浅谈python的第三方库——pandas(二)
pandas使用小贴士
1 通过Series创建DataFrame
在pandas系列的第一篇博文中曾提到,Series可视为DataFrame的一种特例,即只有一列数据。既然如此,是否可以并列多个Series组成一个DataFrame呢?当然可以,通过这种方式创建DataFrame也称为用字典建立数据,由各列列名充当字典的键,该列数据构成的Series充当该键对应的值。示例如下:
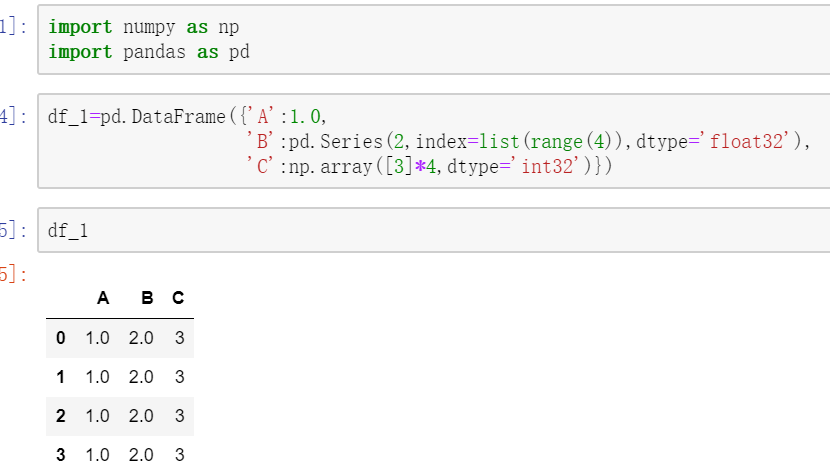
上图中,Series类型充任df_1的第二列,因为pandas默认以“0,1,2,3”形式给行列命名,本例中,列名就是字典的键,行名默认自动生成,为了与已有行名对应,在创建第二列的Series时指定了行名index=list(range(4))。
另外,numpy中的一维数组也可以起到充当DataFrame某一列数据的作用,如果给某一列赋值时只有一个值,则pandas会自动根据行的数目重复该值以补全该列。
2 查看DataFrame的常用属性
注意:下面的例子是在一个新建的df_2上演示,同样通过上一小节介绍的字典方式创建,但数据量略微大一些。
2.1 查看各列数据类型
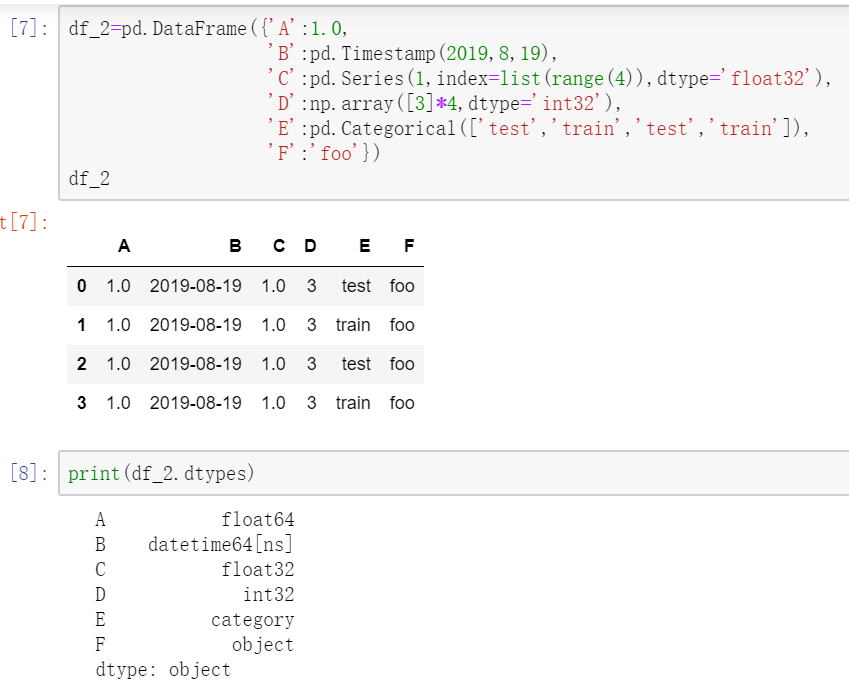
2.2 查看行列名和具体数据

使用values方法可以直接得到和numpy中一样的多维数组形式的数据类型。
2.3 查看数据描述
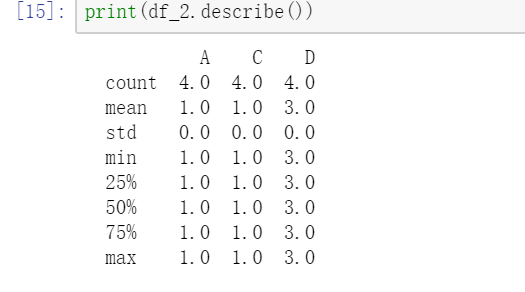
数据描述只是针对数值型数据给出某些列的统计信息。
对于pandas的一些转置、排序操作,这些方法和numpy中的方法无异,在此不再赘述。
3 设定条件选取数据
前一篇博文提到用行列名、行列位置以及二者混合的方式选取数据,其实还有一种通过给定条件选择数据的方法。
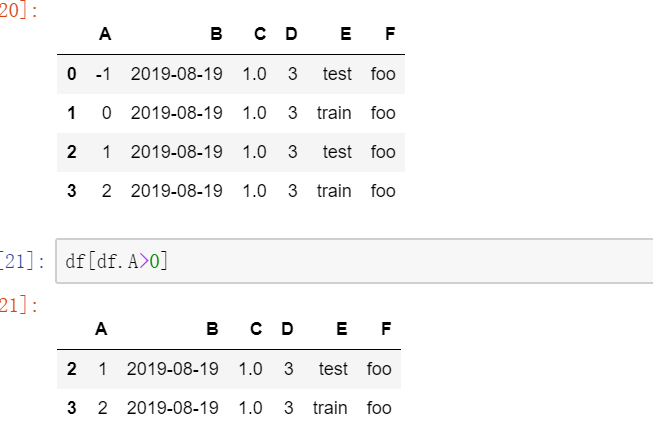
上图中,设置条件选择A列中大于零的值,然后将其所在的行抽取出来组成新的DataFrame。
当然,也可以在设定条件的同时,指定所要选取的列。

本期到此结束,后面将继续介绍pandas的常用操作。
作者: pythonfl
出处: http://www.cnblogs.com/pythonfl/
本文版权归作者和博客园共有,转载时请标明出处;如有疑问,欢迎联系fangleiecust@163.com;如发现文中内容侵犯到您的权利,请联系作者予以处理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号