Django复习
HTTP协议
http协议
请求信息格式
GET / HTTP/1.1 请求行
Host: 127.0.0.1:8003 请求头
Connection: keep-alive
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
#空行
请求数据 username=ziwen password=666
get请求 请求数据部分是没有数据的,get请求的数据在url上,在请求行里面,有大小限制,常见的get请求方式: 浏览器输入网址,a标签
post请求 请求数据在请求体(请求数据部分) ,数据没有大小限制, 常见方式:form表单提交数据
MVC和MTV框架模式
MVC:
M -- models 数据库相关
V -- views 视图相关(逻辑)
C -- controller url控制器(url分发器,路由分发)
django -- MTV
M -- models 数据库相关
T -- templates HTML相关 html就是模板
V -- views 视图相关(逻辑)
+ controller url控制器(url分发器,路由分发)
django下载安装
下载
pip3 install django==1.11.9
pip3 install django==1.11.9 -i http://xxxxxx 指定源
创建项目
django-admin startproject mysite 创建了一个名为"mysite"的Django 项目
启动项目
python manage.py runserver 默认是127.0.0.1:8000
python manage.py runserver 127.0.0.1 默认端口号是8000
python manage.py runserver 127.0.0.1:8001
django的url路由分发
# url(r'^articles/(\d+)/(\d+)/', views.articles), #articles/2019/9/
视图函数
def articles(request,year,month): # 位置参数 2019 9
print(year,type(year)) #2019 <class 'str'> #匹配出来的所有数据都是字符串
print(month)
return HttpResponse(year+'年'+ month +'月' +'所有文章')
# 有名分组参数
url(r'^articles/(?P<xx>\d+)/(?P<oo>\d+)/', views.articles), #articles/2019/9/
#xx=2019 oo=9 关键字传参
def articles(request,oo,xx): # 关键字传参 2019 9
print(xx,type(xx)) #2019 <class 'str'> #匹配出来的所有数据都是字符串
print(oo)
return HttpResponse(xx+'年'+ oo +'月' +'所有文章')
HTTPRequest对象就是咱们的视图函数的参数request
# print(request) #<WSGIRequest: GET '/home/'>
# # print(dir(request))
#
# print(request.path) #/home/ 纯路径
# print(request.path_info) #/home/ 纯路径
# print(request.get_full_path()) #/home/?a=1&b=2 全路径(不包含ip地址和端口)
# print(request.META) #请求头相关数据,是一个字典
# print(request.method) #GET
# print(request.GET)
# print(request.POST)
# print(request.body) 能够拿到请求数据部分的数据(post,get没有)
HTTPResponse对象
HTTPResponse('字符串')
render(request,'xx.html')
redirect 重定向#用法 redirect(路径) 示例:redirect('/index/')
FBV和CBV 视图(视图函数和视图类)
类视图 CBV
views.py
from django.views import View
class LoginView(View):
# def dispatch(self, request, *args, **kwargs):
# print('xx请求来啦!!!!')
# ret = super().dispatch(request, *args, **kwargs)
# print('请求处理的逻辑已经结束啦!!!')
# return ret
def get(self,request): #处理get请求直接定义get方法,不需要自己判断请求方法了,源码中用dispatch方法中使用了反射来处理的
print('小小小小')
return render(request,'login.html')
def post(self,request):
print(request.POST)
return HttpResponse('登录成功')
urls.py路由写法
url(r'^login/', views.LoginView.as_view()),
视图加装饰器
视图函数
def wrapper(func):
def inner(*args, **kwargs):
print(11111)
ret = func(*args, **kwargs)
print(22222)
return ret
return inner
@wrapper
def index(request):
print('xxxxx')
return HttpResponse('indexxxxxxxxx')
视图类
from django.utils.decorator import method_decorator
@method_decorator(wrapper,name='get') # 方式3
class LoginView(View):
