数据采集第四次实验
作业1
仓库链接:https://gitee.com/jyppx000/crawl_project
作业①
要求:
- 熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
- 使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
1.1 代码和图片
代码:
"""
实现思路:
1.连接数据库
2.使用 selenium 打开 Chrome 浏览器,根据用户输入的选择(1、2、3),分别加载不同的网页链接
3.数据爬取 遍历用户输入的页数 n 查找页面中的股票数据行 从每行中提取股票的详细信息,如代码、名称、最新报价
4.存储数据:将提取的股票信息通过 INSERT 语句存入对应的数据库表中
5.页面导航:模拟点击“下一页”按钮,继续爬取下一页数据
"""
import time
import pymysql
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
conn = pymysql.connect(host="127.0.0.1", port=3306, user='root', passwd='123456', charset='utf8', db='east_money')
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
driver = webdriver.Chrome()
print("请输入需要查找的股票,1:沪深京,2:上证,3:深证")
while True:
num = input("请输入:")
if num == '1':
# 沪深京A股
driver.get("https://quote.eastmoney.com/center/gridlist.html#hs_a_board")
table_name = "stocks_hs_a"
break
elif num == '2':
# 上证A股
driver.get("https://quote.eastmoney.com/center/gridlist.html#sh_a_board")
table_name = "stocks_sh_a"
break
elif num == '3':
# 深证A股
driver.get("https://quote.eastmoney.com/center/gridlist.html#sz_a_board")
table_name = "stocks_sz_a"
break
