机器学习公开课笔记(6):应用机器学习的建议
应用机器学习的建议
1. 评估学习算法
在实际中应用学习算法时,如何评估一个学习算法的好坏?进一步地,如果学习的算法的效果不太好,如何改进学习算法?例如,对于一个简单的线性拟合模型,改进算法效果的策略包括:
- 采用更多的训练实例训练模型
- 采用更小的特征集合
- 增加额外的特征
- 尝试高次项拟合($x_1^2$, $x_2^2$, $x_3^3$, $\ldots$)
- 增加惩罚项系数$\lambda$
- 减小惩罚项系数$\lambda$
机器学习算法诊断(ML diagnostic)负责发现学习算法中存在的问题,通过恰当的策略提高它的性能,尽管该过程会需要一定的时间实现,然而这样的代价是物超所值的。
评估假设(Evaluating a hypothesis)

图1. 机器学习中的过拟合问题
如果使用全部的数据集训练模型,该模型可能在训练集上表现良好,然而泛化到新的实例上效果显著下降,即出现过拟合问题(如图1所示)。需要对假设进行验证,一种合理的方式是将数据集分为训练集(training set)和测试集(test set)两部分: 首先使用训练集训练模型,获得参数$\theta$; 然后在测试集上计算$J_{\text{test}}(\theta)$.
对于线性回归问题:$$J_{\text{test}}(\theta) = \frac{1}{2m_{\text{test}}}\left[\sum\limits_{i=1}^{m_{\text{test}}}(h_{\theta}(x^{(i)})-y^{(i)})\right]$$
对于0-1分类问题:$$J_{\text{test}}(\theta) = \frac{1}{m_{\text{test}}}\sum\limits_{i=1}^{m_{\text{test}}}err(h_{\theta}(x^{(i)}), y^{(i)})$$ 其中$$err(h_{\theta}(x^{(i)}), y^{(i)}) = \left\{ \begin{aligned} 1 &\quad If\quad h_{\theta}(x) \geq 0.5\quad and\quad y = 0 \\ 1 &\quad If\quad h_{\theta}(x) < 0.5 \quad and \quad y = 1\\ 0 &\quad otherwise \end{aligned} \right. $$
模型选择(model select) & 训练/验证/测试(training/validation/test)集
对于线性回归模型,根据特征选择的复杂程度,可以用多个模型可供选择,例如可以考虑线性、二次项、三次项、四次项等等,如何从这些模型中选择一个合理的模型呢?按照之前的训练/测试集划分,我们可以使用训练集分别得到各个模型参数,然后在测试集上比较模型的误差,选择误差最小的模型。然而紧接着的一个问题是,在选定了该模型后,我们如何测试模型的效果呢?因为该模型本来就是选择在测试集上误差最小的,所以在测试集上进行验证显然不能得到有效的结论。为此,可以将模型划分三部分训练集(training set)/交叉验证集(cross validation set, cv)/测试集(test set)。在训练集上学习模型参数,在验证集上选择最佳模型,最后在测试集上评估最佳模型的效果。
2. Bias and Variance
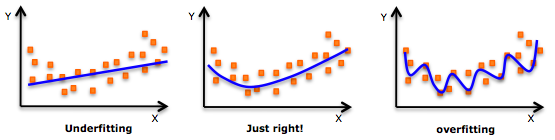
图2. 机器学习中的欠拟合和过拟合问题