# @method_decorator(wrapper) #方式2
# def dispatch(self, request, *args, **kwargs):
# print('xx请求来啦!!!!')
#
# ret = super().dispatch(request, *args, **kwargs)
#
# print('请求处理的逻辑已经结束啦!!!')
# return ret
# @method_decorator(wrapper) #方式1
def get(self,request):
print('小小小小')
return render(request,'login.html')
def post(self,request):
print(request.POST)
return HttpResponse('登录成功')
模板渲染
{{ 变量 }} {% 逻辑 %} -- 标签
万能的点
<h1>91李业网</h1>
<h2>{{ name }}</h2>
<h2>{{ d1.items }}</h2>
<h2>我是"{{ l1.1 }}"</h2>
<h2>{{ num }}</h2>
<h2>{{ obj.p }}</h2> #如果调用的方法需要传参,sorry用不了
三 过滤器
在Django的模板语言中,通过使用 过滤器 来改变变量的显示。
过滤器的语法: {{ value|filter_name:参数 }}
使用管道符"|"来应用过滤器。
例如:{{ name|lower }}会将name变量应用lower过滤器之后再显示它的值。lower在这里的作用是将文本全都变成小写。
注意事项:
- 过滤器支持“链式”操作。即一个过滤器的输出作为另一个过滤器的输入。
- 过滤器可以接受参数,例如:{{ sss|truncatewords:30 }},这将显示sss的前30个词。
- 过滤器参数包含空格的话,必须用引号包裹起来。比如使用逗号和空格去连接一个列表中的元素,如:{{ list|join:', ' }}
- '|'左右没有空格没有空格没有空格
Django的模板语言中提供了大约六十个内置过滤器。
default
如果一个变量是false或者为空,使用给定的默认值。 否则,使用变量的值。
{{ value|default:"nothing"}}
如果value没有传值或者值为空的话就显示nothing
length
返回值的长度,作用于字符串和列表。
{{ value|length }}
返回value的长度,如 value=['a', 'b', 'c', 'd']的话,就显示4.
filesizeformat
将值格式化为一个 “人类可读的” 文件尺寸 (例如 '13 KB', '4.1 MB', '102 bytes', 等等)。例如:
{{ value|filesizeformat }}
如果 value 是 123456789,输出将会是 117.7 MB。
slice
切片,如果 value="hello world",还有其他可切片的数据类型
{{value|slice:"2:-1"}}
date
格式化,如果 value=datetime.datetime.now()
{{ value|date:"Y-m-d H:i:s"}}
关于时间日期的可用的参数(除了Y,m,d等等)还有很多,有兴趣的可以去查查看看。
safe
Django的模板中在进行模板渲染的时候会对HTML标签和JS等语法标签进行自动转义,原因显而易见,这样是为了安全,django担心这是用户添加的数据,比如如果有人给你评论的时候写了一段js代码,这个评论一提交,js代码就执行啦,这样你是不是可以搞一些坏事儿了,写个弹窗的死循环,那浏览器还能用吗,是不是会一直弹窗啊,这叫做xss攻击,所以浏览器不让你这么搞,给你转义了。但是有的时候我们可能不希望这些HTML元素被转义,比如我们做一个内容管理系统,后台添加的文章中是经过修饰的,这些修饰可能是通过一个类似于FCKeditor编辑加注了HTML修饰符的文本,如果自动转义的话显示的就是保护HTML标签的源文件。为了在Django中关闭HTML的自动转义有两种方式,如果是一个单独的变量我们可以通过过滤器“|safe”的方式告诉Django这段代码是安全的不必转义。
我们去network那个地方看看,浏览器看到的都是渲染之后的结果,通过network的response的那个部分可以看到,这个a标签全部是特殊符号包裹起来的,并不是一个标签,这都是django搞得事情。

比如:
value = "<a href='#'>点我</a>" 和 value="<script>alert('123')</script>"
{{ value|safe}}
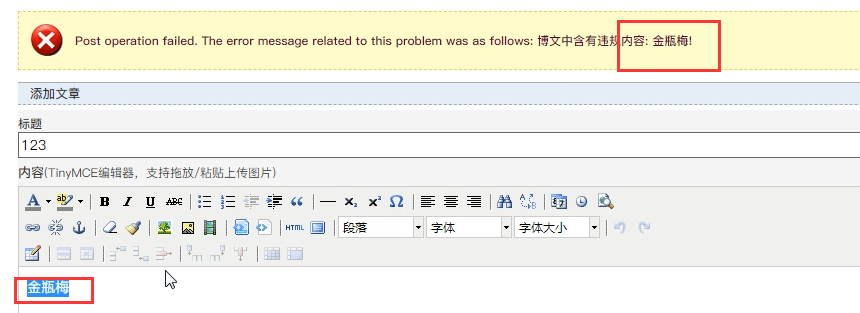
很多网站,都会对你提交的内容进行过滤,一些敏感词汇、特殊字符、标签、黄赌毒词汇等等,你一提交内容,人家就会检测你提交的内容,如果包含这些词汇,就不让你提交,其实这也是解决xss攻击的根本途径,例如博客园:
truncatechars
如果字符串字符多于指定的字符数量,那么会被截断。截断的字符串将以可翻译的省略号序列(“...”)结尾。
参数:截断的字符数
{{ value|truncatechars:9}} #注意:最后那三个省略号也是9个字符里面的,也就是这个9截断出来的是6个字符+3个省略号,有人会说,怎么展开啊,配合前端的点击事件就行啦
