Scrapy爬虫框架与常用命令
07.08自我总结
一.Scrapy爬虫框架
大体框架
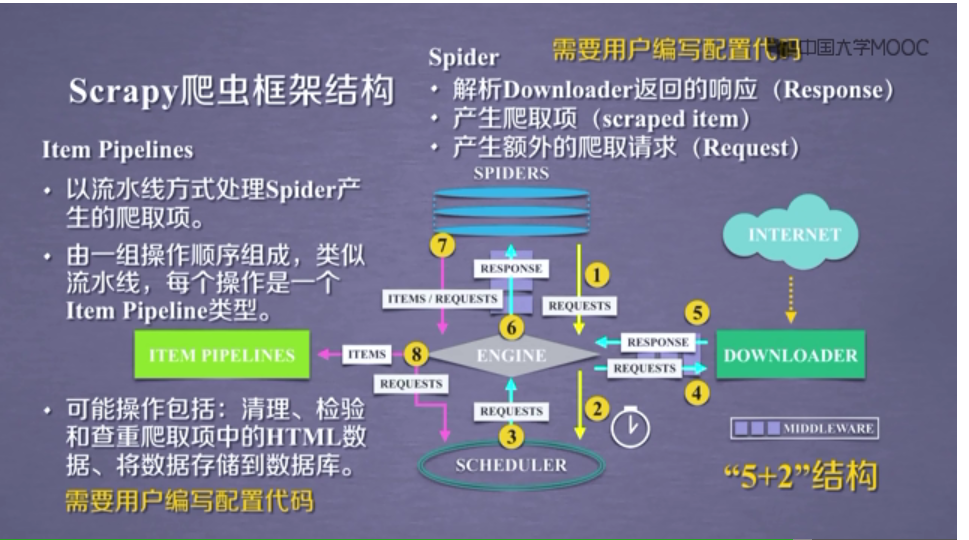
2个桥梁


二.常用命令
全局命令
-
startproject
语法:
scrapy startproject <project_name>这个命令是scrapy最为常用的命令之一,它将会在当前目录下创建一个名为
<project_name>的项目。 -
settings
语法:
scrapy settings [options]该命令将会输出Scrapy默认设定,当然如果你在项目中运行这个命令将会输出项目的设定值。
-
runspider
语法:
scrapy runspider <spider_file.py>在未创建项目的情况下,运行一个编写在Python文件中的spider。
-
shell
语法:
scrapy shell [url]以给定的URL(如果给出)或者空(没有给出URL)启动Scrapy shell。
例如,
scrapy shell http://www.baidu.com将会打开百度URL,
并且启动交互式命令行,可以用来做一些测试。
-
fetch
语法:
scrapy fetch <url>使用Scrapy下载器(downloader)下载给定的URL,并将获取到的内容送到标准输出。简单的来说,就是打印url的html代码。
-
view
语法:
scrapy view <url>在你的默认浏览器中打开给定的URL,并以Scrapy spider获取到的形式展现。 有些时候spider获取到的页面和普通用户看到的并不相同,一些动态加载的内容是看不到的, 因此该命令可以用来检查spider所获取到的页面。
-
version
语法:
scrapy version [-v]输出Scrapy版本。配合 -v 运行时,该命令同时输出Python, Twisted以及平台的信息。
项目命令
-
crawl
语法:
scrapy crawl <spider_name>使用你项目中的spider进行爬取,即启动你的项目。这个命令将会经常用到,我们会在后面的内容中经常使用。
-
check
语法:
crapy check [-l] <spider>运行contract检查,检查你项目中的错误之处。
-
list
语法:
scrapy list列出当前项目中所有可用的spider。每行输出一个spider。
-
genspider
语法:
scrapy genspider [-t template] <name> <domain>在当前项目中创建spider。该方法可以使用提前定义好的模板来生成spider。您也可以自己创建spider的源码文件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号