
流畅的python——11 接口:从协议到抽象基类
十一、接口:从协议到抽象基类
抽象类表示接口。 ——Bjarne Stroustrup C++ 之父
从鸭子类型的代表特征动态协议,到使接口更明确、能验证实现是否符合规定的抽象基类(Abstract Base Class, ABC)
我们把协议定义为非正式的接口,是让 python 这种动态类型语言实现多态的方式。
按照定义,受保护的属性和私有属性不在接口中:即便“受保护的”属性也只是采用命名约定实现的(单个前导下划线);私有属性可以轻松地访问,原因也是如此。不要违背这些约定。
另一方面,不要觉得把公开数据属性放入对象的接口中不妥,因为如果需要,总能实现读值方法和设值方法,把数据属性变成特性,使用 obj.attr 句法的客户代码不会受到影响。
对象公开方法的子集,让对象在系统中扮演特定的角色。
接口是实现特定角色的方法集合,协议与继承没有关系。一个类可能会实现多个接口,从而让实例扮演多个角色。
一个类可能只实现部分接口,这是允许的。有时,某些 API 只要求“文件类对象”返回字节序列的 .read() 方法。在特定的上下文中可能需要其他文件操作方法,也可能不需要。
对 Python 程序员来说,“X 类对象”“X 协议”和“X 接口”都是一个意思。
python 喜欢序列
Python 数据模型的哲学是尽量支持基本协议。对序列来说,即便是最简单的实现,Python 也会力求做到最好。
定义 __getitem__ 方法,只实现序列协议的一部分,这样足够访问元素、迭代和使用 in 运算符了
>>> class Foo:
... def __getitem__(self, pos):
... return range(0, 30, 10)[pos]
...
>>> f = Foo()
>>> f[1]
10
>>> for i in f: print(i)
...
0
10
20
>>> 20 in f
True
>>> 15 in f
False
虽然没有 __iter__ 方法,但是 Foo 实例是可迭代的对象,因为发现有 __getitem__ 方法时,Python 会调用它,传入从 0 开始的整数索引,尝试迭代对象(这是一种后备机制)。
尽管没有实现 __contains__ 方法,但是 Python 足够智能,能迭代 Foo 实例,因此也能使用 in 运算符:Python 会做全面检查,看看有没有指定的元素。
综上,鉴于序列协议的重要性,如果没有 __iter__ 和 __contains__ 方法,Python 会调用 __getitem__ 方法,设法让迭代和 in 运算符可用。
第 1 章那些示例之所以能用,大部分是由于 Python 会特殊对待看起来像是序列的对象。Python 中的迭代是鸭子类型的一种极端形式:为了迭代对象,解释器会尝试调用两个不同的方法。
使用猴子补丁在运行时实现协议
In [7]: from random import shuffle
In [9]: class F:
...: ranks = [str(n) for n in range(2,11)] + list('JQKA')
...: suits = 'spades diamonds clubs hearts'.split()
...: def __init__(self):
...: self._cards = [Card(rank, suit) for rank in self.ranks for suit in self.suits]
...: def __len__(self):
...: return len(self._cards)
...: def __getitem(self, pos):
...: return self._cards(pos)
...:
In [10]: f = F()
In [11]: shuffle(f) # 没有实现 __setitem__ 所以报错,不仅仅是这样注意 方法是 __getitem__ 不是上面写的 __getitem 私有方法
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-11-4f8bc820702d> in <module>
----> 1 shuffle(f)
d:\python36\lib\random.py in shuffle(self, x, random)
275 # pick an element in x[:i+1] with which to exchange x[i]
276 j = randbelow(i+1)
--> 277 x[i], x[j] = x[j], x[i]
278 else:
279 _int = int
TypeError: 'F' object does not support indexing
为 类 打猴子补丁,支持 shuffle
In [18]: F.__dict__
Out[18]:
mappingproxy({'__module__': '__main__',
'ranks': ['2',
'3',
'4',
'5',
'6',
'7',
'8',
'9',
'10',
'J',
'Q',
'K',
'A'],
'suits': ['spades', 'diamonds', 'clubs', 'hearts'],
'__init__': <function __main__.F.__init__(self)>,
'__len__': <function __main__.F.__len__(self)>,
'_F__getitem': <function __main__.F.__getitem(self, pos)>, # 私有方法:__getitem 不是特殊方法:__getitem__
