
Zabbix常见触发器表达式
Zabbix trigger是zabbix 进行告警通知的设定条件 ,当监控获取的值触发了设定的条件时,会按照触发器的设定,执行相应的action 操作 。在zabbix中为了比较方便的设定各种条件,zabbix为我们设计了相应的函数和操作符 。
一、创建触发器
触发器可以是和模板关联的,也可以是和主机关联的。即在创建模板时,就设定好相应的触发器,和模板相关联的主机同时也关联了触发器,一旦条件满足就执行相应的操作(如告警),我们可以认为他是全局性的;和主机关联的触发器是属于局限性的触发器,该触发只针对特别设定的主机有效,对其他主机无效。
针对全局性触发器和局限性触发器的不同,所以其可以在configuration 下的hosts 里配置trigger ,也可以在 configuration 下的tmplates 里配置 trigger。
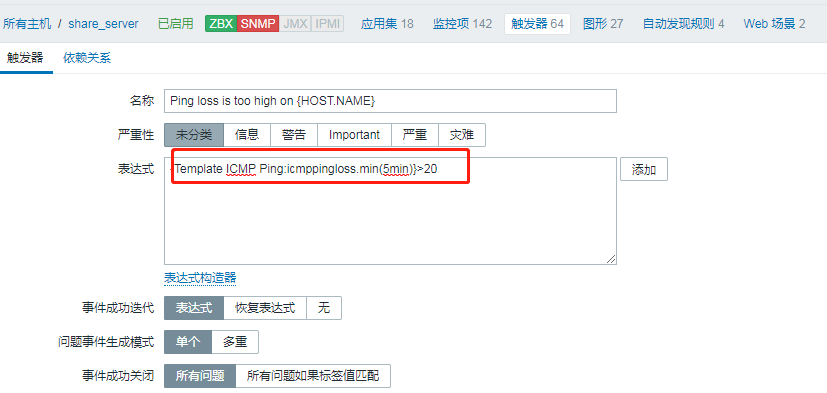
如上图所示,通过设置名称、条件、描述、告警级别等保存并启用即可完成一个触发器的新增。
二、触发器表达式
触发器的表达式即上面的expression里填写的内容,其格式为:
{<server>:<key>.<function>(<parameter>)}<operator><constant>
以上面的截图为例,key为icmppingloss ,function函数是min ,parameter参数值为5分钟 ,运算符是大于 。
1、时间参数
zabbix 触发条件里,很多是对单位时间内的数字参数进行表达式表达的,其中涉及到的常用时间单位如下:
s - seconds (when used, works the same as the raw value)
m - minutes
h - hours
d - days
w - weeks
2、运算符
运算符对应表达式中的operator部分,可以使用的操作符有:
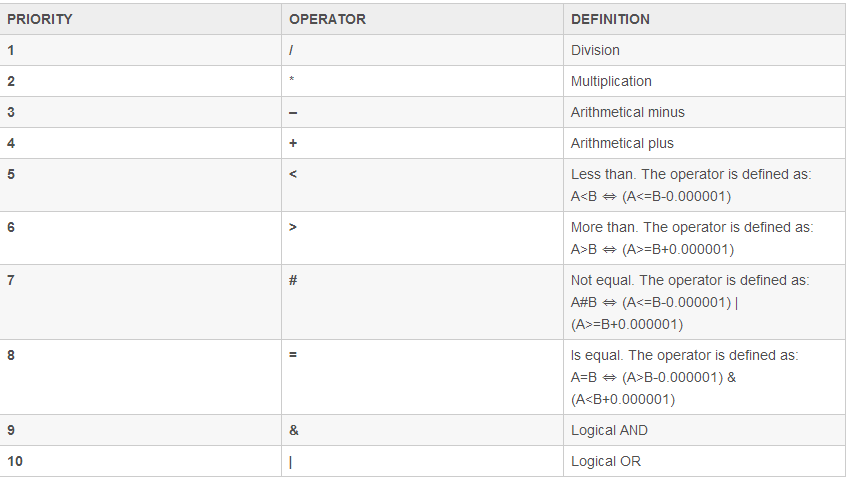
示例:
{www.zabbix.com:system.cpu.load[all,avg1].last(0)}>5
#系统负载大于5
{www.zabbix.com:system.cpu.load[all,avg1].last(0)}>5|{www.zabbix.com:system.cpu.load[all,avg1].min(10m)}>2
#cpu负载大于5或者最后10分钟负载大于2的时候都会报警。
{www.zabbix.com:vfs.file.cksum[/etc/passwd].diff(0)}>0
#/etc/passwd文件改变会报警
{www.zabbix.com:net.if.in[eth0,bytes].min(5m)}>100K
#在最后5分钟,网卡eth0的流量大于100K报警
{smtp1.zabbix.com:net.tcp.service[smtp].last(0)}=0&{smtp2.zabbix.com:net.tcp.service[smtp].last(0)}=0
#两个节点上的smtp服务都宕机才会报警,该表达式用了两个主机
{zabbix.zabbix.com:icmpping.count(30m,0)}>5
#在最后30分钟主机不能ping通的次数大于5就报警
{server:system.cpu.load.avg(1h)}/{server:system.cpu.load.avg(1h,1d)}>2
({TRIGGER.VALUE}=0&{server:temp.last(0)}>20)|
({TRIGGER.VALUE}=1&{server:temp.last(0)}>15)
