
【python爬虫】对站长网址中免费简历模板进行爬取
本篇仅在于交流学习
解析页面
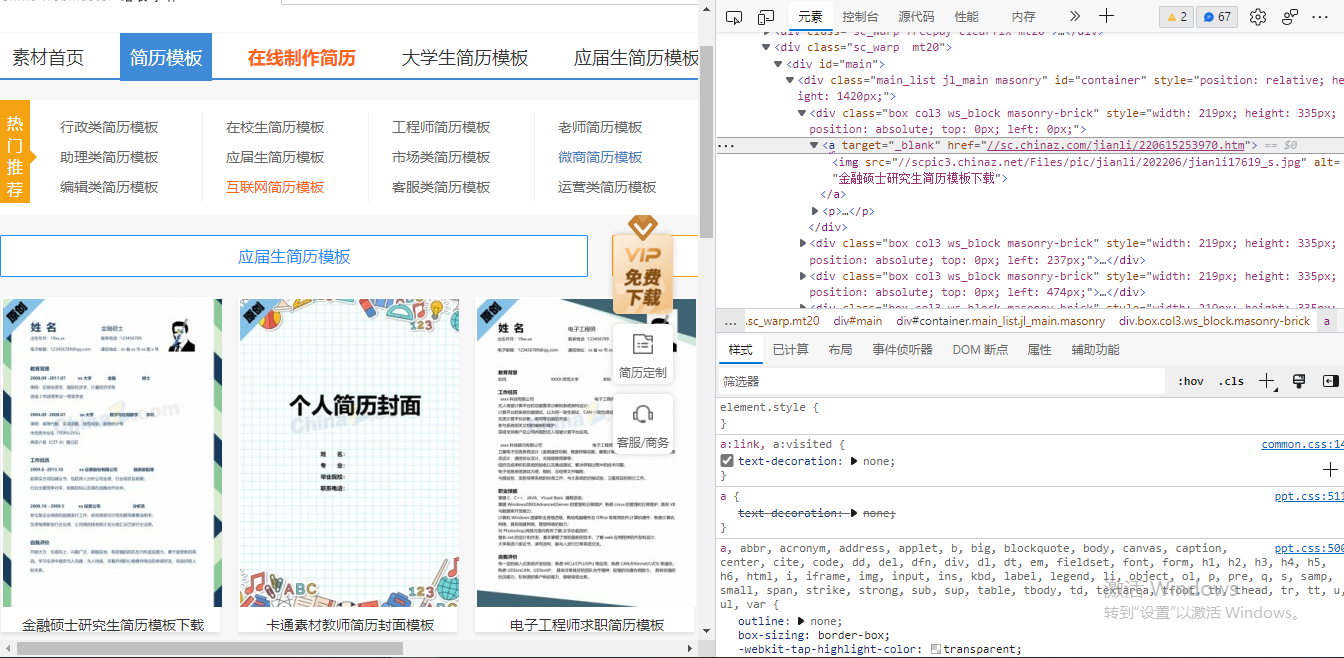
可以采用xpath进行页面连接提取
进入页面
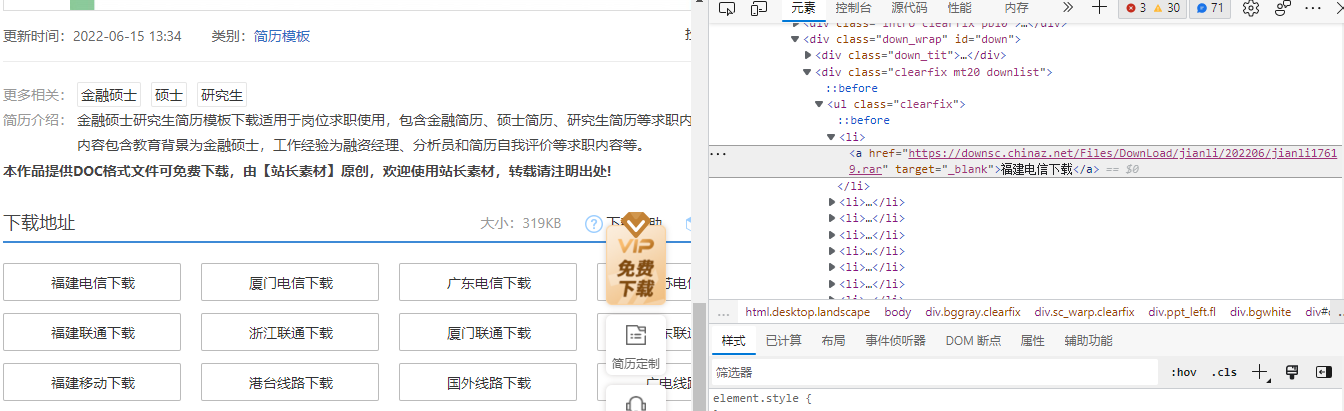
通过进入的页面可以得到下载地址
步骤:
提取表页面模板链接——>进入连接——>提取页面内下载地址连接——>下载保存
headers = {
'User-Agent': '用自己得头部'
}
response = requests.get(url=url, headers=headers).text #解析页面
tree = etree.HTML(response)
#print(tree)
page_list = tree.xpath('//div[@id="main"]/div/div/a') #捕获信息位置
for li in page_list:
page_list_url = li.xpath('./@href')[0]
page_list_url = 'https:' + page_list_url #提取页面地址
#print(page_list_url)
in_page = requests.get(url=page_list_url,headers=headers).text #进入地址
trees = etree.HTML(in_page)
#print(trees)
download_url = trees.xpath('//div[@class="clearfix mt20 downlist"]/ul/li/a/@href')[0] #目的文件地址
name = trees.xpath('//div[@class="ppt_tit clearfix"]/h1/text()')[0] + '.rar' #文件名字
name = name.encode('iso-8859-1').decode('utf-8') #修改命名乱码
#print(download_url)
if not os.path.exists('./download'): #保存
os.mkdir('./download')
download = requests.get(url=download_url,headers=headers).content
page_name = 'download/' + name
with open(page_name,'wb') as fp:
fp.write(download)
print(name,'end!')
