
浅析word2vec(一)
1 word2vec
在自然语言处理的大部分任务中,需要将大量文本数据传入计算机中,用以信息发掘以便后续工作。但是目前计算机所能处理的只能是数值,无法直接分析文本,因此,将原有的文本数据转换为数值数据成为了自然语言处理任务的关键一环。
Word2vec,为一群用来产生词向量的相关模型。这些模型为浅层双层的神经网络,用来训练以重新建构语言学之词文本。 ————维基百科
简单来说,word2vec的系列模型可以将文字(此处特指中文字符)转换成向量,比如“我爱中国”这句话,经过模型处理后,可能会变为以下4个向量:
(0.12,0.45,-0.3,0.44),(0.2,0.6,0.7,0.9),(-0.76,0.53,0.88,-0.31),(0.47,0.92,0.66,0.89),
这种向量称为词向量(对中文而言也可以称作字向量),后续对"我爱中国"的处理便可以转为对以上4个词向量的处理。
那么这种转换是如何完成的,这就要谈及word2vec中的两个经典模型:skip-grams和CBOW,CBOW下次再讲,本文主要介绍skip-grams.
关于skip-grams的详细说明,诸位可以参考网页:https://becominghuman.ai/how-does-word2vecs-skip-gram-work-f92e0525def4
2 模型特点
skip-grams的工作方法与其它模型略有差别,词向量的获取并不是通过输入一个字到skip-grams中再从模型中输出一个向量。相反,只要将skip-grams模型训练完成后,所有参与训练的字就已经获得了自己的词向量;换句话说,所有的词向量已经作为模型的可训参数储存在模型自身,想要得到某个字的词向量,只需依照某种规则从模型参数中提取即可,所以模型的训练阶段至关重要。
3 训练过程
3.1 获取训练样本
模型的训练思路大体如下:初始先给每个字随机分配一个词向量,然后选定一字作为中心字,取一个固定的长度,在原始语料中获得训练样本,如下图所示:
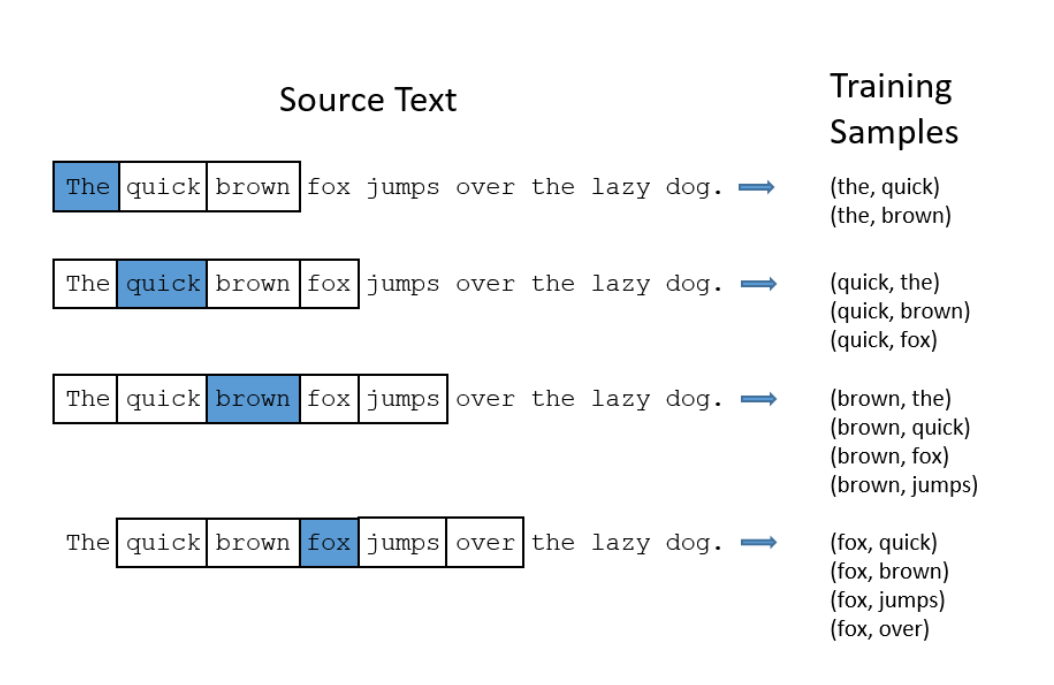
3.2 统计频率
统计上下文字出现在中心字周围的频率,作为该字与中心字共存的概率。
3.3 模型参数调整
在给定的词向量的基础上,依次计算每个字与中心字共存的概率大小。多数情况下,这与上一步实际统计出来的有所差异,所以要调整模型参数,使得概率分布更符合实际情况,对参数的调整就是对词向量的调整。如此进行若干次后,以至于每个字都有机会作为中心字参与训练。参数训练完成后,则每个字对应的词向量已经得到。
4 备注
模型训练完成后,每个字通常会有两个词向量与之对应,一个是该字作为中心字时的词向量,一个是该字作为其它字的上下文字时的词向量,一般选取前者代表该字最终的词向量。
作者: pythonfl
出处: http://www.cnblogs.com/pythonfl/
本文版权归作者和博客园共有,转载时请标明出处;如有疑问,欢迎联系fangleiecust@163.com;如发现文中内容侵犯到您的权利,请联系作者予以处理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号