
【python爬虫】bilibili每周必看页面视频图片爬取
此博客仅作为交流学习
对于使用bilibili上学习和娱乐的小伙伴们有时会看到视频博主发布的视频封面好看想要得到,但是苦于没有方法,这次我用python来爬取bilibili每周必看页面视频图片。
首先分析页面:
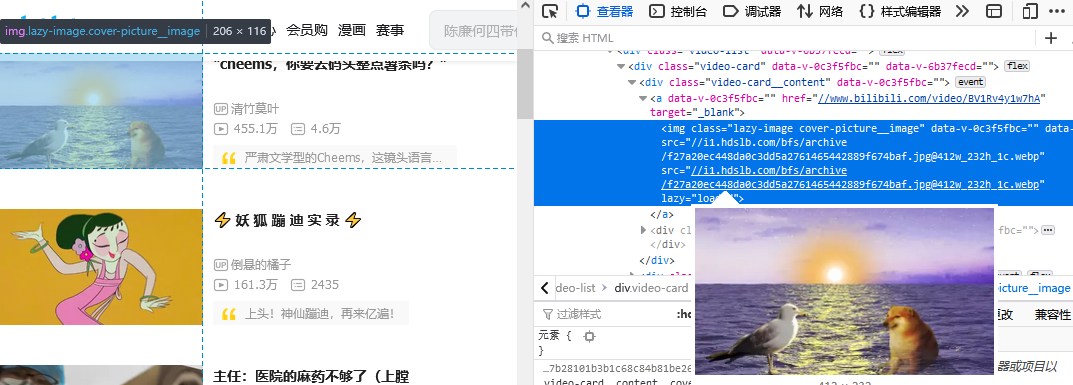
如上图所示,当我们想要在页面爬取图片时,往往得不到页面图片的地址,这时我们也得不到图片
开始抓包分析:
点击Network,CTRL+R开始抓包点击下面页面
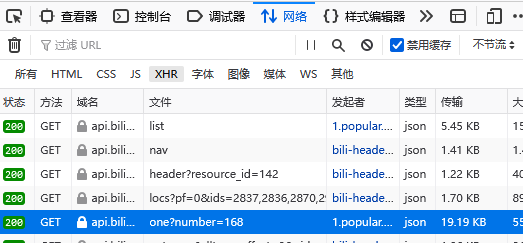
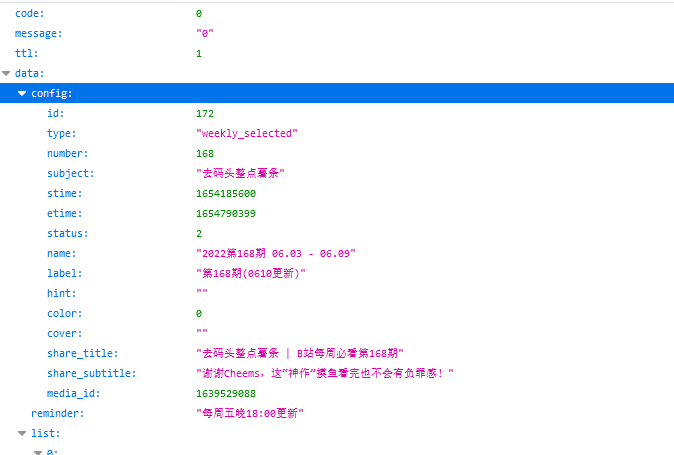
发现页面是json
那么,只要进入当前页面解析并提取页面信息便可以拿到图片地址,进而得到视频封面了
import requests import pprint url = 'https://api.bilibili.com/x/web-interface/popular/series/one?number=168' #抓包网页 response = requests.get(url=url) data = response.json() pprint.pprint(data) #将页面内容规范为易懂可视页面
分析页面:
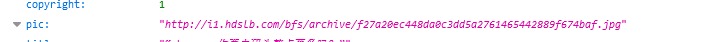
解析并保存:
card = data['data']['list']
#print(card)
for card in card:
pic = card.get('pic',None) #图片地址获取
title = card.get('title',None)
print([pic,title])
imgname = pic.split('/')[-1]
img = requests.get(pic)
with open(imgname, 'wb') as file:
file.write(img.content)
print(imgname)
效果:
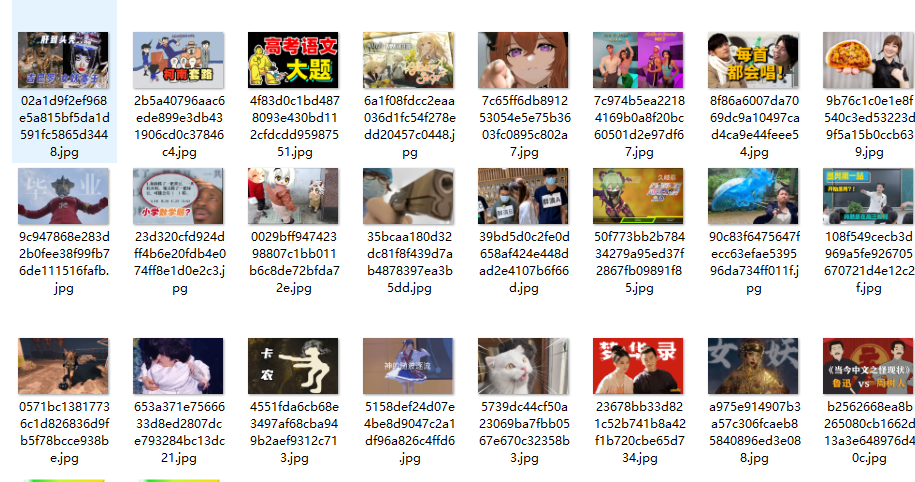
完整代码:
import requests
import pprint
url = 'https://api.bilibili.com/x/web-interface/popular/series/one?number=168'
response = requests.get(url=url)
data = response.json()
#pprint.pprint(data) #将页面内容规范为易懂可视页面
card = data['data']['list']
#print(card)
for card in card:
pic = card.get('pic',None) #图片地址获取
title = card.get('title',None)
print([pic,title])
imgname = pic.split('/')[-1]
img = requests.get(pic)
with open(imgname, 'wb') as file:
file.write(img.content)
print(imgname)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号