
你要偷偷的学Python,然后惊呆所有人(第十一天)
标题无意冒犯,就是觉得这个广告挺好玩的
文章目录
- 前言
- 欢迎来到我们的圈子
- 绕过登录验证的小饼干:cookies and session
- 声明
- 什么是cookies?什么是session?
- 是如何实现“记住我的登录状态”的功能
- post请求
- 实操第一步
- 锋回路转
- 把小饼干装进饼干盒
- 自动化实现:selenium
- 先展示一下
- 代码展示
- 环境配置
- selenium简单讲解
- 设置浏览器引擎
- selenium能干嘛?
- 为什么selenium这么能干?

前言
前期回顾:你要偷偷学Python(第十天)
上一篇呢,上一篇不是很好,我自己有数。所以,这一篇我准备了不少有意思的东西(坏笑),嘿嘿,快来跟我动手操作。
我行,你也行!!!

插播一条推送:(如果是小白的话,可以看一下下面这一段)
欢迎来到我们的圈子
我建了一个Python学习答疑群,有兴趣的朋友可以了解一下:如果大家在学习中遇到困难,想找一个python学习交流环境,可以加入我们的python圈,裙号947618024,可领取python学习资料,会节约很多时间,减少很多遇到的难题。
本系列文默认各位有一定的C或C++基础,因为我是学了点C++的皮毛之后入手的Python。
本系列文默认各位会百度,学习‘模块’这个模块的话,还是建议大家有自己的编辑器和编译器的,上一篇已经给大家做了推荐啦?
然后呢,本系列的目录嘛,说实话我个人比较倾向于那两本 Primer Plus,所以就跟着它们的目录结构吧。
本系列也会着重培养各位的自主动手能力,毕竟我不可能把所有知识点都给你讲到,所以自己解决需求的能力就尤为重要,所以我在文中埋得坑请不要把它们看成坑,那是我留给你们的锻炼机会,请各显神通,自行解决。
1234567绕过登录验证的小饼干:cookies and session
声明
看到这个标题,激动不?难道,今天咱也能去盗号了吗?嘿嘿,准备好黑头套。
喂喂喂,醒醒,醒醒,哈喇子都流出来了。咱可是遵纪守法好公民,怎么去干这种事情?
我只会教你,怎么在人家点击了“记住账号密码”的情况下,你给它绕过登录验证。至于你要怎么拿到这个条件,那跟我没关系啊,特此声明哈哈哈。
看了我前两天发的那篇“自己爬自己的照片”的博客的朋友不知道对这个流程是否还有印象,是否还有疑虑啊,这么麻烦的操作,处处体现着人的干预,机器怎么搞?你不登录,你不保存,你不去找网址,怎么拿到cookies嘛。
能问出这种问题的小伙伴(真的有)啊,我只能说你脑子挺活络的,但是不要跑偏了,上面你这几个问题,都是有技术手段可以解决的,但是我们让爬虫能够登录自己的账号,就干不了很多事情吗?工具在你手上。
什么是cookies?什么是session?
cookie: 在网站中,http请求是无状态的,也就是说,即使第一次和服务器连接后并且登录成功后,第二次请求服务器依然不能知道当前请求是哪个用户。cookie的出现就是为了解决这个问题:当浏览器访问网站后,这些网站将一组数据存放在客户端,当该用户发送第二次请求的时候,就会自动的把上次请求存储的cookie数据自动携带给服务器,服务器通过浏览器携带的数据就能识别当前用户。
一般为网页存在本地的一些数据,用来下次访问时回传验证,常用于登陆验证,记住状态
session: Session是存放在服务器端的类似于HashTable的结构来存放用户 数据,当浏览器第一次发送请求时,服务器自动生成了一个HashTable和一个Session ID用来唯一标识这个HashTable,并将其通过响应发送到浏览器。当浏览器第二次发送请求,会将前一次服务器响应中的Session ID放在请求中一并发送到服务器上,服务器从请求中提取出Session ID,并和保存的所有Session ID进行对比,找到这个用户对应的HashTable。
类似于客户机本地的cookie,session为服务器的’cookie’,可以实现一样的功能,往往还可以一同交互验证登陆,记住状态
是如何实现“记住我的登录状态”的功能
所以我们可以知道,如果将Session ID通过Cookie发送到客户端的时候设置其有效时间为1年,那么在今后的一年时间内,客户端访问我的网站的时候都回将这个Session ID值发送到服务器上,服务器根据这个Session ID从内存或者数据库里面恢复存放Key-Value对的HashTable。
