
Transformer架构记录(四)
Transformer架构记录(一、二、三)针对Transformer的Encoder-block部分做了简要介绍,本文作为该系列的最终章,将以Decoder-block介绍结束本系列。
一个完整的Decoder-block的结构如下所示:

Decoder-block与Encoder-block的差别在以下几处:
- 第一个 Multi-Head Attention 层采用了 Masked 操作;
- 第二个 Multi-Head Attention 层的 K, V 矩阵使用 Encoder 的输出,进行计算,而 Q 使用上一个 Decoder block 的输出计算。
Masked Multi-Head Attention
-
在计算得到 Q、K、V 之后,计算 Q 和 K 转置的乘积 QK^T;
-
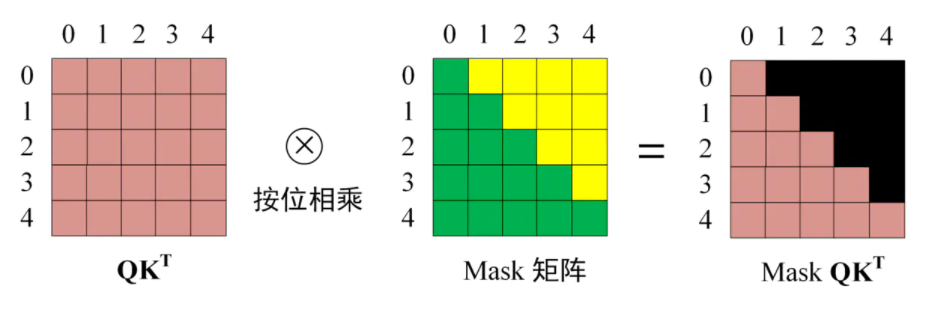
在对QK^T 进行 Softmax 之前需要使用 Mask 矩阵遮挡住每一个单词之后的信息,遮挡操作如下图所示:
-
在得到的 Mask QK^T 上进行 Softmax,使得每一行的和都为 1.
-
将经过 Softmax 操作的 Mask QK^T 与矩阵 V 相乘得到输出 Z;和 Encoder 类似,通过 Multi-Head Attention 拼接多个输出 Z_i 然后计算得到第一个 Multi-Head Attention 的输出 Z,Z 与输入的 X 维度一样
第二个 Multi-Head Attention
Decoder block 第二个 Multi-Head Attention 与 Encoder block 的 Multi-Head Attention 主要区别在于,其中 Self-Attention 的 K, V 矩阵不是使用 上一个 Decoder block 的输出计算的,而是使用 Encoder 的输出矩阵 C 计算的。
即,对于 Self-Attention 设置的(WQ、WK、WV),
Q = ZWQ (如果是第一个 Decoder block 则使用输入矩阵 X 替代 Z 进行计算,其余Decoder block则使用前一个Decoder block 的输出 Z 进行计算)
K = CWK
V = C*WV
通过堆叠多个 Decoder block ,得到解码器 Decoder.
预测输出
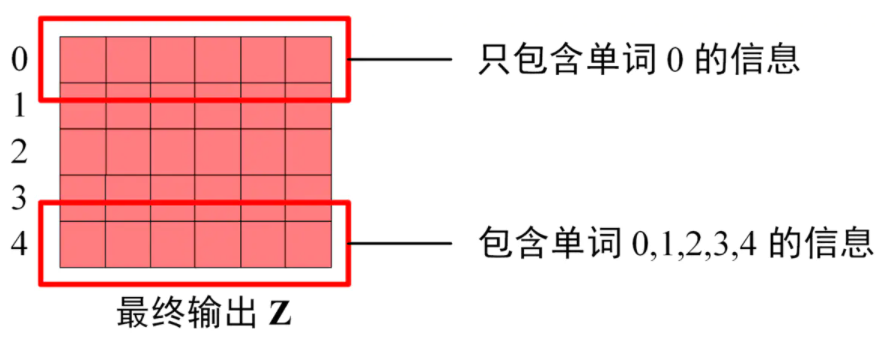
在 Decoder 的最后输出 Z 中,其包含的信息分布如下图所示:
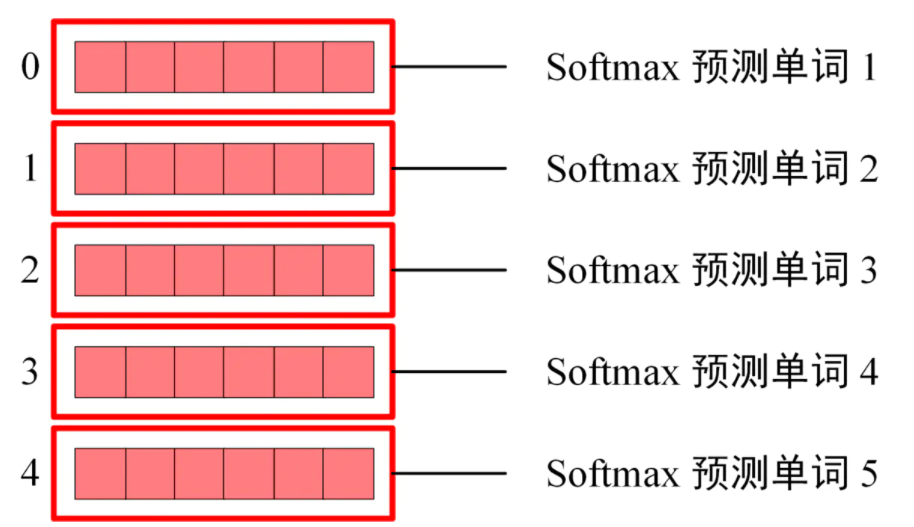
Softmax 作用于 Z 每一行,用于预测下一个单词,如下图所示:
参考资源
链接:https://www.jianshu.com/p/9b87b945151e
《Attention is all you need》
作者: pythonfl
出处: http://www.cnblogs.com/pythonfl/
本文版权归作者和博客园共有,转载时请标明出处;如有疑问,欢迎联系fangleiecust@163.com;如发现文中内容侵犯到您的权利,请联系作者予以处理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号