
流畅的python——3 字典和集合
三、字典和集合
可散列类型:如果一个对象是可散列的,那么在这个对象的生命周期中,它的散列值是不变的。而且这个对象需要实现__hash__() 方法,还要有 __qe__() 方法,这样才能与其他键作比较。如果两个可散列对象是相等的,那么它们的散列值一定是一样的。
In [103]: a = (1,2,(2,3))
In [104]: hash(a)
Out[104]: 1097636502276347782
In [105]: b = (1,2,[2,3])
In [106]: hash(b)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-106-ad85d8b55702> in <module>
----> 1 hash(b)
TypeError: unhashable type: 'list'
In [107]: c = (1,2,frozenset([2,3]))
In [108]: hash(c)
Out[108]: 3492905854782506582
“Python 里所有的不可变类型都是可散列的”。这个说法其实是不准确的,比如虽然元组本身是不可变序列,它里面的元素可能是其他可变类型的引用
一般来讲用户自定义的类型的对象都是可散列的,散列值就是它们的 id() 函数的返回值,所以所有这些对象在比较的时候都是不相等的。如果一个对象实现了 __eq__方法,并且在方法中用到了这个对象的内部状态的话,那么只有当所有这些内部状态都是不可变的情况下,这个对象才是可散列的。
声明字典的各种方式
>>> a = dict(one=1, two=2, three=3)
>>> b = {'one': 1, 'two': 2, 'three': 3}
>>> c = dict(zip(['one', 'two', 'three'], [1, 2, 3]))
>>> d = dict([('two', 2), ('one', 1), ('three', 3)])
>>> e = dict({'three': 3, 'one': 1, 'two': 2})
>>> a == b == c == d == e
True
字典推导
In [122]: k_v = [('a',1),('b',2)]
In [124]: {k:v for k,v in k_v} # 字典推导
Out[124]: {'a': 1, 'b': 2}
In [125]: dict(k_v)
Out[125]: {'a': 1, 'b': 2}
update 方法,典型的 鸭子类型。函数首先检查 m 中是否有 keys 方法,如果有,就当做映射对象处理。否则,会把 m 当做包含了键值对 (key,vale) 元素的迭代器。
Python 里大多数
映射类型的构造方法都采用了类似的逻辑,因此你既可以用一个映射对象来新建一个映射对象,也可以用包含 (key, value) 元素的可迭代对象来初始化一个映射对象。
setdefault 方法
当字典 d[k] 不能找到正确的键的时候,Python 会抛出异常,这个行为符合 Python 所信奉的“快速失败”哲学。也许每个 Python 程序员都知道可以用 d.get(k, default) 来代替d[k],给找不到的键一个默认的返回值(这比处理 KeyError 要方便不少)。但是要更新某个键对应的值的时候,不管使用 getitem 还是 get 都会不自然,而且效率低。
如下:第二种更好
occurrences = index.get(word, [])
occurrences.append(location)
index[word] = occurrences
index.setdefault(word, []).append(location)
if key not in my_dict:
my_dict[key] = []
my_dict[key].append(new_value)
映射的弹性键查询
查询某个键不存在,希望得到默认值:
1 通过 defaultdict 类型
2 定义 dict 子类,定义 __missing__ 方法
defaultdict:处理找不到的键的一个选择
In [22]: import collections
In [23]: index = collections.defaultdict(list) # 把 list 构造方法作为 default_factory 来创建一个 defaultdict。
# 而这个用来生成默认值的可调用对象存放在名为 default_factory 的实例属性里。
In [24]: index
Out[24]: defaultdict(list, {})
In [26]: index['aaa'] # 如果不存在 key 值,则 list 构造一个空列表,赋值给 这个 key,返回。
Out[26]: []
In [27]: index
Out[27]: defaultdict(list, {'aaa': []})
In [28]: index['bbb'].append(1)
In [29]: index
Out[29]: defaultdict(list, {'aaa': [], 'bbb': [1]})
# 如果在创建 defaultdict 的时候没有指定 default_factory,查询不存在的键会触发KeyError。
In [30]: index2 = collections.defaultdict()
In [31]: index2
Out[31]: defaultdict(None, {})
In [32]: index2['aaa']