'__dict__': <attribute '__dict__' of 'F' objects>,
'__weakref__': <attribute '__weakref__' of 'F' objects>,
'__doc__': None,
'__setitem__': <function __main__.set_card(deck, pos, card)>})
In [19]: F._F__setitem = set_card
In [20]: f = F()
In [21]: shuffle(f)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-21-4f8bc820702d> in <module>
----> 1 shuffle(f)
d:\python36\lib\random.py in shuffle(self, x, random)
275 # pick an element in x[:i+1] with which to exchange x[i]
276 j = randbelow(i+1)
--> 277 x[i], x[j] = x[j], x[i]
278 else:
279 _int = int
TypeError: 'F' object does not support indexing
# 猴子补丁
In [12]: def set_card(deck, pos, card):
...: deck._cards[pos] = card
...:
In [13]: F.__setitem__ = set_card
In [26]: def get_card(deck, pos):
...: return deck._cards[pos]
...:
In [27]: F.__getitem__ = get_card
每个 Python 方法说到底都是普通函数,把第一个参数命名为 self 只是一种约定。
这里的关键是,set_card 函数要知道 deck 对象有一个名为 _cards 的属性,而且 _cards 的值必须是可变序列。然后,我们把 set_card 函数赋值给特殊方法 __setitem__,从而把它依附到 FrenchDeck 类上。这种技术叫猴子补丁:在运行时修改类或模块,而不改动源码。猴子补丁很强大,但是打补丁的代码与要打补丁的程序耦合十分紧密,而且往往要处理隐藏和没有文档的部分。
除了举例说明猴子补丁之外,示例 11-6 还强调了协议是动态的:random.shuffle 函数不关心参数的类型,只要那个对象实现了部分可变序列协议即可。即便对象一开始没有所需的方法也没关系,后来再提供也行。
**Alex Martelli **的水禽
忽略对象的真正类型,转而关注对象有没有实现所需的方法、签名和语义
对 Python 来说,这基本上是指避免使用 isinstance 检查对象的类型(更别提 type(foo) is bar 这种更糟的检查方式了,这样做没有任何好处,甚至禁止最简单的继承方式)。
白鹅类型指,只要 cls 是抽象基类,即 cls 的元类是 abc.ABCMeta,就可以使用 isinstance(obj, cls)。
与具体类相比,抽象基类有很多理论上的优点(例如,参阅 Scott Meyer 写的《More Effective C++:35 个改善编程与设计的有效方法(中文版)》的“条款 33:将非尾端类设计为抽象类”,英文版见 http://ptgmedia.pearsoncmg.com/images/020163371x/items/item33.html),Python 的抽象基类还有一个重要的实用优势:可以使用 register 类方法在终端用户的代码中把某个类“声明”为一个抽象基类的“虚拟”子类(为此,被注册的类必须满足抽象基类对方法名称和签名的要求,最重要的是要满足底层语义契约;但是,开发那个类时不用了解抽象基类,更不用继承抽象基类)。这大大地打破了严格的强耦合,与面向对象编程人员掌握的知识有很大出入,因此使用继承时要小心。
有时,为了让抽象基类识别子类,甚至不用注册。
其实,抽象基类的本质就是几个特殊方法。例如:
>>> class Struggle:
... def __len__(self): return 23
...
>>> from collections import abc
>>> isinstance(Struggle(), abc.Sized)
True
可以看出,无需注册,abc.Sized 也能把 Struggle 识别为自己的子类,只要实现了特殊方法 __len__ 即可(要使用正确的句法和语义实现,前者要求没有参数,后者要求返回一个非负整数,指明对象的长度;如果不使用规定的句法和语义实现特殊方法,如 __len__,会导致非常严重的问题)。
最后我想说的是:如果实现的类体现了 numbers、collections.abc 或其他框架中抽象基类的概念,要么继承相应的抽象基类(必要时),要么把类注册到相应的抽象基类中。开始开发程序时,不要使用提供注册功能的库或框架,要自己动手注册;如果必须检查参数的类型(这是最常见的),例如检查是不是“序列”,那就这样做:
isinstance(the_arg, collections.abc.Sequence)
此外,不要在生产代码中定义抽象基类(或元类)……如果你很想这样做,我打赌可能是因为你想“找茬”,刚拿到新工具的人都有大干一场的冲动。如果你能避开这些深奥的概念,你(以及未来的代码维护者)的生活将更愉快,因为代码会变得简洁明了。再会!
