
初识集成学习
假设随机问很多人同一个问题,然后将许多份回答整合起来,通常情况下会发现这个合并的答案比一个专家的答案还要好。这就如同俗语所说“三个臭皮匠,顶个诸葛亮”,也好比对某个问题进行民主投票一样。机器学习中集成学习的思想与之类似。
在分类问题中,传统机器学习方法是在一个由各种可能的函数构成的假设空间中寻找一个最接近实际分类函数的分类器 ,单个的分类器模型到如今已经发展了不少,有的甚至成为了经典分类算法,如决策树、支持向量机以及朴素贝叶斯等。
集成学习的思路是:在对新样本进行分类时,把若干个单个分类器集成起来,通过对这些单个分类器的预测结果进行某种组合来决定最终的分类,从而取得比任意一个单个分类器更好的性能。如果把单个分类器比作一个决策者的话,集成学习的方法相当于多个决策者共同进行决策。
经典的分类器———随机森林,就是在决策树的基础上通过集成学习衍生而来,并且是集成方法bagging的代表模型。著名的集成方法包括 bagging, boosting, stacking 和其他一些算法。需要注意的是:并不是任意的集成都是有效的,还要考虑到中和效应,即一些分类性能差的分类器会拉低整体的分类能力。
示例如下:
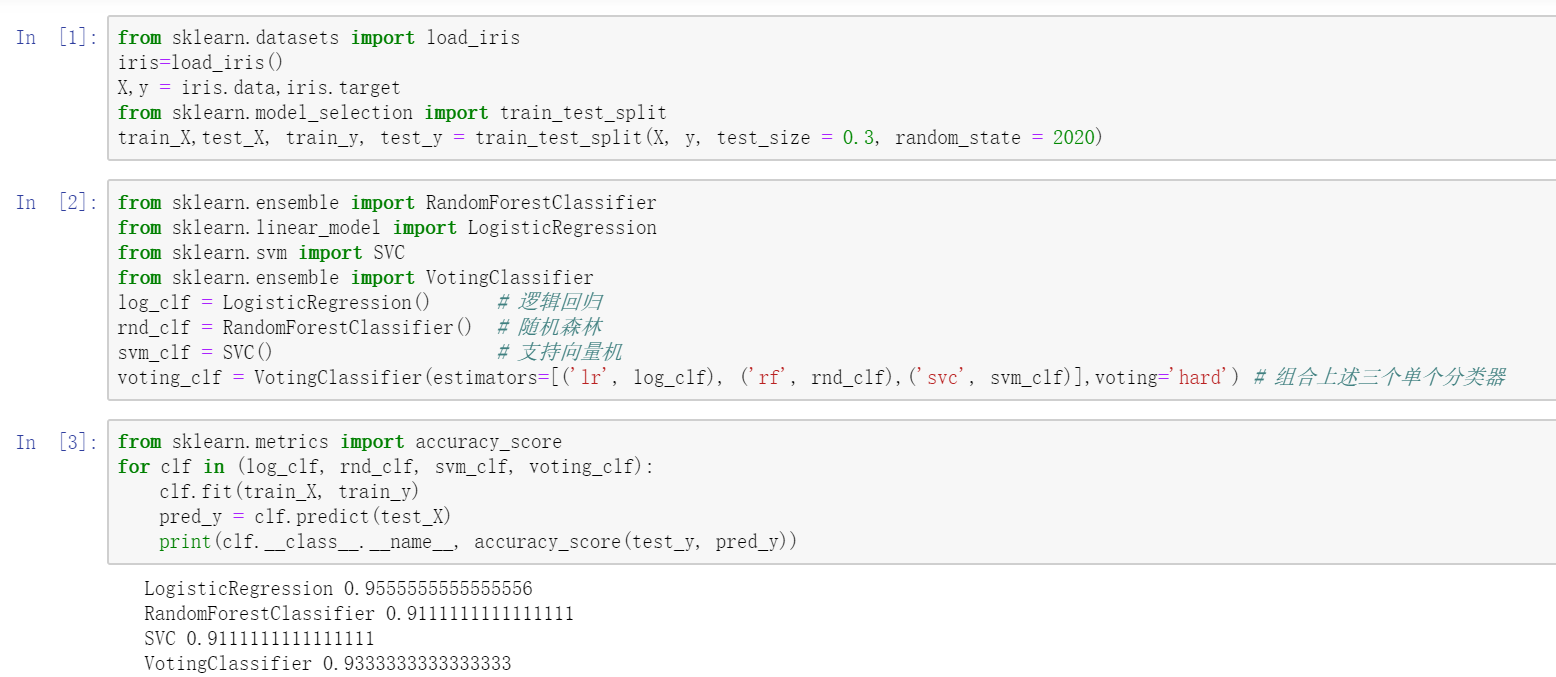
例中将随机森林、支持向量机以及逻辑回归模型视为三个单个分类器,并将三者集成为一个 voting_clf 集成分类器,结果表明集成分类器的分类表现优于构成它的两个单个分类器,但劣于逻辑回归,所以选择恰当的集成手段也是保证集成方法奏效的关键。
本文只是初步感受集成学习的流程,虽然代码简单,但也是运用集成方法的案例(尽管失败了)。后面将详细介绍前文提到的三种主流集成算法bagging, boosting, stacking。
作者: pythonfl
出处: http://www.cnblogs.com/pythonfl/
本文版权归作者和博客园共有,转载时请标明出处;如有疑问,欢迎联系fangleiecust@163.com;如发现文中内容侵犯到您的权利,请联系作者予以处理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号