cursor.execute(f'''CREATE TABLE IF NOT EXISTS {table_name}
(id INTEGER PRIMARY KEY,
code TEXT,
name TEXT,
latest_price TEXT,
change_percent TEXT,
change_amount TEXT,
volume TEXT,
turnover TEXT,
amplitude TEXT,
highest TEXT,
lowest TEXT,
open_price TEXT,
close_price TEXT)''')
cursor.execute(f"DELETE FROM {table_name}")
n = input("请输入需要查找的页码:")
n = int(n)
# 爬取前n页股票信息
for page in range(1, n + 1): # 爬取n页
print(f"正在爬取第 {page} 页股票信息")
# 定位所有股票信息的元素
stocks_list = driver.find_elements(By.XPATH, "//div[@class='listview full']//tbody//tr")
# 打印股票信息
for stock in stocks_list:
stock_id = stock.find_element(By.XPATH, './/td[1]').text
stock_code = stock.find_element(By.XPATH, './/td[2]/a').text
stock_name = stock.find_element(By.XPATH, './/td[3]/a').text
stock_latest_price = stock.find_element(By.XPATH, './/td[5]//span').text
stock_change_percent = stock.find_element(By.XPATH, './/td[6]//span').text
stock_change_amount = stock.find_element(By.XPATH, './/td[7]//span').text
stock_volume = stock.find_element(By.XPATH, './/td[8]').text
stock_turnover = stock.find_element(By.XPATH, './/td[9]').text
stock_amplitude = stock.find_element(By.XPATH, './/td[10]').text