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-32-c93e12e2c24f> in <module>
----> 1 index2['aaa']
KeyError: 'aaa'
defaultdict 里的 default_factory 只会在 __getitem__ 里被调用,在其他的方法里完全不会发挥作用。比如,dd 是个 defaultdict,k 是个找不到的键, dd[k] 这个表达式会调用 default_factory 创造某个默认值,而 dd.get(k)则会返回 None。
所有这一切背后的功臣其实是特殊方法 __missing__。它会在 defaultdict 遇到找不到的键的时候调用 default_factory,而实际上这个特性是所有映射类型都可以选择去支持的。
特殊方法 __missing__
所有的映射类型在处理找不到的键的时候,都会牵扯到 __missing__ 方法。这也是这个方法称作“missing”的原因。虽然基类 dict 并没有定义这个方法,但是 dict 是知道有这么个东西存在的。也就是说,如果有一个类继承了 dict,然后这个继承类提供了__missing__ 方法,那么在 __getitem__碰到找不到的键的时候,Python 就会自动调用它,而不是抛出一个 KeyError 异常。
__missing__ 方法只会被 __getitem__ 调用(比如在表达式 d[k] 中)。提供 __missing__ 方法对 get 或者 __contains__(in 运算符会用到这个方法)这些方法的使用没有影响。这也是我在上一节最后的警告中提到,defaultdict 中的default_factory 只对__getitem__ 有作用的原因。
如果要自定义一个映射类型,更合适的策略其实是继承collections.UserDict 类。这里我们从 dict 继承,只是为了演示 __missing__ 是如何被 dict.__getitem__ 调用的。
StrkeyDict 在查询的时候把非字符串的键转为字符串,[] , in , get 三个方法的支持。
In [34]: class StrkeyDict(dict):
...: def __missing__(self,key):
...: if isinstance(key,str):
...: raise KeyError(key)
...: return self[str(key)]
...: def get(self,key,default=None):
...: try:
...: return self[key]
...: except KeyError:
...: return default
...: def __contains__(self,key): # in 触发这个方法
...: return key in self.keys() or str(key) in self.keys()
...:
In [35]: d = StrkeyDict()
In [36]: d['a']
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-36-4ff0d9af6f7a> in <module>
----> 1 d['a']
<ipython-input-34-8695d55d5d68> in __missing__(self, key)
2 def __missing__(self,key):
3 if isinstance(key,str):
----> 4 raise KeyError(key)
5 return self[str(key)]
6 def get(self,key,default=None):
KeyError: 'a'
下面来看看为什么 isinstance(key, str) 测试在上面的 __missing__ 中是必需的。
如果没有这个测试,只要 str(k) 返回的是一个存在的键,那么 __missing__ 方法是没问题的,不管是字符串键还是非字符串键,它都能正常运行。但是如果 str(k) 不是一个存在的键,代码就会陷入无限递归。这是因为 __missing__ 的最后一行中的self[str(key)] 会调用 __getitem__,而这个 str(key) 又不存在,于是__missing__ 又会被调用。
为了保持一致性,__contains__ 方法在这里也是必需的。这是因为 k in d 这个操作会调用它,但是我们从 dict 继承到的 __contains__ 方法不会在找不到键的时候调用__missing__ 方法。__contains__ 里还有个细节,就是我们这里没有用更具 Python 风格的方式——k in my_dict——来检查键是否存在,因为那也会导致 __contains__被递归调用。为了避免这一情况,这里采取了更显式的方法,直接在这个 self.keys() 里查询。
像 k in my_dict.keys() 这种操作在 Python 3 中是很快的,而且即便映射类型对象很庞大也没关系。这是因为 dict.keys() 的返回值是一个“视图”。视图就像一个集合,而且跟字典类似的是,在视图里查找一个元素的速度很快。在“Dictionary view objects”(https://docs.python.org/3/library/stdtypes.html#dictionary-viewobjects)里可以找到关于这个细节的文档。Python 2 的 dict.keys() 返回的是个列表,因此虽然上面的方法仍然是正确的,它在处理体积大的对象的时候效率不会太高,因为 k in my_list 操作需要扫描整个列表。