除了提出“白鹅类型”之外,Alex 还指出,继承抽象基类很简单,只需要实现所需的方法,这样也能明确表明开发者的意图。这一意图还能通过注册虚拟子类来实现。
此外,使用 isinstance 和 issubclass 测试抽象基类更为人接受。过去,这两个函数用来测试鸭子类型,但用于抽象基类会更灵活。毕竟,如果某个组件没有继承抽象基类,事后还可以注册,让显式类型检查通过。
然而,即便是抽象基类,也不能滥用 isinstance 检查,用得多了可能导致代码异味,即表明面向对象设计得不好。在一连串 if/elif/elif 中使用 isinstance 做检查,然后根据对象的类型执行不同的操作,通常是不好的做法;此时应该使用多态,即采用一定的方式定义类,让解释器把调用分派给正确的方法,而不使用 if/elif/elif 块硬编码分派逻辑。
具体使用时,上述建议有一个常见的例外:有些 Python API 接受一个字符串或字符串序列;如果只有一个字符串,可以把它放到列表中,从而简化处理。因为字符串是序列类型,所以为了把它和其他不可变序列区分开,最简单的方式是使用 isinstance(x, str) 检查。
可惜,在 Python 3.4 中没有能把字符串和元组或其他不可变序列区分开的抽象基类,因此必须测试 str。在 Python 2中,basestr 类型可以协助这样的测试。basestr 不是抽象基类,但它是 str 和 unicode 的超类;然而,Python 3 把basestr 去掉了。奇怪的是,Python 3 中有个 collections.abc.ByteString 类型,但是它只能检测 bytes 和bytearray 类型。
另一方面,如果必须强制执行 API 契约,通常可以使用 isinstance 检查抽象基类。“老兄,如果你想调用我,必须实现这个”,正如本书技术审校 Lennart Regebro 所说的。这对采用插入式架构的系统来说特别有用。在框架之外,鸭子类型通常比类型检查更简单,也更灵活。
模仿 collections.namedtuple 处理 field_names 参数的方式也是一例:field_names 的值可以是单个字符串,以空格或逗号分隔标识符,也可以是一个标识符序列。此时可能想使用 isinstance,但我会使用鸭子类型
使用鸭子类型处理单个字符串或由字符串组成的可迭代对象:
try: # 假设是单个字符串(EAFP 风格,即“取得原谅比获得许可容易”)
field_names = field_names.replace(',', ' ').split()
except AttributeError:
pass
field_names = tuple(field_names)
在那篇短文的最后,Alex 多次强调,要抑制住创建抽象基类的冲动。滥用抽象基类会造成灾难性后果,表明语言太注重表面形式,这对以实用和务实著称的 Python 可不是好事。在审阅本书的过程中,Alex 写道:
抽象基类是用于封装框架引入的一般性概念和抽象的,例如“一个序列”和“一个确切的数”。(读者)基本上不需要自己编写新的抽象基类,只要正确使用现有的抽象基类,就能获得 99.9% 的好处,而不用冒着设计不当导致的巨大风险。
定义抽象基类的子类
继承了抽象基类,必须实现抽象基类要求的抽象方法。
collections.abc 中的抽象基类
标准库中有两个名为 abc 的模块,这里说的是 collections.abc。
为了减少加载时间,Python 3.4 在 collections 包之外实现这个模块,因此要与 collections 分开导入。
另一个 abc 模块就是 abc,这里定义的是 abc.ABC类。每个抽象基类都依赖这个类,但是不用导入它,除非定义新抽象基类。
Python 3.4 在 collections.abc 模块中定义了 16 个抽象基类。collections.abc 的官方文档中有个不错的表格(https://docs.python.org/3/library/collections.abc.html#collections-abstract-base-classes),对各个抽象基类做了总结,说明了相互之间的关系,以及各个基类提供的抽象方法和具体方法(称为“混入方法”)。图中有很多多重继承。
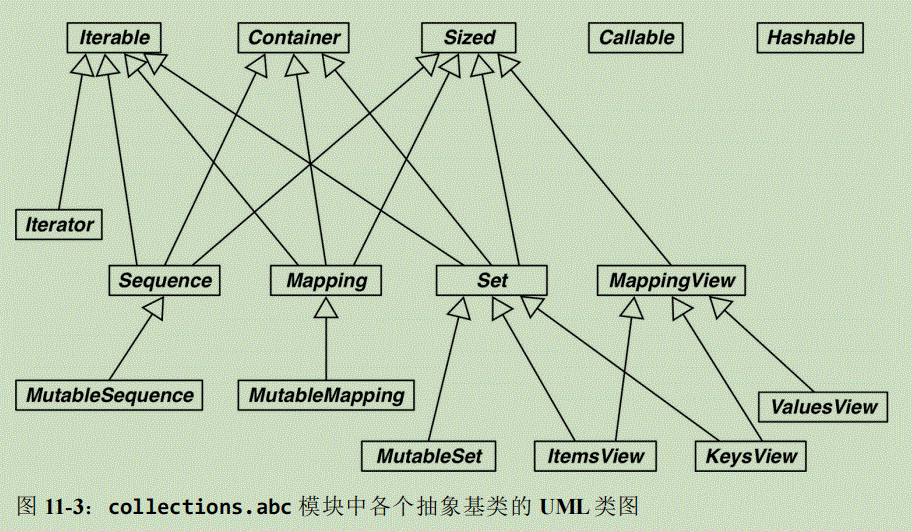
Iterable、Container 和 Sized
各个集合应该继承这三个抽象基类,或者至少实现兼容的协议。Iterable 通过 __iter__ 方法支持迭代,Container 通过 __contains__ 方法支持 in 运算符,Sized通过 __len__ 方法支持 len() 函数。
Sequence、Mapping 和 Set
