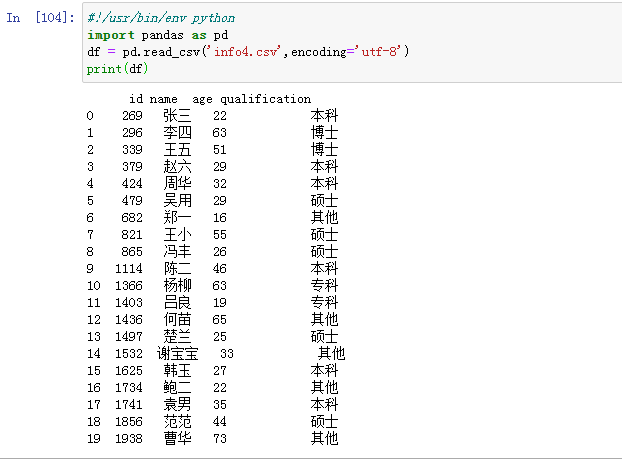
df.info()
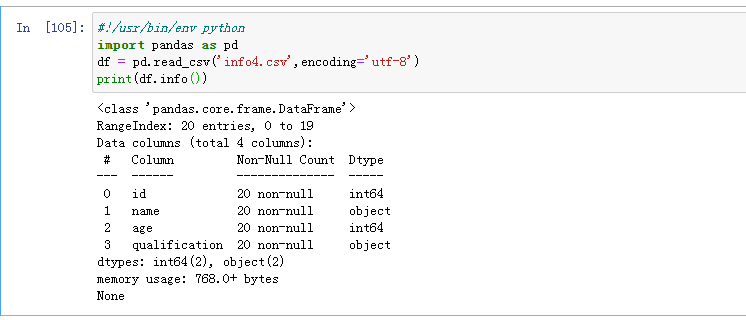
行索引:直接返回前多少行的数据,下面示例返回前三行的数据

列索引:取字段名称,返回该列的所有值
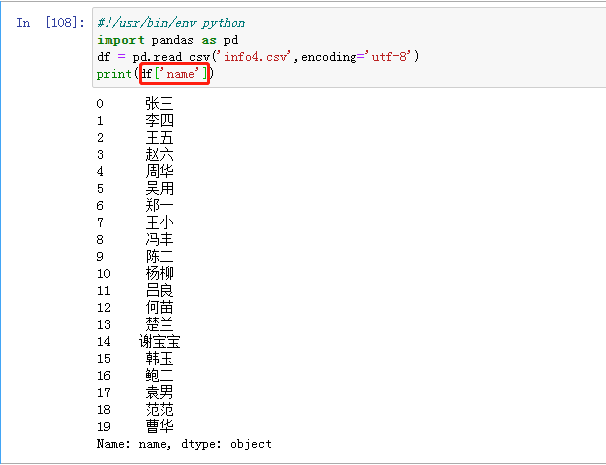
loc取指定行指定列的数据:返回指定的index的行,指定列为age的数据,这里的0:2指的是索引,所以这里一共有三行。
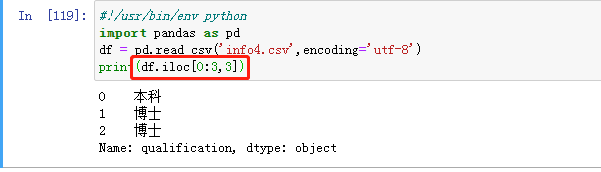
iloc取指定列指定行的数据:这里的iloc前面的0:3指的是前三行,后面的3代表第三个字段(index)的值
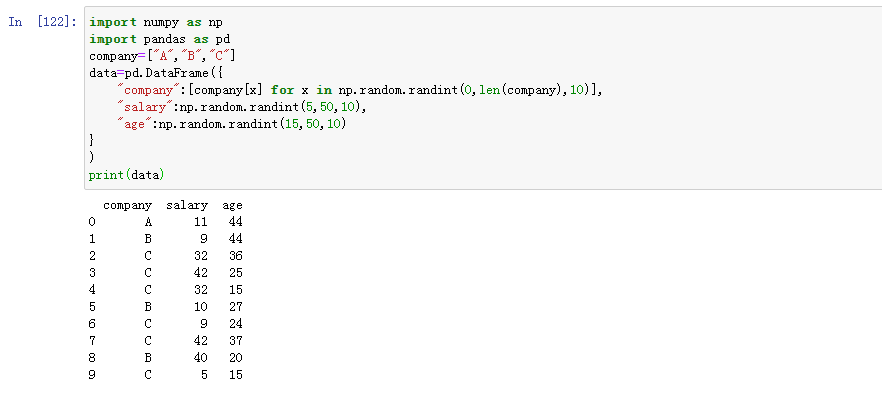
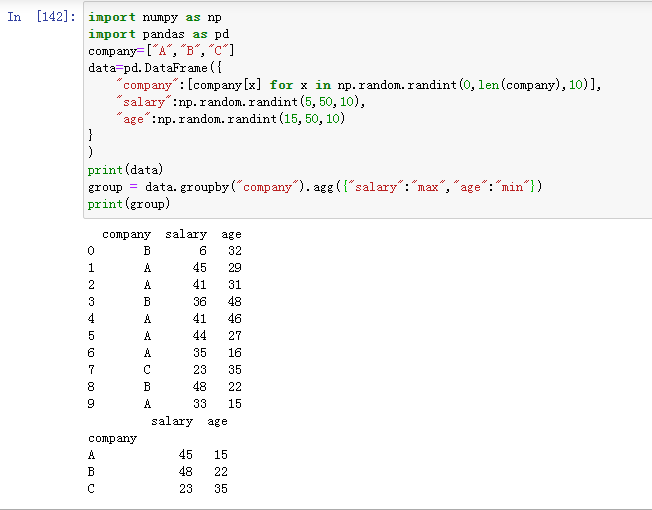
随机产生一些数据:
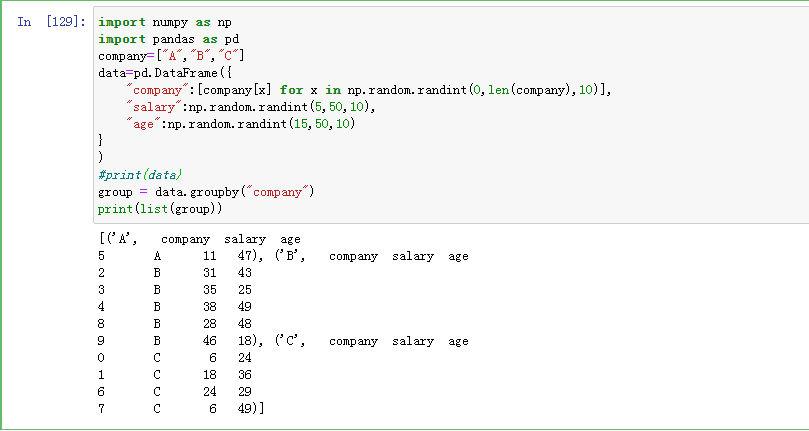
使用groupby来分组
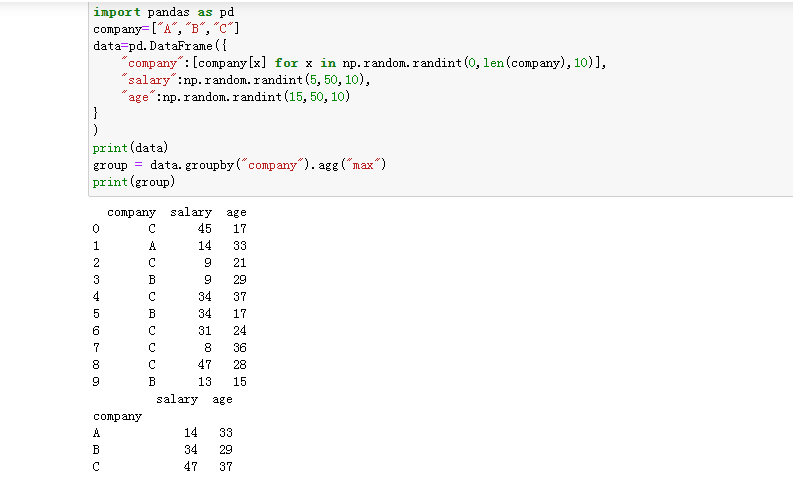
使用聚合函数:以company为分组,查看每个分组中salary和age分别最大的数值
如果想针对不同的字段,取不同的值,譬如salary取最大,age取最小,那么可以按照如下的写法来表达:
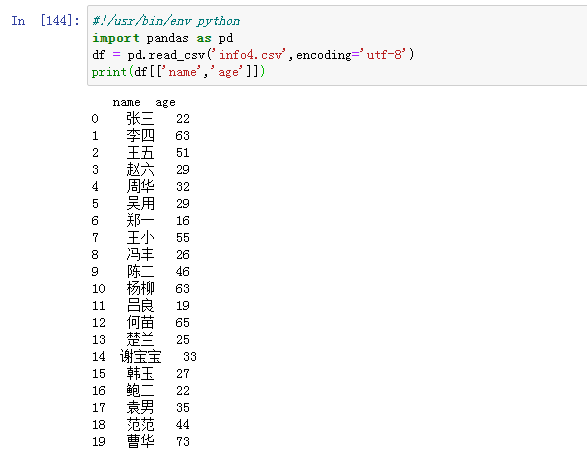
输出指定的列:
输出学历为本科的:


按数据进行分组:
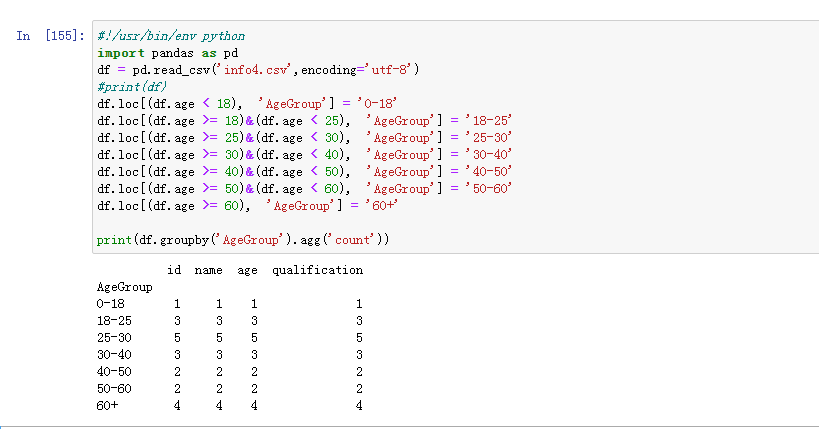
#!/usr/bin/env python
import pandas as pd
def count(df):
df.loc[(df.age < 18), 'AgeGroup'] = '0-18'
df.loc[(df.age >= 18)&(df.age < 25), 'AgeGroup'] = '18-25'
df.loc[(df.age >= 25)&(df.age < 30), 'AgeGroup'] = '25-30'
df.loc[(df.age >= 30)&(df.age < 40), 'AgeGroup'] = '30-40'
df.loc[(df.age >= 40)&(df.age < 50), 'AgeGroup'] = '40-50'
df.loc[(df.age >= 50)&(df.age < 60), 'AgeGroup'] = '50-60'
df.loc[(df.age >= 60), 'AgeGroup'] = '60+'
return df
df = pd.read_csv('info4.csv',encoding='utf-8')
df1=count(df)
print(df1.groupby('AgeGroup').agg('count'))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号