
复现基于Pytorch的YOLOv3所踩的坑~
先上图!

十天+两台电脑才摸索出来的~~!
环境:
Ubuntu18.04+RTX3090+CUDA11.0+Cudnn v8+Pytorch-nightly
没错,是3090!(手动滑稽)
第一个坑:Windows(尤其是Win7)属实不行,Pytorch装不上,另外3090只能搭配Pytorch-nightly版本,而且这个版本没有国内源。
如果你的下载源是国内的,还要恢复默认源才可以。
复现的代码选择是github上6k star的那个。
数据集选择COCO2017数据集(后续会介绍)
说实话,一开始老是报错,我还以为是代码的问题,事实上是菜罢了。(要不是身边的人说,肯定是你的问题,我真的不确定会不会继续搞下去)
ctrl+v
然后就会有第一个错误(大概意思就是downloading weights...),如果你的电脑不能FQ,那么在2分钟之后就会报错,下载失败,然后运行失败(FQ的电脑能不能继续运行我不清楚,如果能运行,那么每次运行程序都要下载一次)。
错误的原因是:weights文件夹下的download_yolov3_weights.sh文件,每次运行程序都会去执行这个文件。
解决:预先下载好weights放到weights文件夹下,just like this
解决之后继续运行,会报第二个错误(找不到文件夹coco.2017.txt....)
错误的原因就在数据集了。
下载的coco2017数据集约(30G)包括train_2017,val_2017约20G的图片,和annotations_trainval2017的label。
需要对label处理一下,解压的label你会发现并不是真正的标签,而是6个json文件,6个json文件分别是描述图片(看图说话)、人体关键点检测和目标检测的训练json和测试json。
程序中是读的txt,所以要对json文件进行处理,以目标检测为例:
json-->xml-->txt(这是我的代码,好像json可以直接到txt?)
每份json文件会得到两个txt,分别是包含图片名称的txt和包含标签的txt(分类和box 坐标)

这里修改包含图片名称的txt文件位置。
重点来了!!!
要把包含标签的txt复制到训练图片train_2017中,不然会报错(找不到label...)
然后继续运行...
success!
以3090的算力单次运行train为30分钟左右,300个循环共花了7天~
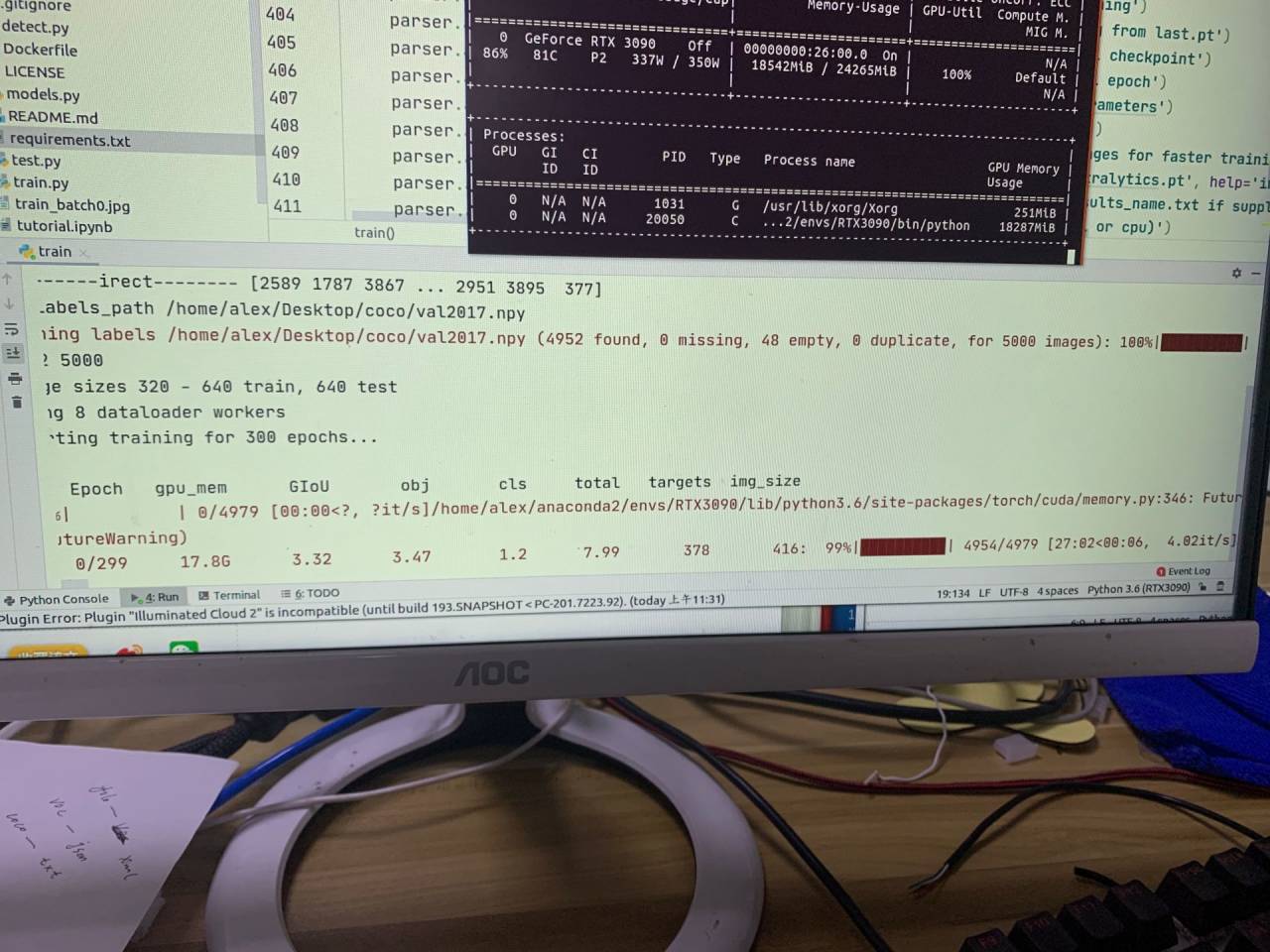
确实值得纪念~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号