truncatewords
在一定数量的字后截断字符串,是截多少个单词。
例如:‘hello girl hi baby yue ma’,
{{ value|truncatewords:3}} #上面例子得到的结果是 'hello girl h1...'
cut
移除value中所有的与给出的变量相同的字符串
{{ value|cut:' ' }}
如果value为'i love you',那么将输出'iloveyou'.
join
使用字符串连接列表,{{ list|join:', ' }},就像Python的str.join(list)
timesince(了解)
将日期格式设为自该日期起的时间(例如,“4天,6小时”)。
采用一个可选参数,它是一个包含用作比较点的日期的变量(不带参数,比较点为现在)。 例如,如果blog_date是表示2006年6月1日午夜的日期实例,并且comment_date是2006年6月1日08:00的日期实例,则以下将返回“8小时”:
{{ blog_date|timesince:comment_date }}
分钟是所使用的最小单位,对于相对于比较点的未来的任何日期,将返回“0分钟”。
timeuntil(了解)
似于timesince,除了它测量从现在开始直到给定日期或日期时间的时间。 例如,如果今天是2006年6月1日,而conference_date是保留2006年6月29日的日期实例,则{{ conference_date | timeuntil }}将返回“4周”。
使用可选参数,它是一个包含用作比较点的日期(而不是现在)的变量。 如果from_date包含2006年6月22日,则以下内容将返回“1周”:
{{ conference_date|timeuntil:from_date }}
这里简单介绍一些常用的模板的过滤器,更多详见
标签
for循环标签
循环列表等
{% for person in person_list %}
<p>{{ person.name }}</p> <!--凡是变量都要用两个大括号括起来-->
{% endfor %}
循环字典
{% for key,val in dic.items %}
<p>{{ key }}:{{ val }}</p>
{% endfor %}
empty
{% for person in person_list %}
<p>{{ person.name }}</p> <!--凡是变量都要用两个大括号括起来-->
{% empty %}
<p>没有找到东西!</p>
{% endfor %}
forloop.counter 当前循环的索引值(从1开始),forloop是循环器,通过点来使用功能
forloop.counter0 当前循环的索引值(从0开始)
forloop.revcounter 当前循环的倒序索引值(从1开始)
forloop.revcounter0 当前循环的倒序索引值(从0开始)
forloop.first 当前循环是不是第一次循环(布尔值)
forloop.last 当前循环是不是最后一次循环(布尔值)
forloop.parentloop 本层循环的外层循环的对象,再通过上面的几个属性来显示外层循环的计数等
示例:
{% for i in d2 %}
{% for k,v in d1.items %}
<li>{{ forloop.counter }}-- {{ forloop.parentloop.counter }} === {{ k }} -- {{ v }}</li>
{% endfor %}
{% endfor %}
if判断标签
{% if num > 100 or num < 0 %}
<p>无效</p> <!--不满足条件,不会生成这个标签-->
{% elif num > 80 and num < 100 %}
<p>优秀</p>
{% else %} <!--也是在if标签结构里面的-->
<p>凑活吧</p>
{% endif %}
if语句支持 and 、or、==、>、<、!=、<=、>=、in、not in、is、is not判断,注意条件两边都有空格。
with
方法1
{% with total=business.employees.count %} #注意等号两边不能有空格
{{ total }} <!--只能在with语句体内用-->
{% endwith %}
方法2
{% with business.employees.count as total %}
{{ total }}
{% endwith %}
模板相关
模板继承(母版继承)
1. 创建一个xx.html页面(作为母版,其他页面来继承它使用)
2. 在母版中定义block块(可以定义多个,整个页面任意位置)
{% block content %} <!-- 预留的钩子,共其他需要继承它的html,自定义自己的内容 -->
{% endblock %}
3 其他页面继承写法
{% extends 'base.html' %} 必须放在页面开头
4 页面中写和母版中名字相同的block块,从而来显示自定义的内容
{% block content %} <!-- 预留的钩子,共其他需要继承它的html,自定义自己的内容 -->