这三个是主要的不可变集合类型,而且各自都有可变的子类。
MappingView
在 Python 3 中,映射方法 .items()、.keys() 和 .values() 返回的对象分别是 ItemsView、KeysView 和 ValuesView 的实例。前两个类还从 Set 类继承了丰富的接口,包含 3.8.3 节所述的全部运算符。
Callable 和 Hashable
这两个抽象基类与集合没有太大的关系,只不过因为 collections.abc 是标准库中定义抽象基类的第一个模块,而它们又太重要了,因此才把它们放到 collections.abc模块中。我从未见过 Callable 或 Hashable 的子类。这两个抽象基类的主要作用是为内置函数 isinstance 提供支持,以一种安全的方式判断对象能不能调用或散列。
若想检查是否能调用,可以使用内置的 callable() 函数;但是没有类似的 hashable() 函数,因此测试对象是否可散列,最好使用 isinstance(my_obj, Hashable)。
Iterator
注意它是 Iterable 的子类。
抽象基类的金字塔
numbers 包 定义的是“数字塔”:
Number
Complex
Real
Rational
Integral
检查一个数是不是整数:int , bool (int的子类)
为了满足检查的需要,你或者你的 API 的用户始终可以把兼容的类型注册为 numbers.Integral 的虚拟子类。
isinstance(x, numbers.Integral) # 检查 是否为整形
isinstance(x, numbers.Real) # 检查 是否为浮点型
In [32]: isinstance(True , int)
Out[32]: True
In [34]: 0 == False
Out[34]: True
In [35]: 1 == True
Out[35]: True
In [36]: 1 is True
Out[36]: False
In [37]: 0 is False
Out[37]: False
In [38]: 2 == True
Out[38]: False
decimal.Decimal 没有注册为 numbers.Real 的虚拟子类,这有点奇怪。没注册的原因是,如果你的程序需要 Decimal 的精度,要防止与其他低精度数字类型混淆,尤其是浮点数。
定义并使用一个抽象基类
import abc
class Tombola(abc.ABC):
@abc.abstractmethod # 抽象方法使用 @abstractmethod 装饰器标记,而且定义体中通常只有文档字符串。
def load(self, iterable):
"""从可迭代对象中添加元素。"""
@abc.abstractmethod
def pick(self): # 根据文档字符串,如果没有元素可选,应该抛出 LookupError。
"""随机删除元素,然后将其返回。如果实例为空,这个方法应该抛出`LookupError`。
"""
def loaded(self): # 抽象基类可以包含具体方法。
"""如果至少有一个元素,返回`True`,否则返回`False`。"""
# 抽象基类中的具体方法只能依赖抽象基类定义的接口(即只能使用抽象基类中的其他具体方法、抽象方法或特性)。
return bool(self.inspect())
def inspect(self):
"""返回一个有序元组,由当前元素构成。"""
items = []
while True:
try:
items.append(self.pick())
except LookupError:
break
self.load(items)
return tuple(sorted(items))
在抽象基类出现之前,抽象方法使用 raise NotImplementedError 语句表明由子类负责实现。
其实,抽象方法可以有实现代码。即便实现了,子类也必须覆盖抽象方法,但是在子类中可以使用 super() 函数调用抽象方法,为它添加功能,而不是从头开始实现。@abstractmethod 装饰器的用法参见 abc 模块的文档(https://docs.python.org/3/library/abc.html)。
抽象基类:定义不报错,只有实例化对象的时候,会检查是否实现接口。
抽象基类句法详解
声明抽象基类最简单的方式是继承 abc.ABC 或其他抽象基类。
旧版 Python,那么无法继承现有的抽象基类。此时,必须在 class 语句中使用 metaclass= 关键字,把值设为abc.ABCMeta(不是 abc.ABC)。
class Tombola(metaclass=abc.ABCMeta):
