ['diaper', (30, 20, 10), Text('desserts')] # Text.reverse 相当于函数,甚至可以处理 Text 实例之外的其他对 象。
>>> Text.reverse.__get__(word) # 函数都是非覆盖型描述符。在函数上调用 __get__ 方法时传入实 例,得到的是绑定到那个实例上的方法。
<bound method Text.reverse of Text('forward')>
>>> Text.reverse.__get__(None, Text) # 调用函数的 __get__ 方法时,如果 instance 参数的值是 None,那 么得到的是函数本身。
<function Text.reverse at 0x101244e18>
>>> word.reverse # word.reverse 表达式其实会调用 Text.reverse.__get__(word),返回对应的绑定方法。
<bound method Text.reverse of Text('forward')>
>>> word.reverse.__self__ # 绑定方法对象有个 __self__ 属性,其值是调用这个方法的实例引 用。
Text('forward')
>>> word.reverse.__func__ is Text.reverse # 绑定方法的 __func__ 属性是依附在托管类上那个原始函数的引用。
True
描述符用法建议
使用特性以保持简单
内置的 property 类创建的其实是覆盖型描述符,__set__ 方法和__get__方法都实现了,即便不定义设值方法也是如此。特性的__set__方法默认抛出 AttributeError: can't set attribute, 因此创建只读属性最简单的方式是使用特性,这能避免下一条所述的问 题。
只读描述符必须有__set__方法
如果使用描述符类实现只读属性,要记住,__get__ 和__set__两个方法必须都定义,否则,实例的同名属性会遮盖描述符。只读属性 的__set__方法只需抛出 AttributeError 异常,并提供合适的错误 消息。
用于验证的描述符可以只有__set__方法
对仅用于验证的描述符来说,__set__ 方法应该检查 value 参数 获得的值,如果有效,使用描述符实例的名称为键,直接在实例的__dict__属性中设置。这样,从实例中读取同名属性的速度很快,因 为不用经过__get__方法处理。
仅有 __get__ 方法的描述符可以实现高效缓存
如果只编写了__get__方法,那么创建的是非覆盖型描述符。这 种描述符可用于执行某些耗费资源的计算,然后为实例设置同名属性, 缓存结果。同名实例属性会遮盖描述符,因此后续访问会直接从实例的
__dict__ 属性中获取值,而不会再触发描述符的__get__方法。
非特殊的方法可以被实例属性遮盖
由于函数和方法只实现了__get__方法,它们不会处理同名实例 属性的赋值操作。因此,像 my_obj.the_method = 7 这样简单赋值之 后,后续通过该实例访问 the_method 得到的是数字 7——但是不影响 类或其他实例。然而,特殊方法不受这个问题的影响。解释器只会在类 中寻找特殊的方法,也就是说,repr(x) 执行的其实是 x.__class__.__repr__(x),因此 x 的__repr__属性对 repr(x) 方 法调用没有影响。出于同样的原因,实例的__getattr__属性不会破 坏常规的属性访问规则。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号