stock_highest = stock.find_element(By.XPATH, './/td[11]//span').text
stock_lowest = stock.find_element(By.XPATH, './/td[12]//span').text
stock_open_price = stock.find_element(By.XPATH, './/td[13]//span').text
stock_close_price = stock.find_element(By.XPATH, './/td[14]').text
sql = f"INSERT INTO {table_name} (id, code, name, latest_price, change_percent, change_amount, volume, turnover, amplitude, highest, lowest, open_price, close_price) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)"
cursor.execute(sql,
[stock_id, stock_code, stock_name, stock_latest_price, stock_change_percent, stock_change_amount,
stock_volume, stock_turnover, stock_amplitude, stock_highest, stock_lowest, stock_open_price,
stock_close_price])
conn.commit()
print("数据已存入数据库")
# 点击下一页按钮
next_page_button = driver.find_element(By.XPATH, '//*[@id="main-table_paginate"]/a[2]')
action = ActionChains(driver)
time.sleep(5)
action.move_to_element(next_page_button).perform()
next_page_button.click()
time.sleep(5)
conn.close()
# 关闭浏览器
driver.quit()
图片:
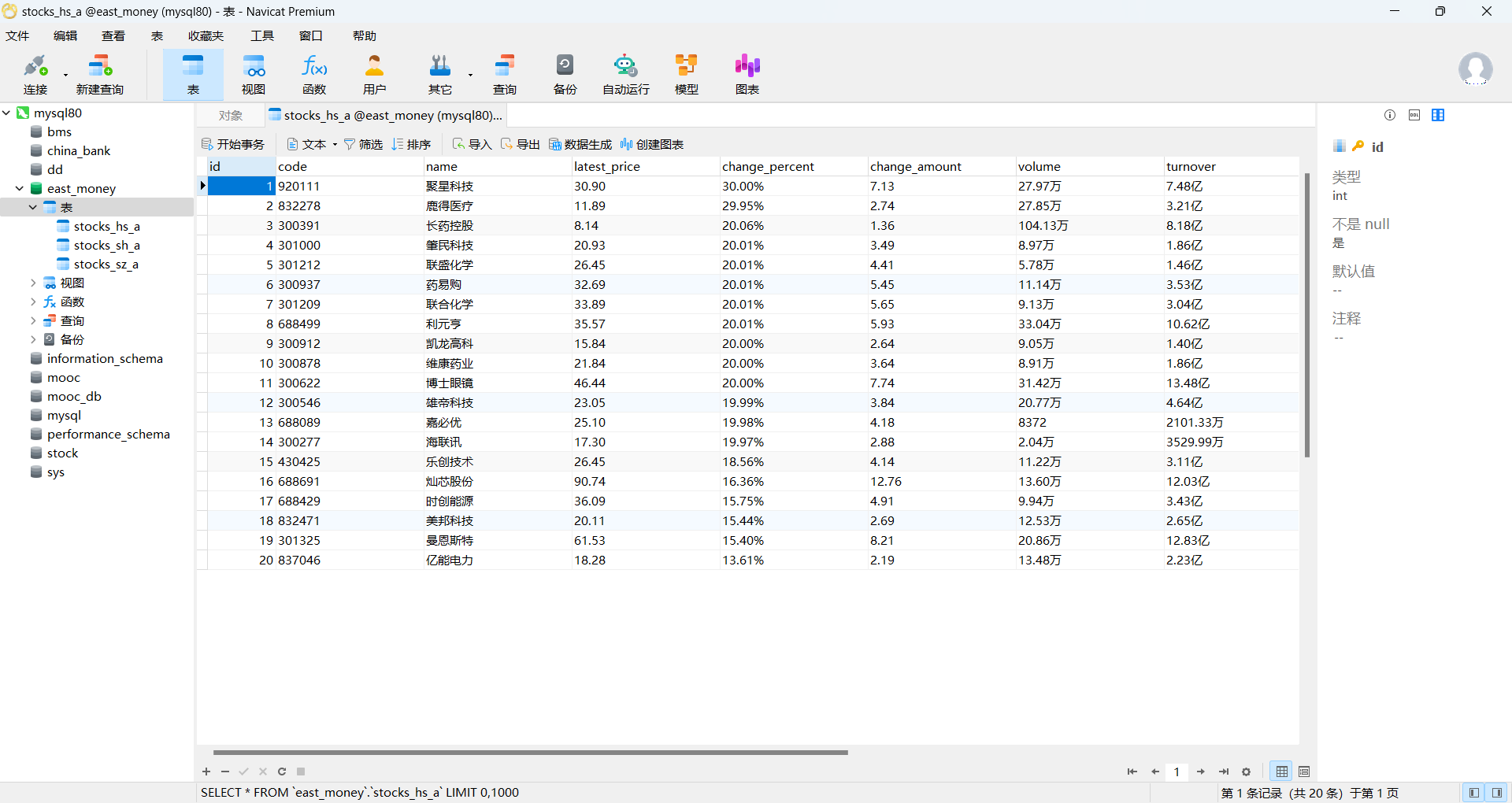
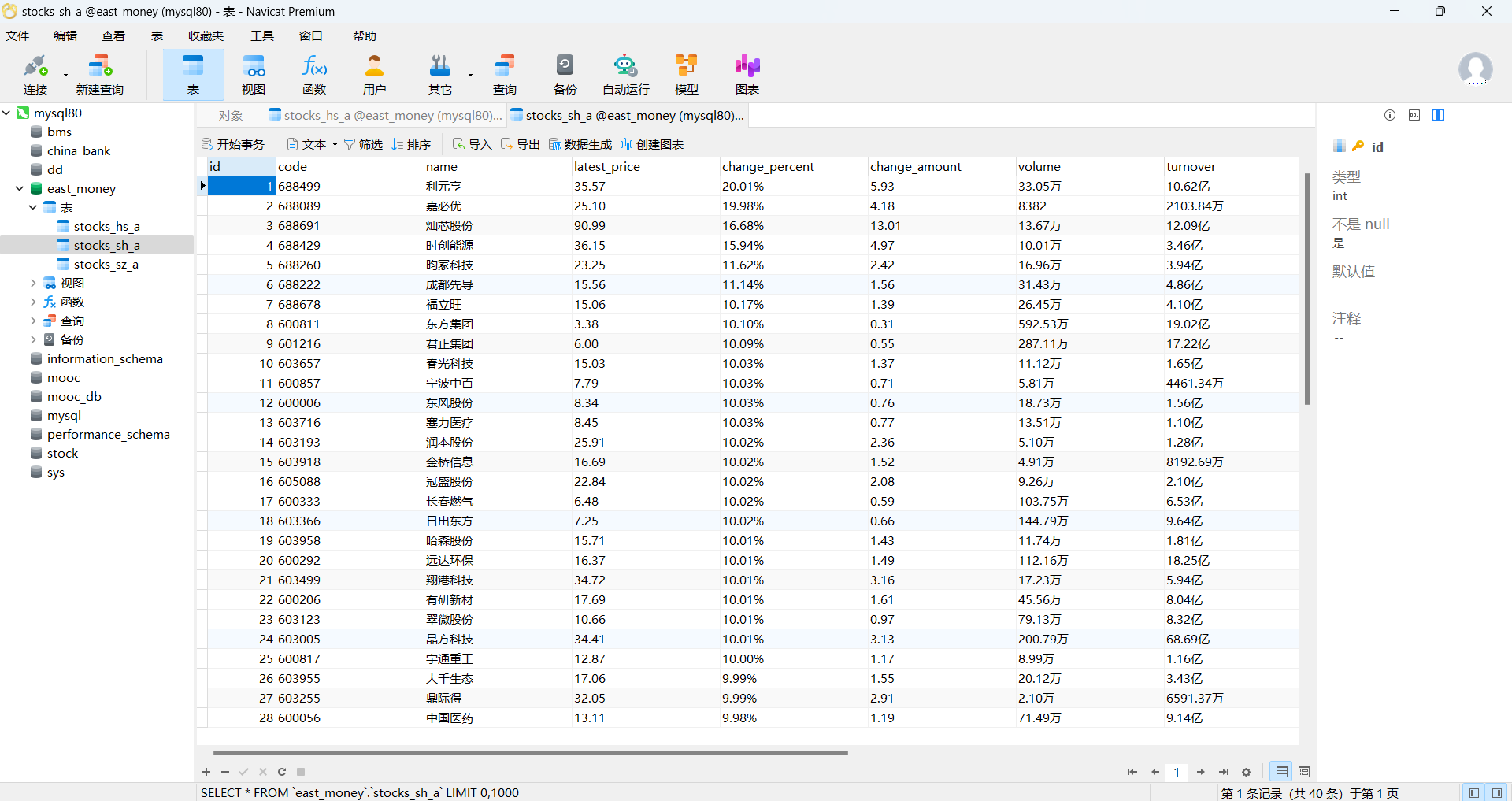
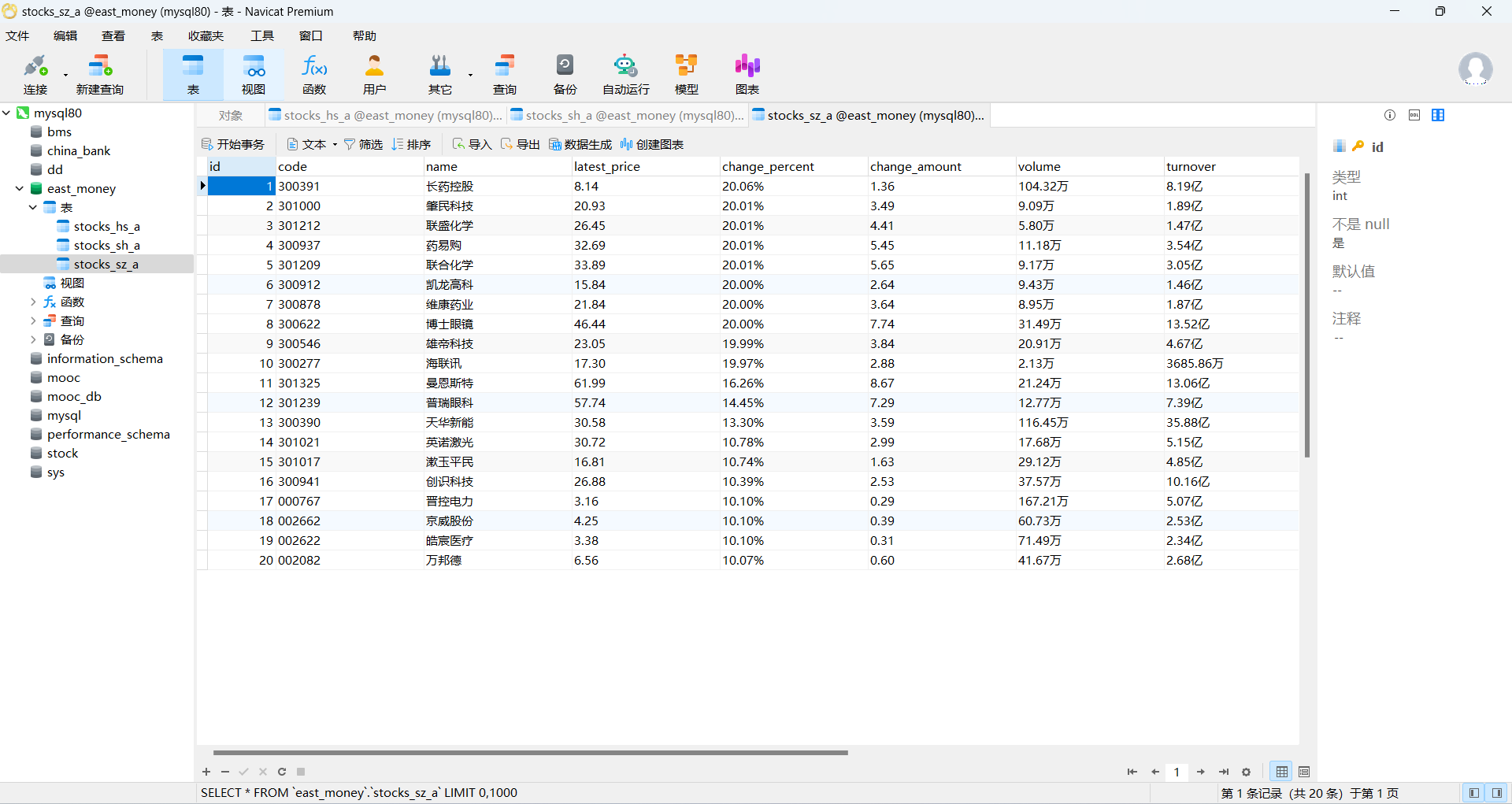