# ...
metaclass= 关键字参数是 Python 3 引入的。在 Python 2 中必须使用 __metaclass__ 类属性:
class Tombola(object): # 这是Python 2!!!
__metaclass__ = abc.ABCMeta
# ...
“常规的”类不会检查子类,因此这是抽象基类的特殊行为。
除了 @abstractmethod 之外,abc 模块还定义了 @abstractclassmethod、@abstractstaticmethod 和 @abstractproperty 三个装饰器。然而,后三个装饰器从 Python 3.3 起废弃了,因为装饰器可以在 @abstractmethod上堆叠,那三个就显得多余了。例如,声明抽象类方法的推荐方式是:
class MyABC(abc.ABC):
@classmethod
@abc.abstractmethod
def an_abstract_classmethod(cls, ...):
pass
在函数上堆叠装饰器的顺序通常很重要,@abstractmethod 的文档就特别指出:与其他方法描述符一起使用时,abstractmethod() 应该放在最里层,也就是说,在 @abstractmethod 和 def 语句之间不能有其他装饰器。
只要是可迭代对象,就可以用 list 统一转为 列表:鸭子类型
register 虚拟子类
白鹅类型的一个基本特性(也是值得用水禽来命名的原因):即便不继承,也有办法把一个类注册为抽象基类的虚拟子类。这样做时,我们保证注册的类忠实地实现了抽象基类定义的接口,而 Python 会相信我们,从而不做检查。如果我们说谎了,那么常规的运行时异常会把我们捕获。
注册虚拟子类的方式是在抽象基类上调用 register 方法。这么做之后,注册的类会变成抽象基类的虚拟子类,而且 issubclass 和 isinstance 等函数都能识别,但是注册的类不会从抽象基类中继承任何方法或属性。
虚拟子类不会继承注册的抽象基类,而且任何时候都不会检查它是否符合抽象基类的接口,即便在实例化时也不会检查。为了避免运行时错误,虚拟子类要实现所需的全部方法。
from random import randrange
from tombola import Tombola
@Tombola.register # 注册为 TObola 的虚拟子类
class TomboList(list): # list 的真实子类
def pick(self):
if self: # 继承的 __bool__ 方法
position = randrange(len(self))
return self.pop(position) # 继承的 pop 方法
else:
raise LookupError('pop from empty TomboList')
load = list.extend # load 与 extend 方法一样
def loaded(self):
return bool(self) # 委托 bool 方法
def inspect(self):
return tuple(sorted(self))
# 如果是 Python 3.3 或之前的版本,不能把 .register 当作类装饰器使用,必须使用标准的调用句法。
# Tombola.register(TomboList)
loaded 方法不能采用 load 方法的那种方式,因为 list 类型没有实现 loaded 方法所需的 __bool__ 方法。而内置的 bool 函数不需要 __bool__ 方法,因为它还可以使用 __len__ 方法。参见 Python 文档中“Built-in Types”一章中的“4.1. Truth Value Testing”(https://docs.python.org/3/library/stdtypes.html#truth)。
In [39]: list.__bool__
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-39-7c6164c98ea1> in <module>
----> 1 list.__bool__
AttributeError: type object 'list' has no attribute '__bool__'
注册之后,可以使用 issubclass 和 isinstance 函数判断 TomboList 是不是 Tombola的子类:
>>> from tombola import Tombola
>>> from tombolist import TomboList
>>> issubclass(TomboList, Tombola)
True
>>> t = TomboList(range(100))
>>> isinstance(t, Tombola)
True
然而,类的继承关系在一个特殊的类属性中指定—— __mro__,即方法解析顺序(Method Resolution Order)。这个属性的作用很简单,按顺序列出类及其超类,Python 会按照这个顺序搜索方法。
In [40]: list.__mro__
Out[40]: (list, object)
虚拟子类没有继承虚拟父类的任何方法,所以,也不会去查找方法。
Tombola 子类的测试方法
__subclasses__()
返回类的直接子类列表,不含虚拟子类。
_abc_registry
抽象基类的数据属性,其值是一个 WeakSet 对象,即抽象类注册的虚拟子类的弱引用。
doctest 模块
抽象基类 使用 register 的方式
统一注册虚拟子类,比如,其他文件中定义的类。
Sequence.register(tuple)
Sequence.register(str)
Sequence.register(range)
Sequence.register(memoryview)
鹅的行为有可能像鸭子
即便不注册,抽象基类也能把一个类识别为虚拟子类。
>>> class Struggle:
... def __len__(self): return 23
...