学习算法中常见的两类问题是欠拟合问题和过拟合问题(如图2所示),欠拟合的原因主要是因为模型过于简单,因此模型在训练和验证集中的误差都很大且$J_{cv}(\theta) \approx J_{train}(\theta)$;相反,过拟合问题是模型过于复杂,模型在训练集中误差很小(接近于0),然而在验证集中误差非常大,即$J_{cv}(\theta) \gg J_{train}(\theta)$;图3给出了这两种情况的表示。

图3. $J_{train}(\theta)$和$J_{cv}(\theta)$随模型复杂度的变化
2.1 regularization和bias/variance
对于含有regularization的模型,参数$\lambda$的不当选择也会导致模型出现欠拟合和过拟合。以线性回归为例,如果$\lambda$选择过大,那么模型会出现欠拟合;反之如果$\lambda$过小,则容易出现过拟合。通过将数据集划分为训练集/验证集/测试集,然后$\lambda$取一系列值(0, 0.01, 0.02, 0.04, 0.08...), 对于每一个$\lambda$取值用训练集训练参数$\theta$,对于得到的每一个模型,在验证集选择使得错误最小的参数$\lambda$作为模型参数,即$J_{cv}(\theta)$最小。更直观的方式,可以做出$J_{train}(\theta)$和$J_{cv}(\theta)$随$\lambda$的变化曲线(如图4所示),选择最优的$\lambda$。
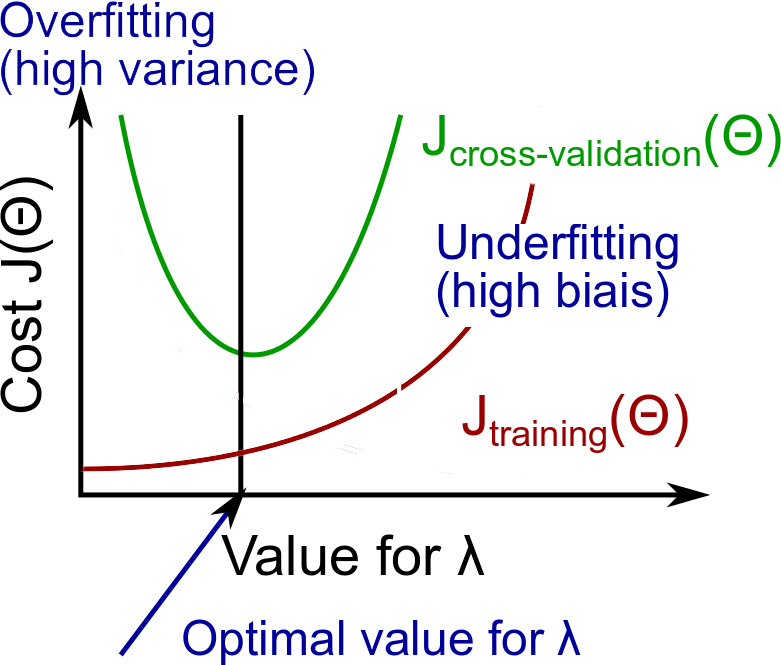
图4. 参数$\lambda$的选择与欠拟合和过拟合的关系
2.2 学习曲线
学习曲线是$J_{train}(\theta)$和$J_{cv}(\theta)$随训练集尺寸的变化曲线,可以用于识别欠拟合和过拟合问题。对于欠拟合,由于模型过于简单,因而训练错误$J_{train}(\theta)$和验证错误$J_{cv}(\theta)$均较大(如图5左所示),增加训练实例并不能改善这种情况;而对于过拟合问题,在训练错误非常小$J_{train}(\theta) \approx 0$而验证错误$J_{cv}(\theta)$很大,两者之间有一个非常大的鸿沟(gap)(如图5右所示),在这种情况下下增加训练实例很有可能改善算法性能。

图5. 学习曲线与欠拟合和过拟合
2.3 总 结
采取恰当的措施解决欠拟合和过拟合问题,采取的措施及其解决的问题如表1所示。
表1. 采取的措施与其解决的欠拟合和过拟合问题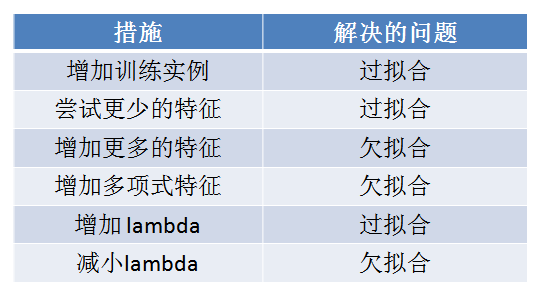
机器学习系统设计
3.1 构建垃圾邮件分类器(spam classfier)
采用监督式学习,构建一个单词表,对于每一封邮件,判断邮件中是否出现单词表中的单词,如果出现对应位置标记为1,反之标记为0,这样将一封邮件映射为一个高维的0-1向量,然后对于垃圾邮件标记为1反之标记为0,从而转化为一个常规的分类问题。
错误分析:
- 从一个简单的算法开始
- plot学习曲线分析算法存在的问题,并采用对应的措施(增加更多数据,增加更多特征等等)
- 人工检查算法在验证集中出现错误分类的情况,进行必要的统计分析。哪类邮件容易被错误划分;哪些特征应该会改善算法;拼写错误邮件占多少,标点误用邮件占多少等等
3.2 处理偏斜数据(skewed data)
例子:对于癌症/非癌症的分类问题,假设y=1表示癌症,y=0表示非癌症,因为癌症的人数必然是少数(不妨假设为1%),那么一个非常naive的算法可以在任何情况下直接返回0,这样表面上该算法的正确率高达99%(因为本来99%的人都是非癌症),然而实际上容易看出,对于癌症患者该算法一个也没有检测出来。如癌症类这样相较于其他类本身的比例与其他类数量差距巨大的类称为偏斜类(skewed class)。为了更好的衡量算法在偏斜数据集上的效果,仅仅使用准确率是不够,因此提出了如下的指标来衡量分类的效果。