分析网页之间联系:
实施多页面提取
try:
start = int(input('请输入要爬取到的尾页:'))
if start == 1 :
url = 'https://sc.chinaz.com/jianli/free.html'
get_page(url)
print("爬取完毕")
elif start == 2 :
url = 'https://sc.chinaz.com/jianli/free.html'
get_page(url)
url = 'https://sc.chinaz.com/jianli/free_2.html'
get_page(url)
print("爬取完毕")
elif start >= 3 :
url = 'https://sc.chinaz.com/jianli/free.html'
get_page(url)
for i in range(2, start):
url = 'https://sc.chinaz.com/jianli/free_%s.html' % (i * 1)
get_page(url)
print("爬取完毕")
except ValueError:
print('请输入数字:')
完整代码:
import requests
from lxml import etree
import os
def get_page(url):
headers = {
'User-Agent': '自己的头部'
}
response = requests.get(url=url, headers=headers).text #解析页面
tree = etree.HTML(response)
#print(tree)
page_list = tree.xpath('//div[@id="main"]/div/div/a') #捕获信息位置
for li in page_list:
page_list_url = li.xpath('./@href')[0]
page_list_url = 'https:' + page_list_url #提取页面地址
#print(page_list_url)
in_page = requests.get(url=page_list_url,headers=headers).text #进入地址
trees = etree.HTML(in_page)
#print(trees)
download_url = trees.xpath('//div[@class="clearfix mt20 downlist"]/ul/li/a/@href')[0] #目的文件地址
name = trees.xpath('//div[@class="ppt_tit clearfix"]/h1/text()')[0] + '.rar' #文件名字
name = name.encode('iso-8859-1').decode('utf-8') #修改命名乱码
#print(download_url)
if not os.path.exists('./download'): #保存
os.mkdir('./download')
download = requests.get(url=download_url,headers=headers).content
page_name = 'download/' + name
with open(page_name,'wb') as fp:
fp.write(download)
print(name,'end!')
def go(): #多页面选择
try:
start = int(input('请输入要爬取到的尾页:'))
if start == 1 :
url = 'https://sc.chinaz.com/jianli/free.html'
get_page(url)
print("爬取完毕")
elif start == 2 :
url = 'https://sc.chinaz.com/jianli/free.html'
get_page(url)
url = 'https://sc.chinaz.com/jianli/free_2.html'
get_page(url)
print("爬取完毕")
elif start >= 3 :
url = 'https://sc.chinaz.com/jianli/free.html'
get_page(url)
for i in range(2, start):
url = 'https://sc.chinaz.com/jianli/free_%s.html' % (i * 1)
get_page(url)
print("爬取完毕")
except ValueError:
print('请输入数字:')
go()
if __name__ == '__main__':
go()
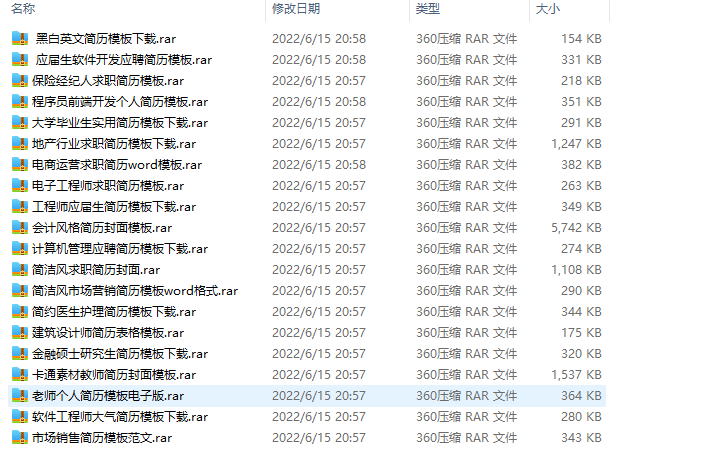
效果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号