>>> from collections import abc
>>> isinstance(Struggle(), abc.Sized)
True
>>> issubclass(Struggle, abc.Sized)
True
abc.Sized 实现了一个特殊类方法,__subclasshook__
class Sized(metaclass=ABCMeta):
__slots__ = ()
@abstractmethod
def __len__(self):
return 0
@classmethod
def __subclasshook__(cls, C):
if cls is Sized:
if any("__len__" in B.__dict__ for B in C.__mro__):
return True
return NotImplemented
如果你对子类检查的细节感兴趣,可以阅读 Lib/abc.py 文件中 ABCMeta.__subclasscheck__ 方法的源码(https://hg.python.org/cpython/file/3.4/Lib/abc.py#l194)。提醒:源码中有很多 if 语句和两个递归调用。
__subclasshook__ 在白鹅类型中添加了一些鸭子类型的踪迹。我们可以使用抽象基类定义正式接口,可以始终使用 isinstance 检查,也可以完全使用不相关的类,只要实现特定的方法即可(或者做些事情让 __subclasshook__ 信服)。当然,只有提供__subclasshook__ 方法的抽象基类才能这么做。
在自己定义的抽象基类中要不要实现 __subclasshook__ 方法呢?可能不需要。我在Python 源码中只见到 Sized 这一个抽象基类实现了 __subclasshook__ 方法,而 Sized只声明了一个特殊方法,因此只用检查这么一个特殊方法。鉴于 __len__ 方法的“特殊性”,我们基本可以确定它能做到该做的事。但是对其他特殊方法和基本的抽象基类来说,很难这么肯定。例如,虽然映射实现了 __len__、__getitem__ 和 __iter__,但是不应该把它们视作 Sequence 的子类型,因为不能使用整数偏移值获取元素,也不能保证元素的顺序。当然,OrderedDict 除外,它保留了插入元素的顺序,但是不支持通过偏移获取元素。
方法类似,但是实现不同,表现不同。不能确定为子类,最好继承,至少也要注册。
本章首先介绍了非正式接口(称为协议)的高度动态本性,然后讲解了抽象基类的静态接口声明,最后指出了抽象基类的动态特性:虚拟子类,以及使用 __subclasshook__ 方法动态识别子类。
尽管抽象基类使得类型检查变得更容易了,但不应该在程序中过度使用它。Python 的核心在于它是一门动态语言,它带来了极大的灵活性。如果处处都强制实行类型约束,那么会使代码变得更加复杂,而本不应该如此。我们应该拥抱 Python 的灵活性。
或者,像本书技术审校 Leonardo Rochael 所写的:“如果觉得自己想创建新的抽象基类,先试着通过常规的鸭子类型来解决问题。”
强类型和弱类型
如果一门语言很少隐式转换类型,说明它是强类型语言;如果经常这么做,说明它是弱类型语言。Java、C++ 和 Python 是强类型语言。PHP、JavaScript 和 Perl 是弱类型语言。
静态类型和动态类型
在编译时检查类型的语言是静态类型语言,在运行时检查类型的语言是动态类型语言。静态类型需要声明类型(有些现代语言使用类型推导避免部分类型声明)。Fortran 和 Lisp 是最早的两门语言,现在仍在使用,它们分别是静态类型语言和动态类型语言。
静态类型使得一些工具(编译器和 IDE)便于分析代码、找出错误和提供其他服务(优化、重构,等等)。动态类型便于代码重用,代码行数更少,而且能让接口自然成为协议而不提早实行。
Python 不允许为内置类型打猴子补丁。其实我觉得这是优点,因为这样可以确保 str 对象的方法始终是那些。这一局限能减少外部库打的补丁有冲突的概率。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号