出于对准确度的考虑,我们也需要这个按照键的原本的值来查找的操作(也就是 key in self.keys()),因为在创建 StrKeyDict0 和为它添加新值的时候,我们并没有强制要求传入的键必须是字符串。因为这个操作没有规定死键的类型,所以让查找操作变得更加友好。
字典的变种
collections.OrderedDict :有序字典
popitem 方法,默认删除并返回的是字典的最后一个元素,last 参数为 False 会返回第一个添加进去的元素。
collections.ChainMap :
该类型可以容纳数个不同的映射对象,然后在进行键查找操作的时候,这些对象会被当作一个整体被逐个查找,直到键被找到为止。这个功能在给有嵌套作用域的语言做解释器的时候很有用,可以用一个映射对象来代表一个作用域的上下文。在 collections 文档介绍 ChainMap 对象的那一部分(https://docs.python.org/3/library/collections.html#collections.ChainMap)里有一些具体的使用示例,其中包含了下面这个 Python 变量查询规则的代码片段:
import builtins
pylookup = ChainMap(locals(), globals(), vars(builtins))
ChainMap类用于快速链接多个映射,以便将它们视为一个单元。它通常比创建新字典和多次调用update()快得多。[{'a':1},{'b':2}]
该类可用于模拟嵌套作用域,在模板中很有用。
ChainMap将多个字典或其他映射组合在一起以创建单个可更新视图。如果未指定maps,则提供单个空字典,以便新链始终至少具有一个映射。
底层映射存储在列表中。该列表是公共的,可以使用maps属性访问或更新。没有其他声明。[{'a':1},{'b':2}]
查找会连续搜索映射,直到找到key。相反,写入,更新和删除仅在第一个映射上运行。
ChainMap通过引用合并了底层映射。因此,如果其中一个底层映射得到更新,那么这些更改将反映在ChainMap中。
注意d和e,都存储在ChainMap中,但是搜索的时候从左到右,先到先得。
def collection_test2():
import builtins
from collections import ChainMap
a = {"name": "leng"}
b = {"age": 24}
c = {"wife": "qian"}
pylookup = ChainMap(a,b,c)
print(pylookup) # ChainMap({'name': 'leng'}, {'age': 24}, {'wife': 'qian'})
print(pylookup['age'],pylookup.maps) # 24 [{'name': 'leng'}, {'age': 24}, {'wife': 'qian'}]
pylookup.update({"age": 25})
print(pylookup) # ChainMap({'name': 'leng', 'age': 25}, {'age': 24}, {'wife': 'qian'})
b['age'] = 26
print(pylookup) # ChainMap({'name': 'leng', 'age': 25}, {'age': 26}, {'wife': 'qian'})
print(type(pylookup.maps)) # <class 'list'>
pylookup.maps[0]['age']=20
pylookup.maps[1]['age']=22
print(pylookup) # ChainMap({'name': 'leng', 'age': 20}, {'age': 22}, {'wife': 'qian'})
print("-----------")
d = {"name": "leng"}
e = {"name":"123"}
cm = ChainMap(d,e)
print(cm) # ChainMap({'name': 'leng'}, {'name': '123'})
print(cm['name']) # leng
collection_test2()
支持所有常用的字典方法。此外,还有一个 maps属性,一个用于创建新子上下文的方法,以及一个用于访问除第一个映射之外的所有映射的属性:
maps
用户可更新的映射列表。该列表从首次搜索到最后搜索排序。它是唯一存储的状态,可以进行修改以更改搜索的映射。该列表应始终包含至少一个映射。
new_child(m=None)
返回包含新映射的ChainMap,后跟当前实例中的所有映射。如果指定m,则它将成为映射列表最前面的新映射; 如果未指定,则使用空的dict。所以d.new_child()等效于ChainMap({}, *d.maps)。此方法用于创建可在不更改任何父映射中的值的情况下更新的子上下文。
版本3.4中已更改:添加了可选参数m。
parents
返回新的ChainMap,包含当前实例中除第一个之外的所有映射。这对于在搜索中跳过第一个映射很有用。用例类似于嵌套作用域中使用的nonlocal关键字。用例也与内置函数super()的用法相同 。引用d.parents相当于ChainMap(*d.maps[1:]) 。
def collection_test3():
import builtins
from collections import ChainMap
a = {"name": "leng","age": 20}
b = {"age": 24}
c = {"wife": "qian"}
cm = ChainMap(a,b,c)
