
关于机器学习二分类问题的几个评估指标辨析
在完成机器学习中的二分类问题的建模阶段后,需要对模型的效果做评价,如今业内通常采用的评价指标有精确率(Precision)、准确率(Accuracy)、召回率(Recall)、F值(F-Measure)等多个方面,为了准确理解以避免混淆,本文将对这些指标做简要介绍。
1 混淆矩阵
其实,上面提及的诸多评测指标都是在混淆矩阵上衍生出来的,因此先简要介绍混淆矩阵。
针对二分类问题,通常将我们所关心的类别定为正类,另一类称为负类;例如使用某种分类器预测某种疾病,我们关心的是“患病”这种情况,以便及早接受治疗,所以将“患病”设为正类,“不患病”设为负类。
混淆矩阵由如下数据构成:
True Positive (真正,TP):将正类预测为正类的数目
True Negative (真负,TN):将负类预测为负类的数目
False Positive(假正,FP):将负类预测为正类的数目(误报)
False Negative(假负,FN):将正类预测为负类的数目(漏报)
接下来介绍的几种评价指标都是由上述四个数据相互运算产生。
2 准确率(accuracy)
计算公式为:acc = (TP+TN)/(TP+TN+FP+FN)
准确率是最常见的评价指标,很容易理解,就是预测正确的样本数占所有的样本数的比例;通常来说,准确率越高分类器越好。然而,在正负样本极不平衡的情况下,准确率这个评价指标有很大的缺陷。
3 错误率(error rate)
计算公式为:err = 1-acc
错误率则与准确率相反,衡量分类器错误分类的比例情况。
4 灵敏度(sensitive)
计算公式为: sensitive = TP/(TP+FN)
灵敏度表示的是样本中所有正例中被识别的比例,衡量了分类器对正例的识别能力。
5 特效度(specificity)
计算公式为:specificity = TN/(TN+FP)
特效度表示的是样本中所有负例中被识别的比例,衡量了分类器对负例的识别能力。
6 精确率(precision)
计算公式为:P = TP/(TP+FP)
精确率与准确率要有所区别,精确率表示的是被分类器分为正例的样本中,确实为正例的样本占的比例。
7 召回率(recall)
计算公式为:R = TP/(TP+FN) = sensitive
从公式上可以看出,召回率与灵敏度是相同的,衡量的是分类器对正例的识别能力。这个指标结合疾病识别的例子就很好理解了,若将“患病”定为正类,则召回率描述的是所有真正的患者中,被分类器识别出来从而召唤到医院的患者占的比例。
8 综合评价指标(F-Measure)
P和R指标有时候会出现的矛盾的情况,这样就需要综合考虑,常见的方法就是F-Measure(又称F-Score)。
F-Measure是Precision和Recall加权调和平均:
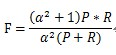
当参数α=1时,就是常见的F1值:
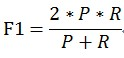
F1综合了P和R的结果,当F1较高时则说明分类器确实比较有效。
小结:本文介绍的几种指标都是最为常用的衡量标准,针对分类问题还有其它评测指标,如计算速度、鲁棒性、可扩展性、可解释性、ROC曲线和PR曲线等;至于多分类问题,可以仿照二分类的情况类比得到与上述指标相似的指标计算公式。
作者: pythonfl
出处: http://www.cnblogs.com/pythonfl/
本文版权归作者和博客园共有,转载时请标明出处;如有疑问,欢迎联系fangleiecust@163.com;如发现文中内容侵犯到您的权利,请联系作者予以处理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号