1.2 作业心得
- 加深了用 Selenium 控制浏览器自动抓取网页数据的技术栈
- 深入了解了如何模拟点击“下一页”按钮抓取多页数据。
作业②
要求:
- 熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
- 使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
2.1 代码和图片
代码:
"""
实现思路:
1.启动浏览器并访问网站
2.登录相关
点击页面上的登录按钮
切换到登录框的 iframe 内部
输入手机号和密码进行登录
3.访问课程搜索页面
4.创建数据库并建立表格
5.获取课程信息并存储到数据库
"""
from selenium import webdriver
from selenium.webdriver.common.by import By
import sqlite3
import time
driver = webdriver.Chrome()
driver.get('https://www.icourse163.org/')
time.sleep(1)
button = driver.find_element(By.XPATH, '//*[@id="app"]/div/div/div[1]/div[3]/div[3]/div')
button.click()
time.sleep(1)
frame = driver.find_element(By.XPATH,"//div[@class='ux-login-set-container']//iframe")
driver.switch_to.frame(frame)
# 我这里的手机号和密码肯定不会放真实的,大家根据自己的实际来填写【学计算机多少会注重个人隐私】
account = driver.find_element(By.ID, 'phoneipt').send_keys('15306918501')
password = driver.find_element(By.XPATH, '//input[@placeholder="请输入密码"]').send_keys("123456")
button1 = driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[6]/a')
button1.click()
time.sleep(1)
url = 'https://www.icourse163.org/search.htm?search=%E5%A4%A7%E6%95%B0%E6%8D%AE#/'