nc1 = cm.new_child()
nc2 = cm.new_child(m=b)
print(nc1,nc2,sep='\n')
# ChainMap({}, {'name': 'leng', 'age': 20}, {'age': 24}, {'wife': 'qian'})
# ChainMap({'age': 24}, {'name': 'leng', 'age': 20}, {'age': 24}, {'wife': 'qian'})
print("_________")
print(nc2.parents,nc1.parents,sep='\n')
# ChainMap({'name': 'leng', 'age': 20}, {'age': 24}, {'wife': 'qian'})
# ChainMap({'name': 'leng', 'age': 20}, {'age': 24}, {'wife': 'qian'})
collection_test3()
实际用途
本节介绍使用ChainMap的各种方法。
(1)模拟Python内部查找链的示例:
import builtins
pylookup = ChainMap(locals(), globals(), vars(builtins))
(2)让用户指定的命令行参数优先于环境变量的示例,而环境变量优先于默认值:
import os, argparse
defaults = {'color': 'red', 'user': 'guest'}
parser = argparse.ArgumentParser()
parser.add_argument('-u', '--user')
parser.add_argument('-c', '--color')
namespace = parser.parse_args()
command_line_args = {k:v for k, v in vars(namespace).items() if v}
combined = ChainMap(command_line_args, os.environ, defaults)
print(combined['color'])
print(combined['user'])
(3)使用ChainMap类来模拟嵌套上下文的示例模式:
c = ChainMap() # Create root context
d = c.new_child() # Create nested child context
e = c.new_child() # Child of c, independent from d
e.maps[0] # Current context dictionary -- like Python's locals()
e.maps[-1] # Root context -- like Python's globals()
e.parents # Enclosing context chain -- like Python's nonlocals
d['x'] # Get first key in the chain of contexts
d['x'] = 1 # Set value in current context
del d['x'] # Delete from current context
list(d) # All nested values
k in d # Check all nested values
len(d) # Number of nested values
d.items() # All nested items
dict(d) # Flatten into a regular dictionary
(4)如果需要对ChainMap进行深度写入和删除,则很容易创建一个子类来更新链中更深层次的键:
class DeepChainMap(ChainMap):
'Variant of ChainMap that allows direct updates to inner scopes'
def __setitem__(self, key, value):
for mapping in self.maps:
if key in mapping:
mapping[key] = value
return
self.maps[0][key] = value
def __delitem__(self, key):
for mapping in self.maps:
if key in mapping:
del mapping[key]
return
raise KeyError(key)
>>> d = DeepChainMap({'zebra': 'black'}, {'elephant': 'blue'}, {'lion': 'yellow'})
>>> d['lion'] = 'orange' # update an existing key two levels down
>>> d['snake'] = 'red' # new keys get added to the topmost dict
>>> del d['elephant'] # remove an existing key one level down
>>> d # display result
DeepChainMap({'zebra': 'black', 'snake': 'red'}, {}, {'lion': 'orange'})
(5)当不同的字典具有相同的主键的时候,在遍历串联之后的数据时,会只能遍历到之前的
user_dict1 = {"a": "xiaohong", "b": "xiaohua"}