{{ block.super }} #这是显示继承的母版中的content这个快中的内容
这是xx1
{% endblock %}
组件
1 创建html页面,里面写上自己封装的组件内容,xx.html
2 新的html页面使用这个组件
{% include 'xx.html' %}
自定义标签和过滤器
1 在应用下创建一个叫做templatetags的文件夹(名称不能改),在里面创建一个py文件,例如xx.py
2 在xx.py文件中引用django提供的template类,写法
from django import template
register = template.Library() #register变量名称不能改
定义过滤器
@register.filter 参数至多两个
def xx(v1,v2):
return xxx
使用:
{% load xx %}
{% name|xx:'oo' %}
# 自定义标签 没有参数个数限制
@register.simple_tag
def huxtag(n1,n2): #冯强xx '牛欢喜'
'''
:param n1: 变量的值 管道前面的
:param n2: 传的参数 管道后面的,如果不需要传参,就不要添加这个参数
:return:
'''
return n1+n2
# inclusion_tag 返回html片段的标签
@register.inclusion_tag('result.html')
def res(n1): #n1 : ['aa','bb','cc']
return {'li':n1 }
使用:
{% res a %}
静态文件配置
1 项目目录下创建一个文件夹,例如名为jingtaiwenjianjia,将所有静态文件放到这个文件夹中
2 settings配置文件中进行下面的配置
# 静态文件相关配置
STATIC_URL = '/abc/' #静态文件路径别名
STATICFILES_DIRS = [
os.path.join(BASE_DIR, 'jingtaiwenjianjia'),
]
3 引入<link rel="stylesheet" href="/abc/css/index.css">
url别名和反向解析
写法
url(r'^index2/', views.index,name='index'),
反向解析
后端: from django.urls import reverse
reverse('别名') 例如:reverse('index') -- /index2/
html: {% url '别名' %} -- 例如:{% url 'index' %} -- /index2/
url命名空间
路由分发 include
1 在每个app下创建urls.py文件,写上自己app的路径
2 在项目目录下的urls.py文件中做一下路径分发,看下面内容
from django.conf.urls import url,include
from django.contrib import admin
urlpatterns = [
# url(r'^admin/', admin.site.urls),
url(r'^app01/', include('app01.urls')),#app01/home/
url(r'^app02/', include('app02.urls')),
]
命名空间namespace
from django.conf.urls import url,include
from django.contrib import admin
urlpatterns = [
# url(r'^admin/', admin.site.urls),
url(r'^app01/', include('app01.urls',namespace='app01')),#app01/home/
url(r'^app02/', include('app02.urls',namespace='app02')),
]
使用:
后端:reverse('命名空间名称:别名') -- reverse('app01:home')
hmtl:{% url '命名空间名称:别名' %} -- {% url 'app01:home' %}
orm单表操作 对象关系映射(object relational mapping)
orm语句 -- sql -- 调用pymysql客户端发送sql -- mysql服务端接收到指令并执行
orm介绍
django 连接mysql
1 settings配置文件中
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'orm02',
'USER':'root',
'PASSWORD':'666',
'HOST':'127.0.0.1',
'PORT':3306,
}
}
2 项目文件夹下的init文件中写上下面内容,用pymysql替换mysqldb
import pymysql
pymysql.install_as_MySQLdb()
3 models文件中创建一个类