driver.get(url)
conn = sqlite3.connect('课程信息.db')
cursor = conn.cursor()
cursor.execute('''
create table course(
id INTEGER,课程名称 text, 学校名称 text,老师 text,教师团队 text,参加人数 text, 课程进度 text, 课程简介 text
)
''')
count = 0
link_list = driver.find_elements(By.XPATH, '//div[@class="u-clist f-bgw f-cb f-pr j-href ga-click"]')
for link in link_list:
count += 1
course_name = link.find_element(By.XPATH, './/span[@class=" u-course-name f-thide"]').text
school_name = link.find_element(By.XPATH, './/a[@class="t21 f-fc9"]').text
teacher = link.find_element(By.XPATH, './/a[@class="f-fc9"]').text
try:
team_member = link.find_element(By.XPATH, './/span[@class="f-fc9"]/span').text
team_member = team_member + ' 、' + teacher
except Exception as err:
team_member = 'none'
attendees = link.find_element(By.XPATH, './/span[@class="hot"]').text
attendees.replace('参加', '')
process = link.find_element(By.XPATH, './/span[@class="txt"]').text
introduction = link.find_element(By.XPATH, './/span[@class="p5 brief f-ib f-f0 f-cb"]').text
cursor.execute('''
insert into course(
id ,课程名称 , 学校名称 ,老师 ,教师团队 ,参加人数 , 课程进度 , 课程简介
)
VALUES(?,?,?, ?, ?, ?, ?, ?)