user_dict2 = {"b": "xiaopang", "d": "xiaoming"}
new_dict = ChainMap(user_dict1, user_dict2)
for key, value in new_dict.items():
print(key, value)
# d xiaoming
# b xiaohua
# a xiaohong
collections.Counter
这个映射类型会给键准备一个整数计数器。统计一个可迭代对象中,每个元素出现的次数。
统计词频
colors = ['red', 'blue', 'red', 'green', 'blue', 'blue']
result = {}
for color in colors:
if result.get(color)==None:
result[color]=1
else:
result[color]+=1
print (result)
#{'red': 2, 'blue': 3, 'green': 1}
Counter实现:
from collections import Counter
colors = ['red', 'blue', 'red', 'green', 'blue', 'blue']
c = Counter(colors)
print (dict(c))
显然代码更加简单了,也更容易读和维护了。
Counter操作
可以创建一个空的Counter:
cnt = Counter()
之后在空的Counter上进行一些操作。
也可以创建的时候传进去一个迭代器(数组,字符串,字典等):
c = Counter('gallahad') # 传进字符串
c = Counter({'red': 4, 'blue': 2}) # 传进字典
c = Counter(cats=4, dogs=8) # 传进元组
判断是否包含某元素,可以转化为dict然后通过dict判断,Counter也带有函数可以判断:
In [43]: c1 = Counter(['e','f'])
In [44]: c1
Out[44]: Counter({'e': 1, 'f': 1})
In [45]: c1['d'] # 不存在,即 0
Out[45]: 0
In [46]: c2 = {'e': 1, 'f': 1}
In [47]: c2['d']
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-47-e7efe4245086> in <module>
----> 1 c2['d']
KeyError: 'd'
删除元素:
c['sausage'] = 0 # counter entry with a zero count
del c['sausage']
获得所有元素:
c = Counter(a=4, b=2, c=0, d=-2)
list(c.elements())
#['a', 'a', 'a', 'a', 'b', 'b']
查看最常见出现的k个元素:
Counter('abracadabra').most_common(3)
#[('a', 5), ('r', 2), ('b', 2)]
Counter更新:
c = Counter(a=3, b=1)
d = Counter(a=1, b=2)
c + d # 相加
#Counter({'a': 4, 'b': 3})
c - d # 相减,如果小于等于0,删去
#Counter({'a': 2})
c & d # 求最小
#Counter({'a': 1, 'b': 1})
c | d # 求最大
#Counter({'a': 3, 'b': 2})
统计词频:
from collections import Counter
lines = open("./data/input.txt","r").read().splitlines()
lines = [lines[i].split(" ") for i in range(len(lines))]
words = []
for line in lines:
words.extend(line)
result = Counter(words)
print (result.most_common(10))
当需要统计的文件比较大,使用read()一次读不完的情况:
from collections import Counter
result = Counter()
with open("./data/input.txt","r") as f:
while True:
lines = f.read(1024).splitlines()
if lines==[]:
break
lines = [lines[i].split(" ") for i in range(len(lines))]
words = []
for line in lines:
words.extend(line)
tmp = Counter(words)
result+=tmp
print (result.most_common(10))
colllections.UserDict
这个类其实就是把标准 dict 用纯 Python 又实现了一遍。跟 OrderedDict、ChainMap 和 Counter 这些开箱即用的类型不同,UserDict 是让用户继承写子类的。
子类化 UserDict
就创造自定义映射类型来说,以 UserDict 为基类,总比以普通的 dict 为基类要来得方便。而更倾向于从 UserDict 而不是从 dict 继承的主要原因是,后者有时会在某些方法的实现上走一些捷径,导致我们不得不在它的子类中重写这些方法,但是 UserDict 就不会带来这些问题。