三、常见表达式函数
avg
参数:秒或#num
支持类型:float,int
作用:返回一段时间的平均值
举例:
avg(5):最后5秒的平均值
avg(#5):表示最近5次得到值的平均值
avg(3600,86400):表示一天前的一个小时的平均值
如果仅有一个参数,表示指定时间的平均值,从现在开始算起,如果有第二个参数,表示漂移,从第二个参数前开始算时间,
#n表示最近n次的值
max
参数:秒或#num
支持值类型:float,int
描述:返回指定时间间隔的最大值.时间间隔作为第一个参数可以是秒或收集值的数目(前缀为#).
min
参数:秒或#num
支持值类型:float,int
描述:返回指定时间间隔的最小值.时间间隔作为第一个参数可以是秒或收集值的数目(前缀为#).
sum
参数:秒或#num
支持值类型:float,int
描述:返回指定时间间隔中收集到的值的总和.时间间隔作为第一个参数支持秒或收集值的数目(以#开始).
count
参数:秒或#num
支持类型:float,int,str,text,log
作用:返回指定时间间隔内数值的统计,
举例:
count(600)最近10分钟得到值的个数
count(600,12)最近10分钟得到值的个数等于12
count(600,12,"gt")最近10分钟得到值的个数大于12
count(#10,12,"gt")最近10个值中,值大于12的个数
count(600,12,"gt",86400)24小时之前的10分钟内值大于12的个数
count(600,6/7,"band") .在3个最低有效位中以二进制形式存在的最后10分钟的数值。
count(600,,,86400)24小时之前的10分钟数据值的个数
第一个参数:指定时间段
第二个参数:样本数据
第三个参数:操作参数
第四个参数:漂移参数
#支持的操作类型
eq: 相等
ne: 不相等
gt: 大于
ge: 大于等于
lt: 小于
le: 小于等于
like: 内容匹配
diff
参数:忽略
支持值类型:float,int,str,text,log
作用:返回值为1表示最近的值与之前的值不同,0为其他情况
last
参数:秒或#num
支持值类型:float,int,str,text,log
作用:最近的值,如果为秒,则忽略,#num表示最近第N个值,请注意当前的#num和其他一些函数的#num的意思是不同的
例子:
last(0)等价于last(#1)
last(#3)表示最近第3个值(并不是最近的三个值)本函数也支持第二个参数time_shift,例如last(0,86400)返回一天前的最近的值
如果在history中同一秒中有多个值存在,Zabbix不保证值的精确顺序
#num从Zabbix1.6.2起开始支持,timeshift从1.8.2其开始支持,可以查询avg()函数获取它的使用方法
logsource
参数:string
支持值类型:log
描述:检查最近的日志条目是否匹配参数的日志来源.当返回值为0时表示不匹配,1表示匹配。通常用于Windowseventlogs监控.例如logsource[“VMWareServer”]
time
参数:忽略
支持值类型:any
描述:返回当前时间,格式为HHMMSS,例如123055
date
参数:忽略
支持类型:any
作用:返回当前的时间,格式YYYYMMDD
dayofmonth
返回当前是本月的第几天
dayofweek
返回当前是本周的第几天
delta
参数:秒或#num
支持类型:float,int
作用:返回时间间隔内的最大值与最小值的差值
nodata
参数:秒
支持值类型:any
描述:当返回值为1表示指定的间隔(间隔不应小于30秒)没有接收到数据,0表示其他.
