
【python爬虫】bilibili综合热门页面视频图片爬取
此博客仅作为交流学习
我用python来爬取bilibili综合热门页面视频图片
首先分析页面:
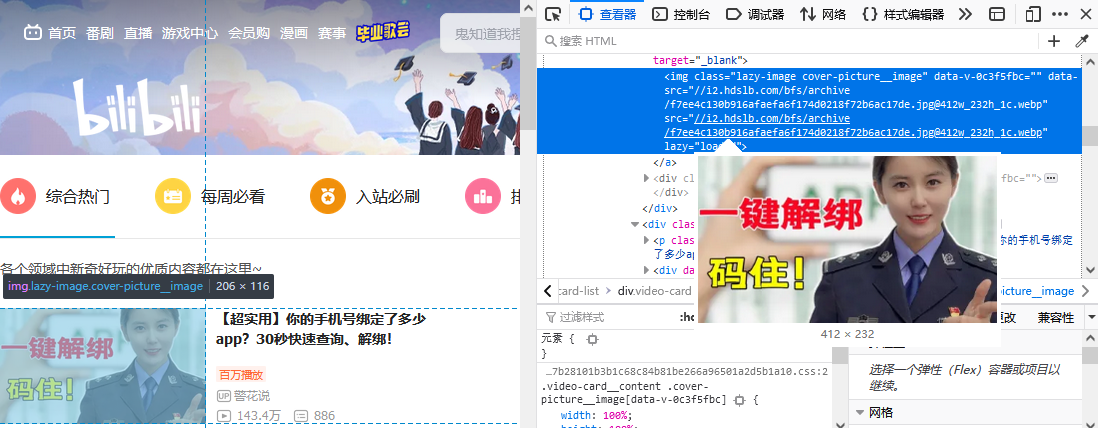
如上图所示,当我们想要在页面爬取图片时,往往得不到页面图片的地址,这时我们也得不到图片
开始抓包分析:
点击Network,CTRL+R开始抓包点击下面页面
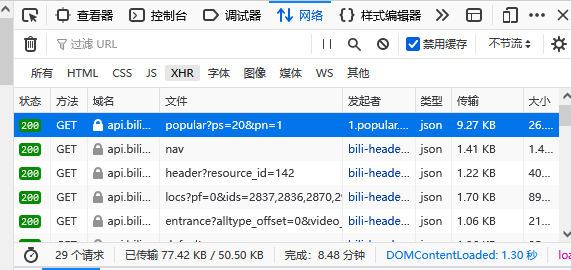
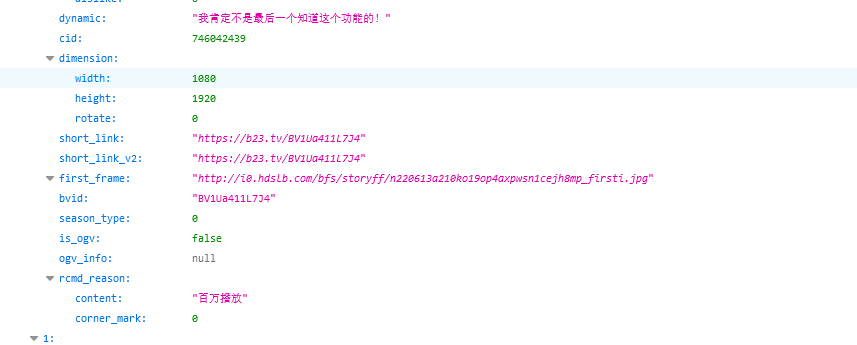
发现页面是json
那么,只要进入当前页面解析并提取页面信息便可以拿到图片地址,进而得到视频封面了
查看响应
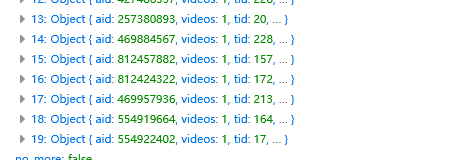
发现抓包得到的页面信息有限,只有热门页面的一部分
下拉页面发现

出现了当前页面又一信息链接
那么根据观察发现,只有不断下拉时,页面就会开始加载信息
根据抓包页面链接进行for循环解析页面提取数据并保存信息:
import requests
import pprint
import time
for i in range(1,12):
url = 'https://api.bilibili.com/x/web-interface/popular?ps=20&pn=' + str(i)
response = requests.get(url=url)
data = response.json()
#pprint.pprint(data) #将页面内容规范为易懂可视页面
card = data['data']['list']
#print(card)
for card in card:
pic = card.get('pic',None) #图片地址获取
title = card.get('title',None)
# print([pic,title])
imgname = pic.split('/')[-1]
img = requests.get(pic)
with open(imgname, 'wb') as file:
file.write(img.content)
print(imgname)
time.sleep(2)
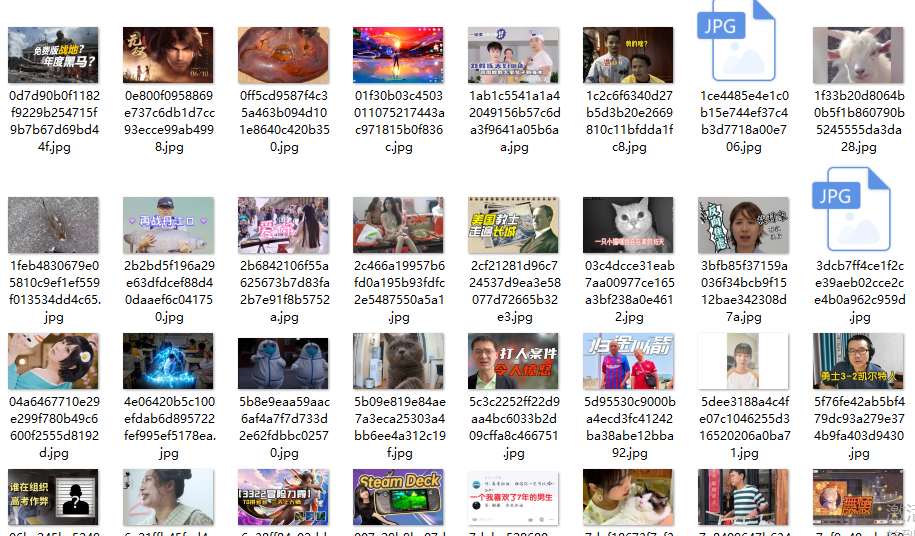
效果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号