data 属性:UserDict 最终存储数据的地方
UserDict 的子类就能在实现 __setitem__ 的时候避免不必要的递归,也可以让 __contains__ 里的代码更简洁。
import collections
class StrKeyDict(collections.UserDict):
def __missing__(self, key):
if isinstance(key, str):
raise KeyError(key)
return self[str(key)]
def __contains__(self, key):
return str(key) in self.data
def __setitem__(self, key, item):
self.data[str(key)] = item
因为 UserDict 继承的是 MutableMapping,所以 StrKeyDict 里剩下的那些映射类型的方法都是从 UserDict、MutableMapping 和 Mapping 这些超类继承而来的。特别是最后的 Mapping 类,它虽然是一个抽象基类(ABC),但它却提供了好几个实用的方法。以下两个方法值得关注。
MutableMapping.update
这个方法不但可以为我们所直接利用,它还用在 __init__ 里,让构造方法可以利用传入的各种参数(其他映射类型、元素是 (key, value) 对的可迭代对象和键值参数)来新建实例。因为这个方法在背后是用 self[key] = value 来添加新值的,所以它其实是在使用我们的 __setitem__ 方法。
Mapping.get
在 StrKeyDict中,我们不得不改写 get 方法,好让它的表现跟__getitem__ 一致。而在示例 3-8 中就没这个必要了,因为它继承了 Mapping.get 方法,而 Python 的源码(https://hg.python.org/cpython/file/3.4/Lib/_collections_abc.py#l422)显示,这个方法的实现方式跟 StrKeyDict0.get 是一模一样的。
TransformDict
通用性更强,把键存为字符串的同时,也按照原来的样子存一份。
不可变映射
有些信息不能轻易改变。
从 Python 3.3 开始,types 模块中引入了一个封装类名叫 MappingProxyType。如果给这个类一个映射,它会返回一个只读的映射视图。虽然是个只读视图,但是它是动态的。这意味着如果对原映射做出了改动,我们通过这个视图可以观察到,但是无法通过这个视图对原映射做出修改。
In [1]: from types import MappingProxyType
In [2]: d = {1:'a'}
In [3]: d_proxy = MappingProxyType(d)
In [4]: d_proxy[2] = 'b'
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-4-118de4fd8166> in <module>
----> 1 d_proxy[2] = 'b'
TypeError: 'mappingproxy' object does not support item assignment
from types import MappingProxyType
d = {1:'a'}
d_proxy = MappingProxyType(d)
print(d_proxy) # {1: 'a'}
d[2] = 'b'
print(d_proxy) # {1: 'a', 2: 'b'} , d_proxy 是动态的,d做了新修改,会反映到d_proxy
集合论
集合类型:
1 可以用于去重
2 集合中的元素必须是可散列的,set类型本身是不可散列的,forzenset可以。
3 a |b , a & b , a - b : 集合运算符,合理运用,减少代码。
示例 3-10 needles 的元素在 haystack 里出现的次数,两个变量都是 set 类型
found = len(needles & haystack)
示例 3-11 needles 的元素在 haystack 里出现的次数(作用和示例 3-10 中的相同)
found = 0
for n in needles:
if n in haystack:
found += 1
示例 3-10 比示例 3-11 的速度要快一些;另一方面,示例 3-11 可以用在任何可迭代对象needles 和 haystack 上,而示例 3-10 则要求两个对象都是集合。话再说回来,就算手头没有集合,我们也可以随时建立集合,如示例 3-12 所示。
示例 3-12 needles 的元素在 haystack 里出现的次数,这次的代码可以用在任何可迭代对象上
found = len(set(needles) & set(haystack))
# 另一种写法:
found = len(set(needles).intersection(haystack))
In [5]: a = {1,2,3}
In [6]: b = [2,3,3,]
In [7]: a.intersection(b) # b 是任何可迭代序列
Out[7]: {2, 3}
示例 3-12 里的这种写法会牵扯到把对象转化为集合的成本,不过如果 needles 或者是haystack 中任意一个对象已经是集合,那么示例 3-12 的方案可能就比示例 3-11 里的要更高效。
集合字面量
除空集之外,集合的字面量——{1}、{1, 2},等等——看起来跟它的数学形式一模一样。如果是空集,那么必须写成 set() 的形式。