Precision/Recall
根据example的实际值和算法对其预测的值,可以将其归为以下四类之一(如表2所示,其中偏斜类标记为1)
- True positive: 算法预测值为1,实际值也为1(算法预测正确)
- False positive:算法预测值为1,实际值为0(算法预测错误)
- False negative:算法预测值为0,实际值为1(算法预测错误)
- True negative:算法预测值为0,实际值为0(算法预测正确)
表2. example分类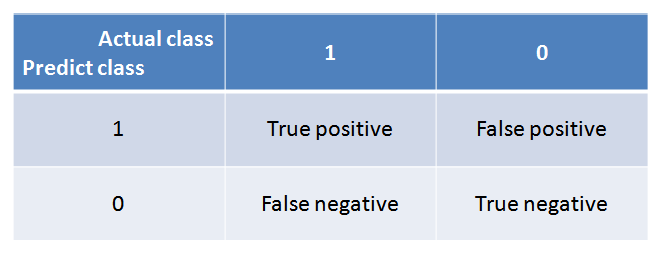
定义precision和recall如下所示,其中precision表示算法预测的癌症患者中真正的癌症患者占多大比列,而recall表示在所有的癌症患者中,算法识别出来了多大比例
$$\text{Precision} = \frac{\text{#True positive}}{\text{#Predict positive}} = \frac{\text{#True positive}}{\text{#True positive} + \text{#False positive}}$$
$$\text{Recall} = \frac{\text{#True positive}}{\text{#Actual positive}} = \frac{\text{#True positive}}{\text{#True positive} + \text{#False negative}}$$
在logistic回归中,对于$h_{\theta}(x)\leq 0.5$预测y=1, 如果提高阈值0.5(比如0.7),那么预测的precision提高,然而与此同时recall会降低;反之如果降低阈值0.5(例如0.3),那么recall会增大,precision会减小;为了在两者之间取得平衡,同时考虑precision和recall定义F1 score为
$$F_1 = \frac{2 \times \text{Precision} \times \text{Recall}}{\text{Precision}+\text{Recall}}$$
3.3 使用大数据集(large data set)
大数据基本原理:选择足够多的特征来预测y值从而避免欠拟合(一个有用的测试是,问该领域内的专家是否能够用这些特征认为地预测y的值),然后使用多参数的学习算法(线性回归/logistic回归/神经网络)等在大数据集上进行训练从而避免过拟合(当数据足够多时,模型不太可能出现过拟合)。

参考文献
[1] Andrew Ng Coursera 公开课第六周
[2] Wikipedia: Bias–variance tradeoff. https://en.wikipedia.org/wiki/Bias%E2%80%93variance_tradeoff
[3] Statistics - Bias-variance trade-off (between overfitting and underfitting). http://gerardnico.com/wiki/data_mining/bias_trade-off
[3] Welcome to the Machine (Learning). http://www.ociweb.com/resources/publications/sett/february-2015-welcome-to-the-machine-learning/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号