''', (count, course_name, school_name, teacher, team_member, attendees, process, introduction
))
conn.commit()
cursor.close()
conn.close()
图片:
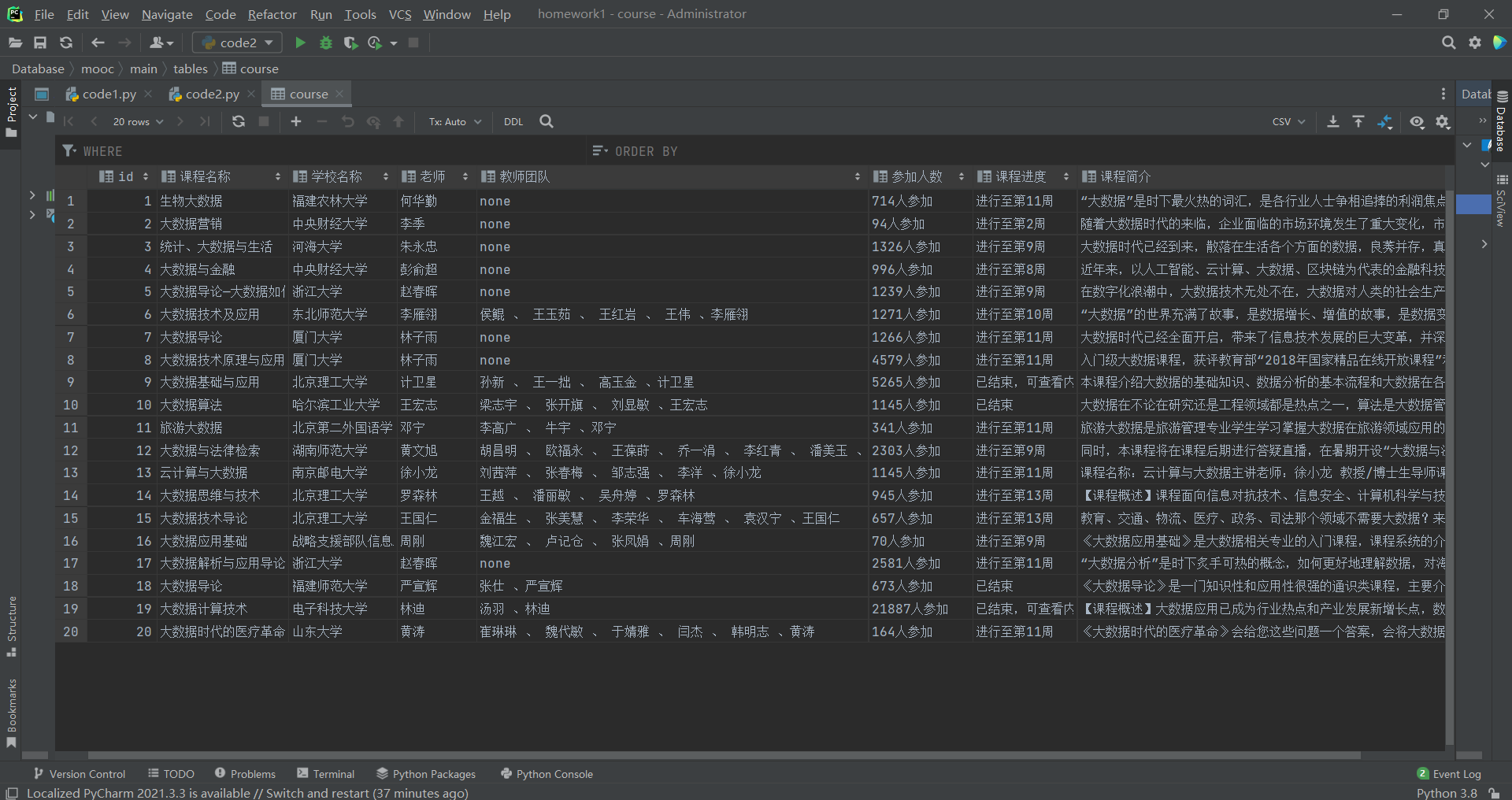
2.2 作业心得
- 使用自动化爬虫显著提高了数据采集的效率。与人工操作相比,它能够在极短的时间内完成大量数据的抓取,极大地节省了时间和人力成本。
- 应对网站的反爬机制需要在爬虫设计中增加适当的延时与随机性,这样的话更加逼真。
作业③:
要求:完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务
3.1过程
1.Python脚本生成测试数据

2.配置Kafka
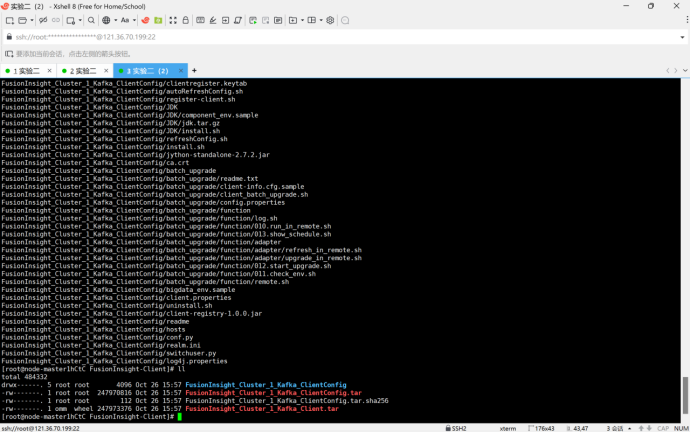
