PyTorch 中,nn 与 nn.functional 有什么区别?
链接:https://www.zhihu.com/question/66782101/answer/579393790
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
两者的相同之处:
nn.Xxx和nn.functional.xxx的实际功能是相同的,即nn.Conv2d和nn.functional.conv2d都是进行卷积,nn.Dropout和nn.functional.dropout都是进行dropout,。。。。。;- 运行效率也是近乎相同。
nn.functional.xxx是函数接口,而nn.Xxx是nn.functional.xxx的类封装,并且nn.Xxx都继承于一个共同祖先nn.Module。这一点导致nn.Xxx除了具有nn.functional.xxx功能之外,内部附带了nn.Module相关的属性和方法,例如train(), eval(),load_state_dict, state_dict 等。
两者的差别之处:
- 两者的调用方式不同。
nn.Xxx 需要先实例化并传入参数,然后以函数调用的方式调用实例化的对象并传入输入数据。
inputs = torch.rand(64, 3, 244, 244)
conv = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, padding=1)
out = conv(inputs)
nn.functional.xxx同时传入输入数据和weight, bias等其他参数 。
weight = torch.rand(64,3,3,3)
bias = torch.rand(64)
out = nn.functional.conv2d(inputs, weight, bias, padding=1)
nn.Xxx继承于nn.Module, 能够很好的与nn.Sequential结合使用, 而nn.functional.xxx无法与nn.Sequential结合使用。
fm_layer = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(num_features=64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
nn.Dropout(0.2)
)
nn.Xxx不需要你自己定义和管理weight;而nn.functional.xxx需要你自己定义weight,每次调用的时候都需要手动传入weight, 不利于代码复用。
使用nn.Xxx定义一个CNN 。
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.cnn1 = nn.Conv2d(in_channels=1, out_channels=16, kernel_size=5,padding=0)
self.relu1 = nn.ReLU()
self.maxpool1 = nn.MaxPool2d(kernel_size=2)
self.cnn2 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=5, padding=0)
self.relu2 = nn.ReLU()
self.maxpool2 = nn.MaxPool2d(kernel_size=2)
self.linear1 = nn.Linear(4 * 4 * 32, 10)
def forward(self, x):
x = x.view(x.size(0), -1)
out = self.maxpool1(self.relu1(self.cnn1(x)))
out = self.maxpool2(self.relu2(self.cnn2(out)))
out = self.linear1(out.view(x.size(0), -1))
return out
使用nn.function.xxx定义一个与上面相同的CNN。
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.cnn1_weight = nn.Parameter(torch.rand(16, 1, 5, 5))
self.bias1_weight = nn.Parameter(torch.rand(16))
self.cnn2_weight = nn.Parameter(torch.rand(32, 16, 5, 5))
self.bias2_weight = nn.Parameter(torch.rand(32))
self.linear1_weight = nn.Parameter(torch.rand(4 * 4 * 32, 10))
self.bias3_weight = nn.Parameter(torch.rand(10))
def forward(self, x):
x = x.view(x.size(0), -1)
out = F.conv2d(x, self.cnn1_weight, self.bias1_weight)
out = F.relu(out)
out = F.max_pool2d(out)
out = F.conv2d(x, self.cnn2_weight, self.bias2_weight)
out = F.relu(out)
out = F.max_pool2d(out)
out = F.linear(x, self.linear1_weight, self.bias3_weight)
return out
上面两种定义方式得到CNN功能都是相同的,至于喜欢哪一种方式,是个人口味问题,但PyTorch官方推荐:具有学习参数的(例如,conv2d, linear, batch_norm)采用nn.Xxx方式,没有学习参数的(例如,maxpool, loss func, activation func)等根据个人选择使用nn.functional.xxx或者nn.Xxx方式。但关于dropout,个人强烈推荐使用nn.Xxx方式,因为一般情况下只有训练阶段才进行dropout,在eval阶段都不会进行dropout。使用nn.Xxx方式定义dropout,在调用model.eval()之后,model中所有的dropout layer都关闭,但以nn.function.dropout方式定义dropout,在调用model.eval()之后并不能关闭dropout。
class Model1(nn.Module):
def __init__(self):
super(Model1, self).__init__()
self.dropout = nn.Dropout(0.5)
def forward(self, x):
return self.dropout(x)
class Model2(nn.Module):
def __init__(self):
super(Model2, self).__init__()
def forward(self, x):
return F.dropout(x)
m1 = Model1()
m2 = Model2()
inputs = torch.rand(10)
print(m1(inputs))
print(m2(inputs))
print(20 * '-' + "eval model:" + 20 * '-' + '\r\n')
m1.eval()
m2.eval()
print(m1(inputs))
print(m2(inputs))
输出:
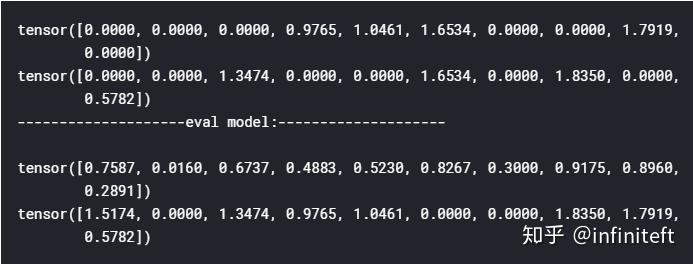
从上面输出可以看出m2调用了eval之后,dropout照样还在正常工作。当然如果你有强烈愿望坚持使用nn.functional.dropout,也可以采用下面方式来补救。
class Model3(nn.Module):
def __init__(self):
super(Model3, self).__init__()
def forward(self, x):
return F.dropout(x, training=self.training)
什么时候使用nn.functional.xxx,什么时候使用nn.Xxx?
这个问题依赖于你要解决你问题的复杂度和个人风格喜好。在nn.Xxx不能满足你的功能需求时,nn.functional.xxx是更佳的选择,因为nn.functional.xxx更加的灵活(更加接近底层),你可以在其基础上定义出自己想要的功能。
个人偏向于在能使用nn.Xxx情况下尽量使用,不行再换nn.functional.xxx ,感觉这样更能显示出网络的层次关系,也更加的纯粹(所有layer和model本身都是Module,一种和谐统一的感觉)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号