# class UserInfo(models.Model):
# id = models.AutoField(primary_key=True)
# name = models.CharField(max_length=10)
# bday = models.DateField()
# checked = models.BooleanField()
4 执行数据库同步指令,添加字段的时候别忘了,该字段不能为空,所有要么给默认值,要么设置它允许为空 null=True
# python manage.py makemigrations
# python manage.py migrate
5 创建记录(实例一个对象,调用save方法)
def query(request):
# 创建一条记录,增
new_obj = models.UserInfo(
id=2,
name='子文',
bday='2019-09-27',
checked=1,
)
new_obj.save() #翻译成sql语句,然后调用pymysql,发送给服务端 insert into app01_userinfo values(2,'子文','2019-09-27',1)
return HttpResponse('xxx')
增:
方式1:
new_obj = models.UserInfo(
id=2,
name='子文',
bday='2019-09-27',
checked=1,
)
new_obj.save()
方式2:
# ret 是创建的新的记录的model对象(重点)
ret = models.UserInfo.objects.create(
name='卫贺',
bday='2019-08-07',
checked=0
)
print(ret) #UserInfo object 卫贺
print(ret.name) #UserInfo object
print(ret.bday) #UserInfo object
时间问题
models.UserInfo.objects.create(
name='杨泽涛2',
bday=current_date,
# now=current_date, 直接插入时间没有时区问题
checked=0
)
但是如果让这个字段自动来插入时间,就会有时区的问题,auto_now_add创建记录时自动添加当前创建记录时的时间,存在时区问题
now = models.DateTimeField(auto_now_add=True,null=True)
解决方法:
settings配置文件中将USE_TZ的值改为False
# USE_TZ = True
USE_TZ = False # 告诉mysql存储时间时按照当地时间来寸,不要用utc时间
使用pycharm的数据库客户端的时候,时区问题要注意
删
简单查询:filter() -- 结果是queryset类型的数据里面是一个个的model对象,类似于列表
models.UserInfo.objects.filter(id=7).delete() #queryset对象调用
models.UserInfo.objects.filter(id=7)[0].delete() #model对象调用
改
方式1:update
# models.UserInfo.objects.filter(id=2).update(
# name='篮子文',
# checked = 0,
#
# )
# 错误示例,model对象不能调用update方法
# models.UserInfo.objects.filter(id=2)[0].update(
# name='加篮子+2',
# # checked = 0,
# )
方式2
ret = models.UserInfo.objects.filter(id=2)[0]
ret.name = '加篮子+2'
ret.checked = 1
ret.save()
更新时的auto_now参数
# 更新记录时,自动更新时间,创建新纪录时也会帮你自动添加创建时的时间,但是在更新时只有使用save方法的方式2的形式更新才能自动更新时间,有缺陷,放弃
now2 = models.DateTimeField(auto_now=True,null=True)
批量插入
obj_list = []
for i in range(10):
obj = models.Book(
title='xx'
)
obj_list.append(obj)
models.Book.objects.bulk_create(obj_list)
查询
all() queryset
filter(id=1,name='xx') and queryset
get() model对象
count()
first()
last()
exclude() exclude(id=1)
exists() False True
order_by('id','-price')
reverse() 反转,先排序
values() -- queryset([{},{}])
values_list() queryset([(),()])
distinct()
filter 双下划线查询
filter(price__gt=30)
filter(price__gte=30)
filter(price__lt=30)
filter(price__lte=30)
filter(price__range=[30,40])
filter(price__in=[30,40,50..])