now
参数:忽略
支持值类型:any
描述:返回距离Epoch(1970年1月1日00:00:00UTC)时间的秒数
概述
触发器中的表达式使用很灵活,我们可以创建一个复杂的逻辑测试监控,触发器表达式形式如下:
{<server>:<key>.<function>(<parameter>)}<operator><constant>
{主机:key.函数(参数)}<表达式>常数
Functions函数
触发器functions可以引用检索到的值,当前时间或者其他元素。触发器表达式支持的function完整列表请点击官网地址 supported functions
Function参数
大多数数值functions可以使用秒来作为参数。你可以使用前缀“#”来表示它有不同的含义
FUNCTION CALL 描述
sum(600) 600秒内的总和
sum(#5) 最新5个值的和
last函数使用不同的参数将会得到不同的值,#2表示倒数第二新的数据。例入从老到最新值为1,2,3,4,5,6,7,8,9,10,last(#2)得到的值为9,last(#9)得到的值为2。last函数必须包含参数。
AVG,count,last,min和max函数还支持额外的参数,以秒为单位的参数time_shift(时间偏移量)。例如avg(1h,1d),那么将会获取到昨天的1小时内的平均数据。
注:触发器表达式需要使用history历史数据来计算,如果history不可用(time_shift时间偏移量参数无法使用),因此history记录一定要保留长久一点,至少要保留需要用的记录。
触发器表达式可以使用单位符号来替代大数字,例如5m替代300,或者1d替代86400,1k替代1024字节等等。
操作符
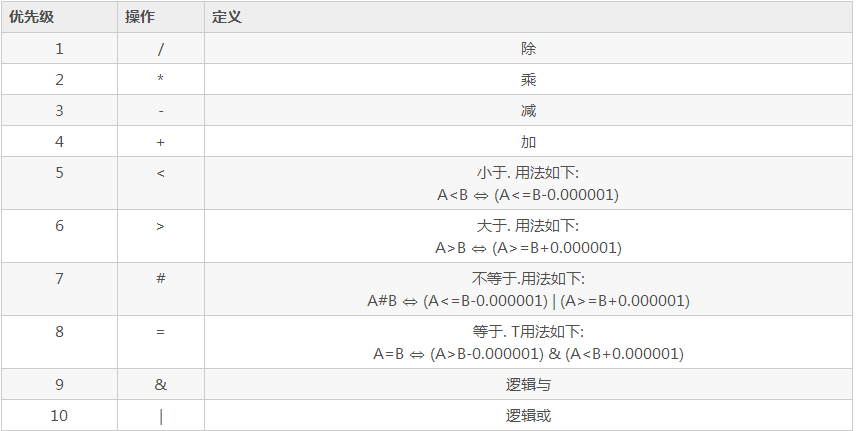
触发器示例
示例一
触发器名称:Processor load is too high on www.zabbix.com
{www.zabbix.com:system.cpu.load[all,avg1].last(0)}>5
触发器说明:
www.zabbix.com:host名称
system.cpu.load[all,avg1]:item值,一分内cpu平均负载值
last(0):最新值
>5:最新值大于5
如上所示,www.zabbix.com这个主机的监控项,最新的CPU负载值如果大于5,那么表达式会返回true,这样一来触发器状态就改变为“problem”了。
示例二
触发器名称:www.zabbix.com is overloaded
{www.zabbix.com:system.cpu.load[all,avg1].last(0)}>5|{www.zabbix.com:system.cpu.load[all,avg1].min(10m)}>2
当前cpu负载大于5或者最近10分内的cpu负载大于2,那么表达式将会返回true.
