


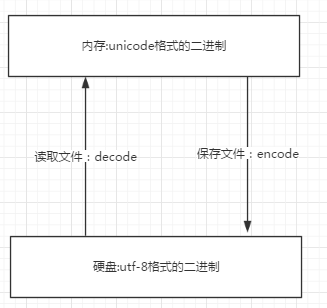
- 内存中使用的编码是unicode,用空间换时间(程序都需要加载到内存才能运行,因而内存应该是尽可能的保证快)
- 硬盘中或者网络传输用utf-8,网络I/O延迟或磁盘I/O延迟要远大与utf-8的转换延迟,而且I/O应该是尽可能地节省带宽,保证数据传输的稳定性
unicode----->encode-------->utf-8
utf-8-------->decode---------->unicode
![]()
-
无论是何种编辑器,要防止文件出现乱码(请一定注意,存放一段代码的文件也仅仅只是一个普通文件而已,此处指的是文件没有执行前,我们打开文件时出现的乱码)
核心法则就是,文件以什么编码保存的,就以什么编码方式打开
-
阶段一:启动python解释器
阶段二:python解释器此时就是一个文本编辑器,负责打开文件test.py,即从硬盘中读取test.py的内容到内存中#coding:utf-8,来决定以什么编码格式来读入内存,这一行就是来设定python解释器这个软件的编码使用的编码格式这个编码
- 阶段三:读取已经加载到内存的代码(unicode编码的二进制),然后执行,执行过程中可能会开辟新的内存空间,比如x="egon"
-
在python3 中也有两种字符串类型str和bytes
1 #coding:utf-8 2 s='林' #当程序执行时,无需加u,'林'也会被以unicode形式保存新的内存空间中, 3 4 #s可以直接encode成任意编码格式 5 s1=s.encode('utf-8') 6 s2=s.encode('gbk') 7 8 9 10 print(s) #林 11 print(s1) #b'\xe6\x9e\x97' 在python3中,是什么就打印什么 12 print(s2) #b'\xc1\xd6' 同上 13 14 print(type(s)) #<class 'str'> 15 print(type(s1)) #<class 'bytes'> 16 print(type(s2)) #<class 'bytes'>
python3字符串是unicode编码,字节是utf-8编码后的字节 python2字符串就是python3里编码后的字节,加u表示unicode

 浙公网安备 33010602011771号
浙公网安备 33010602011771号