In [8]: c = {}
In [9]: c
Out[9]: {}
In [16]: type(c)
Out[16]: dict
In [11]: c = set()
In [12]: type(c)
Out[12]: set
In [13]: c
Out[13]: set()
In [17]: d = {1,}
In [18]: d
Out[18]: {1}
In [19]: type(d)
Out[19]: set
In [20]: d.pop()
Out[20]: 1
In [21]: d
Out[21]: set()
像 {1, 2, 3} 这种字面量句法相比于构造方法(set([1, 2, 3]))要更快且更易读。后者的速度要慢一些,因为 Python 必须先从 set 这个名字来查询构造方法,然后新建一个列表,最后再把这个列表传入到构造方法里。但是如果是像 {1, 2, 3} 这样的字面量,Python 会利用一个专门的叫作 BUILD_SET 的字节码来创建集合。
利用 dis.dis (反汇编函数) ,看两个方式的字节码:
In [1]: from dis import dis
In [2]: dis('{1}') # 字面量句法
1 0 LOAD_CONST 0 (1)
2 BUILD_SET 1
4 RETURN_VALUE
In [3]: dis('set([1])') # 构造方法
1 0 LOAD_NAME 0 (set)
2 LOAD_CONST 0 (1)
4 BUILD_LIST 1
6 CALL_FUNCTION 1
8 RETURN_VALUE
frozenset ,没有字面量句法创建的方式,利用构造方法:
In [6]: b = frozenset(range(10))
In [7]: b
Out[7]: frozenset({0, 1, 2, 3, 4, 5, 6, 7, 8, 9})
集合推导
In [8]: from unicodedata import name # 导入,用以获取字符的名字
In [9]: name
Out[9]: <function unicodedata.name(chr, default=None, /)>
In [10]: {chr(i) for i in range(32,256) if 'SIGN' in name(chr(i),'')}
Out[10]:
{'#',
'$',
'%',
'+',
'<',
'=',
'>',
'¢',
'£',
'¤',
'¥',
'§',
'©',
'¬',
'®',
'°',
'±',
'µ',
'¶',
'×',
'÷'}
In [11]: name('=')
Out[11]: 'EQUALS SIGN'
集合方法:

运行效率:字典(0.000337s),集合(0.000387s ),列表(97.948056s )
在字典和集合中查找元素是否在其中是相当快的,列表慢。因为字典和集合内部结构 散列表。
字典中的散列表
散列表其实是一个稀疏数组(总是有空白元素的数组称为稀疏数组)。在一般的数据结构教材中,散列表里的单元通常叫作表元(bucket)。在 dict 的散列表当中,每个键值对都占用一个表元,每个表元都有两个部分,一个是对键的引用,另一个是对值的引用。因为所有表元的大小一致,所以可以通过偏移量来读取某个表元。因为 Python 会设法保证大概还有三分之一的表元是空的,所以在快要达到这个阈值的时候,原有的散列表会被复制到一个更大的空间里面
如果要把一个对象放入散列表,那么首先要计算这个元素键的散列值。Python 中可以用hash() 方法来做这件事情,接下来会介绍这一点。
\01. 散列值和相等性
内置的 hash() 方法可以用于所有的内置类型对象。如果是自定义对象调用 hash()的话,实际上运行的是自定义的 __hash__。如果两个对象在比较的时候是相等的,那它们的散列值必须相等,否则散列表就不能正常运行了。例如,如果 1 == 1.0 为真,那么 hash(1) == hash(1.0) 也必须为真,但其实这两个数字(整型和浮点)的内部结构是完全不一样的。
为了让散列值能够胜任散列表索引这一角色,它们必须在索引空间中尽量分散开来。这意味着在最理想的状况下,越是相似但不相等的对象,它们散列值的差别应该越大。
从 Python 3.3 开始,str、bytes 和 datetime 对象的散列值计算过程中多了随机的“加盐”这一步。所加盐值是 Python 进程内的一个常量,但是每次启动Python 解释器都会生成一个不同的盐值。随机盐值的加入是为了防止 DOS 攻击而采取的一种安全措施。在 hash 特殊方法的文档(https://docs.python.org/3/reference/datamodel.html#object.hash) 里有相关的详细信息。
\02. 散列表算法
为了获取 my_dict[search_key] 背后的值,Python 首先会调用 hash(search_key)来计算 search_key 的散列值,把这个值最低的几位数字当作偏移量,在散列表里查找表元(具体取几位,得看当前散列表的大小)。若找到的表元是空的,则抛出KeyError 异常。若不是空的,则表元里会有一对 found_key:found_value。
这时候 Python 会检验 search_key == found_key 是否为真,如果它们相等的话,就会返回 found_value。如果 search_key 和 found_key 不匹配的话,这种情况称为散列冲突。发生这种情况是因为,散列表所做的其实是把随机的元素映射到只有几位的数字上,而散列表本身的索引又只依赖于这个数字的一部分。为了解决散列冲突,算法会在散列值中另外再取几位,然后用特殊的方法处理一下,把新得到的数字再当作索引来寻找表元。若这次找到的表元是空的,则同样抛出 KeyError;若非空,或者键匹配,则返回这个值;或者又发现了散列冲突,则重复以上的步骤。
