
爬虫——scrapy框架
今日内容
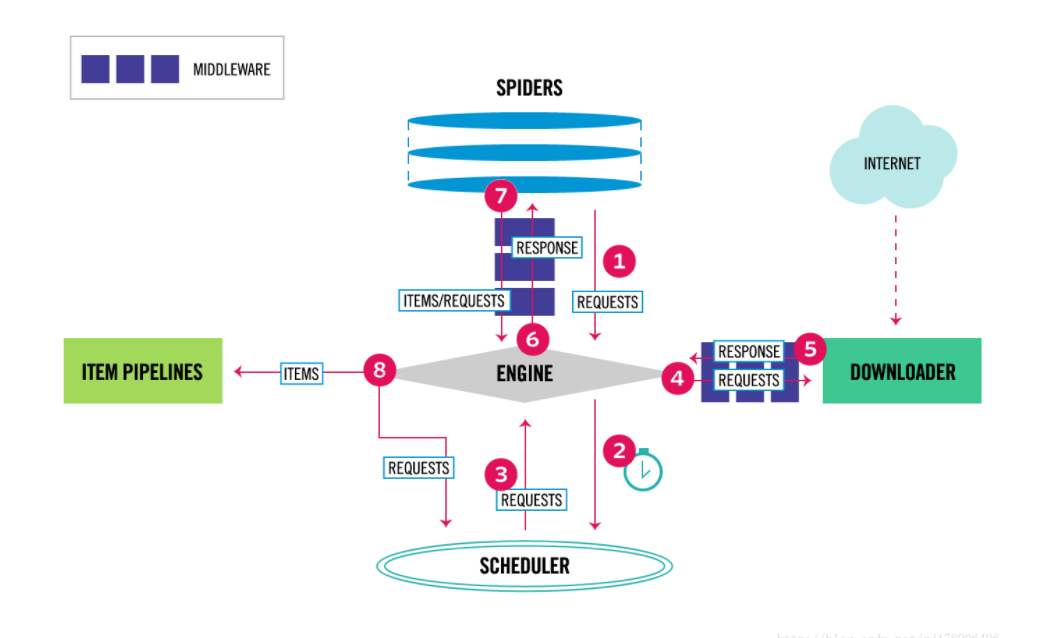
scrapy 架构
# 通用的网络爬虫框架,爬虫界的django
5大组件
-引擎(EGINE):大总管,负责控制数据的流向
-调度器(SCHEDULER):由它来决定下一个要抓取的网址是什么,去重
-下载器(DOWLOADER):用于下载网页内容, 并将网页内容返回给EGINE,下载器是建立在twisted这个高效的异步模型上的
-爬虫(SPIDERS):开发人员自定义的类,用来解析responses,并且提取items,或者发送新的请求request
-项目管道(ITEM PIPLINES):在items被提取后负责处理它们,主要包括清理、验证、持久化(比如存到数据库)等操作
2大中间件
-爬虫中间件:位于EGINE和SPIDERS之间,主要工作是处理SPIDERS的输入和输出(用的很少)
-下载中间件:引擎和下载器之间,加代理,加头,集成selenium
scrapy安装(windows,mac,linux)
pip3 install scrapy
windows 如果装不上
pip3 install wheel # 安装后,便支持通过wheel文件安装软件
wheel文件官网:https://www.lfd.uci.edu/~gohlke/pythonlibs
pip3 install lxml
pip3 install pyopenssl
下载并安装pywin32:
pip安装 https://sourceforge.net/projects/pywin32/files/pywin32/
下载twisted的wheel文件:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
执行pip3 install 下载目录\Twisted-17.9.0-cp36-cp36m-win_amd64.whl
pip3 install scrapy
scrapy 命令 :和 pip 放在一起 ,功能不同
如果还装不上,试一下 python2 的 pip 命令
scrapy 创建项目,创建爬虫,运行爬虫
创建项目
scrapy startproject 项目名
创建爬虫
scrapy genspider 爬虫名 爬虫地址
scrapy genspider chouti dig.chouti.com
在spider文件夹下创建出一个py文件
运行爬虫
scrapy crawl chouti # 带运行日志
scrapy crawl chouti --nolog # 不带日志
支持右键执行爬虫
在项目路径下新建一个main.py
from scrapy.cmdline import execute
execute(['scrapy','crawl','chouti','--nolog'])
目录介绍
firstscrapy # 项目名字
firstscrapy
-spiders # 爬虫脚本
-baidu.py
-chouti.py
-middlewares.py # 中间件
-pipelines.py # 持久化数据
-main.py # 自己加的,执行爬虫
-items.py # 一些类,规定一些字段
-settings.py # 配置文件
scrapy.cfg # 上线相关
settings介绍
1 默认情况,scrapy会去遵循爬虫协议
修改配置文件参数,强行爬取,不遵循协议
ROBOTSTXT_OBEY = False
2 USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
3 LOG_LEVEL='ERROR'
scrapy的数据解析(重点)
#xpath:
-response.xpath('//a[contains(@class,"link-title")]/text()').extract() # 取文本
-response.xpath('//a[contains(@class,"link-title")]/@href').extract() #取属性
#css
-response.css('.link-title::text').extract() # 取文本
-response.css('.link-title::attr(href)').extract_first() # 取属性
scrapy的持久化存储(重点)
方案一:parser函数必须返回 列表套字典的形式
scrapy crawl chouti -o chouti.csv
方案二:高级,pipline item存储(mysql,redis,文件)
在Items.py中写一个类
在spinder中导入,实例化,把数据放进去
item['title']=title
item['url']=url
item['photo_url']=photo_url
yield item
在setting中配置(数字越小,级别越高)
ITEM_PIPELINES = {
'firstscrapy.pipelines.ChoutiFilePipeline': 300,
}
在pipelines.py中写ChoutiFilePipeline
open_spider(开始的时候)
close_spider(结束的时候)
process_item(在这持久化)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号