filter(title_contains='py')
filter(title_icontains='py')
filter(title_istartswith='py')
filter(title_iendswith='py')
filter(pub_date__year__gt='2018',pub_date__month='09',pub_date__day='09')
多表建立表关系
OneToOneField('表名',to_field='字段名',on_delete=CASCADE)
ForeignKey('表名',to_field='字段名',on_delete=CASCADE)
ManyToManyField('表名')
增删改查
增加
# 增加
# 一对一
# au_obj = models.AuthorDetail.objects.get(id=4)
models.Author.objects.create(
name='海狗',
age=59,
# 两种方式
au_id=4
# au=au_obj
)
# 一对多
# pub_obj = models.Publish.objects.get(id=3)
#
# models.Book.objects.create(
# title='xx2',
# price=13,
#
# publishDate='2011-11-12',
# # publishs=pub_obj , #类属性作为关键字时,值为model对象
# publishs_id=3 # 如果关键字为数据库字段名称,那么值为关联数据的值
# )
# 多对多 -- 多对多关系表记录的增加
# ziwen = models.Author.objects.get(id=3)
# haigou = models.Author.objects.get(id=5)
new_obj = models.Book.objects.create(
title='海狗产后护理第二部',
price=0.5,
publishDate='2019-09-29',
publishs_id=2,
)
new_obj.authors.add(3,5) # #*args **kwargs
new_obj.authors.add(*[3,5]) # 用的最多,
new_obj.authors.add(ziwen, haigou)
删除
# 删除
# 一对一
# models.AuthorDetail.objects.filter(id=3).delete()
# models.Author.objects.filter(id=3).delete()
# 一对多
# models.Publish.objects.filter(id=3).delete()
# models.Book.objects.filter(id=4).delete()
# 多对多
book_obj = models.Book.objects.get(id=2)
# book_obj.authors.add() # 添加
# book_obj.authors.remove(1) #删除
# book_obj.authors.clear() # 清除
# book_obj.authors.set(['1','5']) # 先清除再添加,相当于修改
改
# 改
# ret = models.Publish.objects.get(id=2)
# models.Book.objects.filter(id=5).update(
# # title='华丽丽',
# publishs=ret,
# # publishs_id=1,
# )
基于对象的跨表查询
# 查询
# 一对一
# 关系属性写在表1,关联到表2,那么通过表1的数据去找表2的数据,叫做正向查询,返过来就是反向查询
# 查询一下王洋的电话号码
# 正向查询 对象.属性
# obj = models.Author.objects.filter(name='王洋').first()
# ph = obj.au.telephone
# print(ph)
# 查一下电话号码为120的作者姓名
# 反向查询 对象.小写的表名
# obj = models.AuthorDetail.objects.filter(telephone=120).first()
# ret = obj.author.name #陈硕
# print(ret)
# 一对多
# 查询一下 海狗的怂逼人生这本书是哪个出版社出版的 正向查询
# obj = models.Book.objects.filter(title='海狗的怂逼人生').first()
# ret = obj.publishs.name
# print(ret) #24期出版社
# 查询一下 24期出版社出版过哪些书
# obj = models.Publish.objects.filter(name='24期出版社').first()
#
# ret = obj.book_set.all() #<QuerySet [<Book: 母猪的产后护理>, <Book: 海狗的怂逼人生>]>
# for i in ret:
# print(i.title)
# 多对多
# 海狗的怂逼人生 是哪些作者写的 -- 正向查询
# obj = models.Book.objects.filter(title='海狗的怂逼人生').first()
# ret = obj.authors.all()
#
# print(ret) #<QuerySet [<Author: 王洋>, <Author: 海狗>]>
# for i in ret:
# print(i.name)
# 查询一下海狗写了哪些书 -- 反向查询
# obj = models.Author.objects.filter(name='海狗').first()
# ret = obj.book_set.all()
# print(ret)
# for i in ret:
# print(i.publishs.name)
# print(i.title)
# return HttpResponse('ok')
admin添加用户
python manage.py createsuperuser
输入用户名:wuchao
邮箱不用输 直接回车
输入密码:必须超过8位,并且别太简单
admin注册
from django.contrib import admin
# Register your models here.
from app01 import models
admin.site.register(models.Author)
admin.site.register(models.AuthorDetail)
admin.site.register(models.Publish)
admin.site.register(models.Book)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号