3.安装Flume客户端
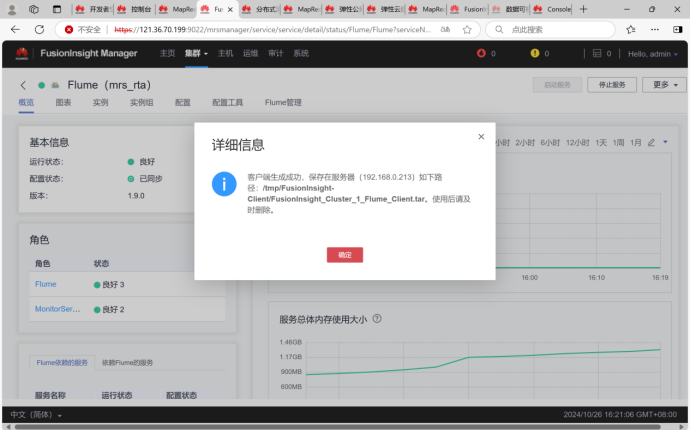
4.MySQL中准备结果表与维度表数据
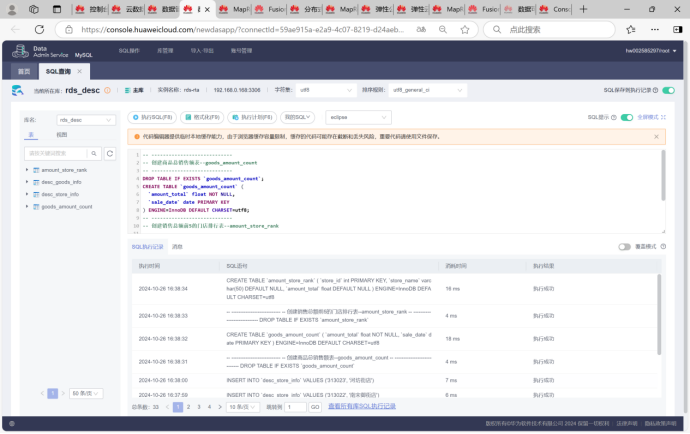
5.使用DLI中的Flink作业进行数据分析
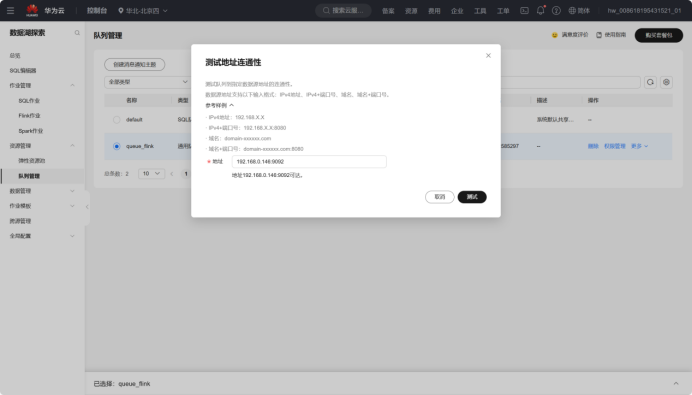
直接全产业链打通!!!
3.2 作业心得
-
为我国之后实现信创国产化,使用国产设备打下了坚实的基础。
-
深入理解了Kafka作为消息队列的配置和使用,学习了如何将数据从Flume传输到Kafka。
-
安装并配置Flume客户端进行数据采集,学习了数据采集的基本流程和配置技巧。
-
将数据从Kafka传输到MySQL数据库,完整体验了从数据源到消息传输,再到数据存储的实时数据处理流程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号