示例三
触发器名称:/etc/passwd has been changed
使用函数 diff():
{www.zabbix.com:vfs.file.cksum[/etc/passwd].diff(0)}>0
/etc/passwd最新的checksum与上一次获取到的checksum不同,表达式将会返回true. 我们可以使用同样的方法监控系统重要的配置文件,例如/etc/passwd,/etc/inetd.conf等等。这些zabbix一般都会自带,没带的你自己加上吧。
示例四
触发器名称:Someone is downloading a large file from the Internet
使用函数 min:
{www.zabbix.com:net.if.in[eth0,bytes].min(5m)}>100K
当前主机网卡eth0最后5分钟内接收到的流量超过100KB那么触发器表达式将会返回true
示例五
触发器名称:Both nodes of clustered SMTP server are down
{smtp1.zabbix.com:net.tcp.service[smtp].last(0)}=0&{smtp2.zabbix.com:net.tcp.service[smtp].last(0)}=0
当smtp1.zabbix.com和smtp2.zabbix.com两台主机上的SMTP服务器都离线,表达式将会返回true.
示例六
触发器名称:Zabbix agent needs to be upgraded
使用函数str():
{zabbix.zabbix.com:agent.version.str("beta8")}=1
如果当前zabbix agent版本包含beta8(假设当前版本为1.0beta8),这个表达式会返回true.
示例七
触发器名称:Server is unreachable
{zabbix.zabbix.com:icmpping.count(30m,0)}>5
如上表达式表示最近30分钟zabbix.zabbix.com这个主机超过5次不可到达。
示例八
触发器名称:No heartbeats within last 3 minutes
使用函数 nodata():
{zabbix.zabbix.com:tick.nodata(3m)}=1
tick为Zabbix trapper类型,首先我们要定义一个类型为Zabbix trapper,key为tick的item。我们使用zabbix_sender定期发送数据给tick,如果在3分钟内还未收到zabbix_sender发送来的数据,那么表达式返回一个true,与此同时触发器的值变为“PROBLEM”。
示例九
触发器名称:CPU activity at night time
使用函数 time():
{zabbix:system.cpu.load[all,avg1].min(5m)}>2&{zabbix:system.cpu.load[all,avg1].time(0)}>000000&{zabbix:system.cpu.load[all,avg1].time(0)}<060000
只有在凌晨0点到6点整,最近5分钟内cpu负载大于2,表达式返回true,触发器的状态变更为“problem”
示例十
触发器名称:Check if client local time is in sync with Zabbix server time
使用函数 fuzzytime():
{MySQL_DB:system.localtime.fuzzytime(10)}=0
主机MySQL_DB当前服务器时间如果与zabbix server之间的时间相差10秒以上,表达式返回true,触发器状态改变为“problem”
示例十一
触发器名称:Comparing average load today with average load of the same time yesterday (使用 time_shift 时间偏移量参数).
{server:system.cpu.load.avg(1h)}/{server:system.cpu.load.avg(1h,1d)}>2
This expression will fire if the average load of the last hour tops the average load of the same hour yesterday more than two times.
Hysteresis(迟滞,滞后)
简单的说触发器状态转变为problem需要一个条件,从problem转变回来还需要一个条件才行。一般触发器只需要不满足触发器为problem条件即可恢复。明白了么?不明白就看例子吧。
有时候触发器需要使用不同的条件来表示不同的状态,举个官网很有趣的例子:机房温度正常稳定为15-20°,当温度超过20°,触发器值为problem,直到温度低于15°才会接触警报,异常会解除。
为了达到这个效果,我们需要使用如下触发器表达式:
示例1
触发器名称:Temperature in server room is too high
({TRIGGER.VALUE}=0&{server:temp.last(0)}>20)|
({TRIGGER.VALUE}=1&{server:temp.last(0)}<15)
如上有两个小括号,前面一个表示触发异常的条件,后面一个表达式表示解除异常的条件。
注意:宏变量 {TRIGGER.VALUE}将会返回当前触发器的值
示例2
触发器名称:Free disk space is too low
Problem: 最近5分钟剩余磁盘空间小于10GB。(异常)
Recovery: 最近10分钟磁盘空间大于40GB。(恢复)
简单说便是一旦剩余空间小于10G就触发异常,然后接下来剩余空间必须大于40G才能解除这个异常,就算你剩余空间达到了39.9G(不在报警条件里)那也是没用的
({TRIGGER.VALUE}=0&{server:vfs.fs.size[/,free].max(5m)}<10G)
({TRIGGER.VALUE}=1&{server:vfs.fs.size[/,free].min(10m)}<40G)
以上就是常用的触发器的知识

 浙公网安备 33010602011771号
浙公网安备 33010602011771号