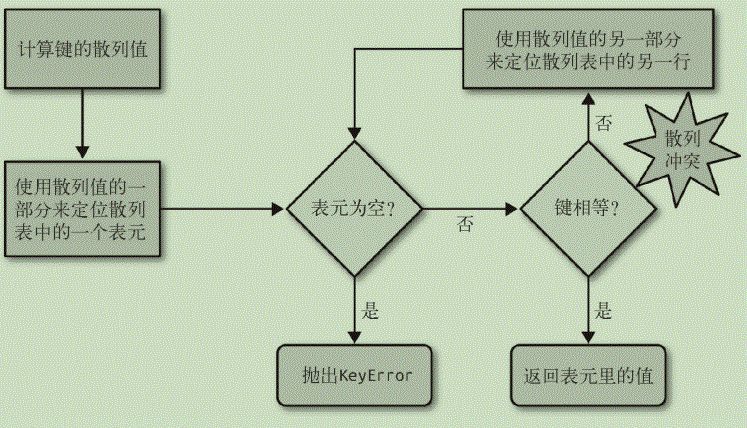
添加新元素和更新现有键值的操作几乎跟上面一样。只不过对于前者,在发现空表元的时候会放入一个新元素;对于后者,在找到相对应的表元后,原表里的值对象会被替换成新值。
另外在插入新值时,Python 可能会按照散列表的拥挤程度来决定是否要重新分配内存为它扩容。如果增加了散列表的大小,那散列值所占的位数和用作索引的位数都会随之增加,这样做的目的是为了减少发生散列冲突的概率。
表面上看,这个算法似乎很费事,而实际上就算 dict 里有数百万个元素,多数的搜索过程中并不会有冲突发生,平均下来每次搜索可能会有一到两次冲突。在正常情况下,就算是最不走运的键所遇到的冲突的次数用一只手也能数过来。
注:CPython 的实现细节里有一条是:如果有一个整型对象,而且它能被存进一个机器字中,那么它的散列值就是它本身的值。
dict 实现及导致的结果
\01.键必须是可散列的
一个可散列的对象必须满足以下要求。
(1) 支持 hash() 函数,并且通过 __hash__() 方法所得到的散列值是不变的。
(2) 支持通过 __eq__() 方法来检测相等性。
(3) 若 a == b 为真,则 hash(a) == hash(b) 也为真。
所有由用户自定义的对象默认都是可散列的,因为它们的散列值由 id() 来获取,而且它们都是不相等的。
如果你实现了一个类的 __eq__ 方法,并且希望它是可散列的,那么它一定要有个恰当的 __hash__ 方法,保证在 a == b 为真的情况下 hash(a) ==hash(b) 也必定为真。否则就会破坏恒定的散列表算法,导致由这些对象所组成的字典和集合完全失去可靠性,这个后果是非常可怕的。另一方面,如果一个含有自定义的 __eq__ 依赖的类处于可变的状态,那就不要在这个类中实现__hash__ 方法,因为它的实例是不可散列的。
\02. 字典在内存上的开销巨大
由于字典使用了散列表,而散列表又必须是稀疏的,这导致它在空间上的效率低下。举例而言,如果你需要存放数量巨大的记录,那么放在由元组或是具名元组构成的列表中会是比较好的选择;最好不要根据 JSON 的风格,用由字典组成的列表来存放这些记录。用元组取代字典就能节省空间的原因有两个:其一是避免了散列表所耗费的空间,其二是无需把记录中字段的名字在每个元素里都存一遍。
在用户自定义的类型中,__slots__属性可以改变实例属性的存储方式,由 dict 变 成 tuple,相关细节在 9.8 节会谈到。
记住我们现在讨论的是空间优化。如果你手头有几百万个对象,而你的机器有几个GB 的内存,那么空间的优化工作可以等到真正需要的时候再开始计划,因为优化往往是可维护性的对立面。
\03. 键查询很快
dict 的实现是典型的空间换时间:字典类型有着巨大的内存开销,但它们提供了无视数据量大小的快速访问——只要字典能被装在内存里。正如表 3-5 所示,如果把字典的大小从 1000 个元素增加到 10 000 000 个,查询时间也不过是原来的 2.8 倍,从0.000163 秒增加到了 0.00456 秒。这意味着在一个有 1000 万个元素的字典里,每秒能进行 200 万个键查询。
\04. 键的次序取决于添加顺序
当往 dict 里添加新键而又发生散列冲突的时候,新键可能会被安排存放到另一个位置。于是下面这种情况就会发生:由 dict([key1, value1), (key2, value2)]和 dict([key2, value2], [key1, value1]) 得到的两个字典,在进行比较的时候,它们是相等的;但是如果在 key1 和 key2 被添加到字典里的过程中有冲突发生的话,这两个键出现在字典里的顺序是不一样的。
\05. 往字典里添加新键可能会改变已有键的顺序
无论何时往字典里添加新的键,Python 解释器都可能做出为字典扩容的决定。扩容导致的结果就是要新建一个更大的散列表,并把字典里已有的元素添加到新表里。这个过程中可能会发生新的散列冲突,导致新散列表中键的次序变化。要注意的是,上面提到的这些变化是否会发生以及如何发生,都依赖于字典背后的具体实现,因此你不能很自信地说自己知道背后发生了什么。
如果你在迭代一个字典的所有键的过程中同时对字典进行修改,那么这个循环很有可能会跳过一些键——甚至是跳过那些字典中已经有的键。由此可知,不要对字典同时进行迭代和修改。如果想扫描并修改一个字典,最好分成两步来进行:首先对字典迭代,以得出需要添加的内容,把这些内容放在一个新字典里;迭代结束之后再对原有字典进行更新。
在 Python 3 中,.keys()、.items() 和 .values() 方法返回的都是字典视图。也就是说,这些方法返回的值更像集合,而不是像 Python 2 那样返回列表。视图还有动态的特性,它们可以实时反馈字典的变化
set 实现及导致的结果
set 和 frozenset 的实现也依赖散列表,但在它们的散列表里存放的只有元素的引用(就像在字典里只存放键而没有相应的值)。在 set 加入到 Python 之前,我们都是把字典加上无意义的值当作集合来用的。
特点总结如下。
1 集合里的元素必须是可散列的。
2 集合很消耗内存。
3 可以很高效地判断元素是否存在于某个集合。
4 元素的次序取决于被添加到集合里的次序。
5 往集合里添加元素,可能会改变集合里已有元素的次序。
Python的特点:简单而正确

 浙公网安备 33010602011771号
浙公网安备 33010602011771号