
json好玩的库
一 、DeepDiff
DeepDiff 是一个Python库,用于比较 Python对象的深度差异。能够比较各种数据类型,包括列表、元组、字典、集合、字符串、整数、浮点数等,并给出它们之间的差异。DeepDiff 是提供一种简单且易于理解的方式来比较Python对象的差异。
安装:pip install deepdiff==6.7.1
导入:from deepdiff import DeepDiff
a、对比两个JSON对象的差异
其中 ignore_order=True,是在比较时忽略对象内元素的顺序,以获得更准确的差异比较结果。
from deepdiff import DeepDiff
json1 = {
"country": "china",
"city": "Beijing",
"name": "Wen",
"customer_id": 1001,
"age": 28,
"add_id": 901,
"extra_1": "one",
"extra_2": "B201"
}
json2 = {
"country": "USA",
"city": "Lsj",
"name": "Miko",
"customer_id": 1002,
"age": 26,
"sex": "m",
"add_id": 901,
"extra_1": "n_one",
"extra_2": "n_two",
"extra_3": "n_three"
}
# 比较差异并输出不同的值
diff = DeepDiff(json1, json2, ignore_order=True)
print(diff.to_json())
结果:
{
"dictionary_item_added": ["root['sex']", "root['extra_3']"],
"values_changed": {
"root['country']": {
"new_value": "USA",
"old_value": "china"
},
"root['city']": {
"new_value": "Lsj",
"old_value": "Beijing"
},
"root['name']": {
"new_value": "Miko",
"old_value": "Wen"
},
"root['customer_id']": {
"new_value": 1002,
"old_value": 1001
},
"root['age']": {
"new_value": 26,
"old_value": 28
},
"root['extra_1']": {
"new_value": "n_one",
"old_value": "one"
},
"root['extra_2']": {
"new_value": "n_two",
"old_value": "B201"
}
}
}
b、对比两个字符串的差异
直接使用 DeepDiff(obj1, obj2),默认包含了所有的差异信息。
s1 = "Hello" s2 = "Hello World" diff = DeepDiff(s1, s2) print(diff.to_json())
结果:
{
"values_changed": {
"root": {
"new_value": "Hello World",
"old_value": "Hello"
}
}
}
c、对比两个列表的差异
其中,使用 verbose_level=2,这个方法可以提供更详细的差异信息,包括差异的路径和值。
l1 = [1, 2, 3, 12, 34, 5, 3, 2] l2 = [1, 2, 5, 12, 34, 234, 3, 2, 100] diff1 = DeepDiff(l1, l2, verbose_level=2) print(diff1.to_json())
结果:
{
"values_changed": {
"root[2]": {
"new_value": 5,
"old_value": 3
},
"root[5]": {
"new_value": 234,
"old_value": 5
}
},
"iterable_item_added": {
"root[8]": 100
}
}
其他的类型对比,如元组、集合、整数、浮点数等,都可以进行对比差异,实现方式同上。
对于输出结果,除了输出json格式,还可以输出以树形结构展示差异,比如两个列表差异输出:
print(diff1.tree)
结果:
{
'values_changed': [ < root[2] t1: 3, t2: 5 > , < root[5] t1: 5, t2: 234 > ],
'iterable_item_added': [ < root[8] t1: not present, t2: 100 > ]
}
二 、joblib
joblib 是Python中一个非常厉害的第三方库,用于提供高效的对象持久化(序列化)和并行计算的功能。它可以用于缓存计算结果、并行执行任务、分布式计算等场景。
安装:pip install joblib==1.3.2
a、对象持久化
将Python对象保存到磁盘文件,以便后续重用。它支持对NumPy数组、Pandas数据框等常见数据结构的持久化。
将上面Json对比差异的结果保存到文件
from joblib import dump, load
# 保存对象到文件
data = {
"values_changed": {
"root[2]": {
"new_value": 5,
"old_value": 3
},
"root[5]": {
"new_value": 234,
"old_value": 5
}
},
"iterable_item_added": {
"root[8]": 100
}
}
dump(value=data, filename='data.joblib')
在当前目录下,自动创建了data.joblib,后面需要用的时候,可以直接从这里面取。
loaded_data = load('data.joblib')
print("获取JSON对比结果:\n", loaded_data)
b、缓存函数
首先,创建一个内存缓存对象
from joblib import Memory memory = Memory(location='cache_directory')
可以看到当前目录下,自动创建了cache_directory文件夹
然后,定义一个需要缓存的函数
@memory.cache
def cache_function(x):
result = x * x
return result
最后调用
result1 = cache_function(10) result2 = cache_function(11) print(result1) print(result2)
结果:
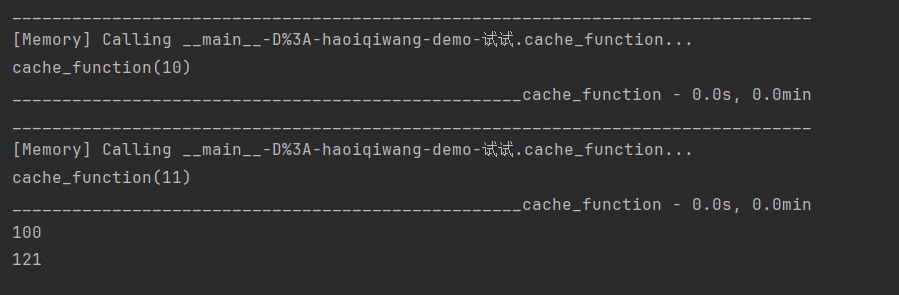
第一次执行,是将函数缓存,并得到结果。再运行一次,就是从只会显示两个结果:

说明已经缓存成功,后面都是调用缓存中的函数了!
c、并行执行任务
joblib 提供了简单的接口来并行执行任务。可以自动将任务分解为多个子任务,并利用多核CPU或分布式计算资源进行并行计算。
from joblib import Parallel, delayed
# 定义一个需要并行执行的任务
def square(x):
return x + 2
# 并行计算任务
results = Parallel(n_jobs=2)(delayed(square)(i) for i in range(20))
print(results)
结果:

使用Parallel类来并行执行该任务,其中:
n_jobs:参数指定了要使用的工作进程数(本示例中为2,即为启用两个进程来执行任务)
delayed:是装饰器,用于指定要并行执行的函数和参数
结果很清晰,但需要注意的是并行执行任务时可能会涉及到数据共享和同步的问题,需要根据具体情况进行适当的处理,以确保并行执行的正确性和效率。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号