
【python】使用爬虫爬取动漫之家漫画全部更新信息
本篇仅在于交流学习
网站名称为:
https://manhua.dmzj.com/
1.首先将相应的库导入:
import requests from lxml import etree
2.确定漫画更新页面上限:

 第一页
第一页
 第二页
第二页
可以确定页面转换是通过修改数字改变网页的
3.使用for循环遍历页面:
for page in range(1,11):
url = 'https://manhua.dmzj.com/update_%s.shtml' % (page * 1)
print(url)
得到漫画更新全网页链接
4.截取网站信息进行分析:
heads = {}
heads['User-Agent'] = '用自己的网页头部'
html = requests.get(url=url, headers=heads).text
list = etree.HTML(html)
5.截取信息:
分析网页内容:
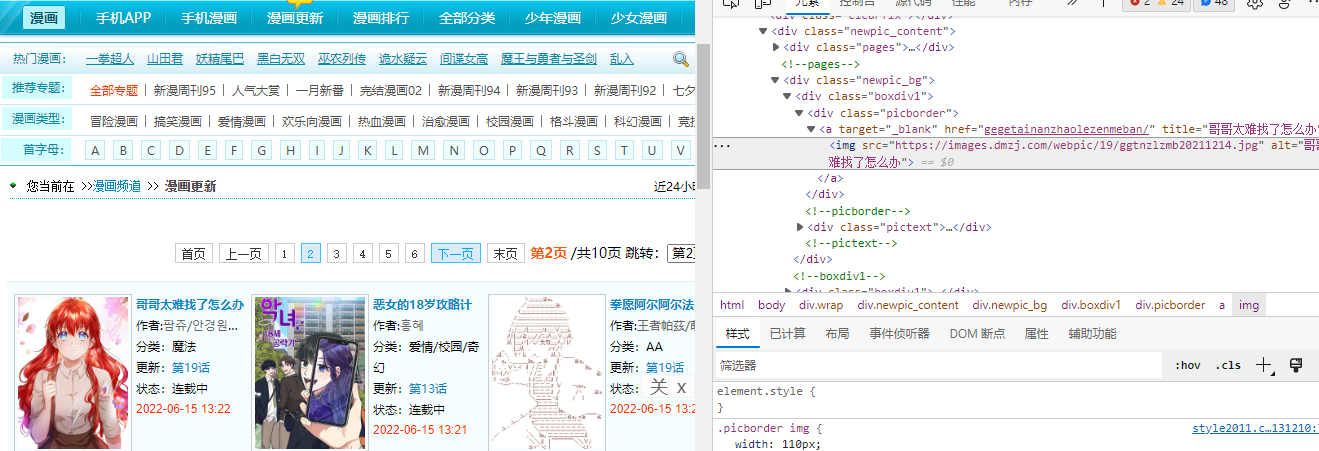
l = list.xpath("//div[@class='boxdiv1']")
for info in l:
title = info.xpath('div/ul/li/a/@title')[0] # 作品名
doc = info.xpath('div/ul/li/text()')[1] # '作者:'
name = info.xpath('div/ul/li/span/text()')[0] # 作者名·-
type = info.xpath('div/ul/li/text()')[2] # 类型
link = info.xpath('div/ul/li/a/@href')[0] # 作品链接
link = 'https://manhua.dmzj.com/' + link
newlink = info.xpath('div/ul/li/a/@href')[1] # 最新作品链接
newlink = 'https://manhua.dmzj.com/' + newlink
buff = info.xpath('div/ul/li/text()')[5] # 作品状态
print(title + " " + doc + name + " " + type + " " + link + " " + buff + " " + newlink + " ")x
效果:

6.完整代码:
import requests
from lxml import etree
for page in range(1,11):
url = 'https://manhua.dmzj.com/update_%s.shtml' % (page * 1)
print(url)
heads = {}
heads['User-Agent'] = '用自己的头部'
html = requests.get(url=url, headers=heads).text
list = etree.HTML(html)
l = list.xpath("//div[@class='boxdiv1']")
for info in l:
title = info.xpath('div/ul/li/a/@title')[0] # 作品名
doc = info.xpath('div/ul/li/text()')[1] # '作者:'
name = info.xpath('div/ul/li/span/text()')[0] # 作者名·-
type = info.xpath('div/ul/li/text()')[2] # 类型
link = info.xpath('div/ul/li/a/@href')[0] # 作品链接
link = 'https://manhua.dmzj.com/' + link
newlink = info.xpath('div/ul/li/a/@href')[1] # 最新作品链接
newlink = 'https://manhua.dmzj.com/' + newlink
buff = info.xpath('div/ul/li/text()')[5] # 作品状态
print(title + " " + doc + name + " " + type + " " + link + " " + buff + " " + newlink + " ")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号