但是,服务器上的Session其实不会保存。过了一定的时间之后,服务器上的Session就会被销毁,以减轻服务器的访问压力。当服务器上的数据被销毁后,即使客户端上存放了cookie也没有办法“记住我的登录状态”了。
所以,本文方法只是短期验证cookie跳过登陆验证访问之用,本地的cookie失效时间主要和服务器上session设置的时间有关。
post请求
什么是post请求?如果你没听说过post请求,那么就想一下get请求吧。
其实,post和get都可以带着参数请求,不过get请求的参数会在url上显示出来。
但post请求的参数就不会直接显示,而是隐藏起来。像账号密码这种私密的信息,就应该用post的请求。
通常,get请求会应用于获取网页数据,比如我们之前学的requests.get()。post请求则应用于向网页提交数据,比如提交表单类型数据(像账号密码就是网页表单的数据)。
实操第一步
打开CSDN的登录页面,填上你的个人信息:https://passport.csdn.net/login?code=public
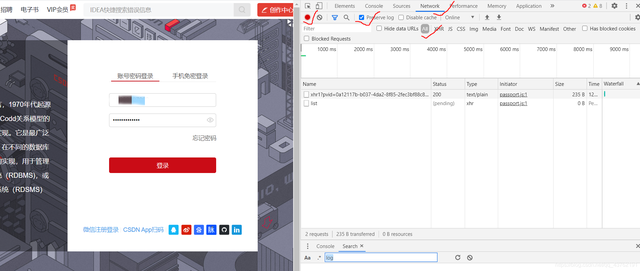
该勾的勾,该选的选,然后点击登录。
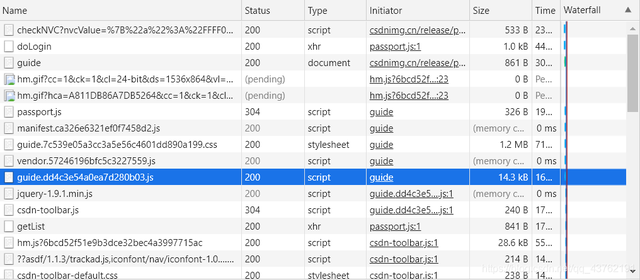
你猜是哪个包啊,耍点小聪明啊,你看你登录成功之后,右边还在不断的加载包,那就可以判定登录包肯定在前边。
点击登录之后,信号一传送,第一步肯定是登录,所以就前几个包看一下,一眼就看到了那个“doLogin”吧,点开。
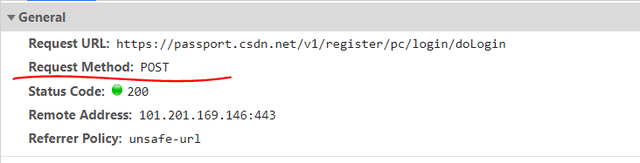
看到没,post、
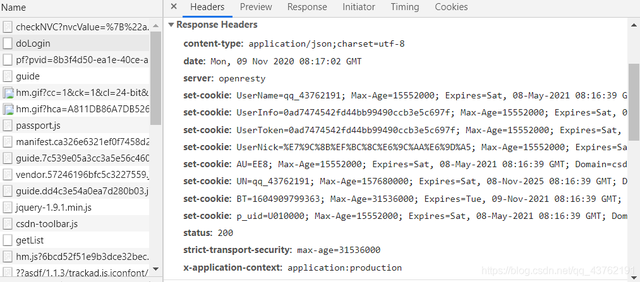
内啥,看到一大串的set-cookies了吗?没别的意思,我就提一下哈哈哈哈哈哈。
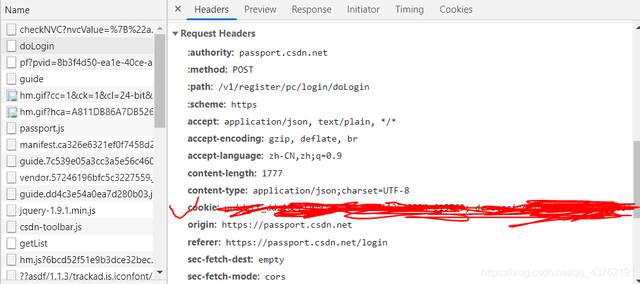
呐,我给你画出来了。
上面我提那一下啊,其实我是想说,都打开,不同网站不一样,指不定在哪个小角落里发现了你的小饼干呢。
其实不止小饼干啊,账号密码都有:
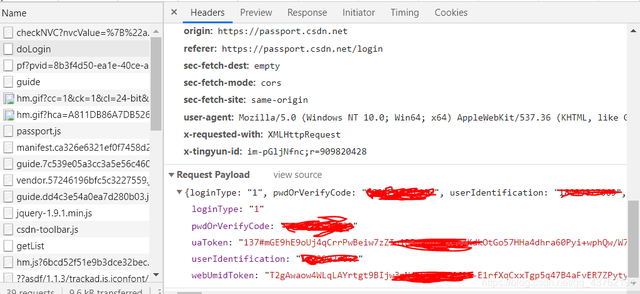
我们来试试另一种登录方式,带参登录。
import requests
#引入requests。
url = 'https://www.csdn.net/'
#把请求登录的网址赋值给url。
headers = {
'origin':'https://passport.csdn.net',
# 请求来源,本案例中其实是不需要加这个参数的,只是为了演示
'referer':'https://passport.csdn.net/login',
'User-Agent':'省略'
}
#加请求头,前面有说过加请求头是为了模拟浏览器正常的访问,避免被反爬虫。
data = {
"loginType": "1",
"pwdOrVerifyCode": "密码",
"userIdentification":"账号"
}
#把有关登录的参数封装成字典,赋值给data。
login_in = requests.post(url,headers=headers,data=data)
print(login_in)
123456789101112131415161718192021好的,返回值403,草率了。。
没事了,没事了。
锋回路转
哦,我又不断地尝试了,终于成功的登录上了:
import requests
from bs4 import BeautifulSoup
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36',
'Connection': 'keep-alive',
'accept': 'application/json, text/plain, */*',
#'Cookie': cookie,
'referer': “我的博客”页面网址
}
url = 上面那个referer
data = {
"loginType": "1",
"pwdOrVerifyCode": 你的,
"userIdentification":你的
}
#把有关登录的参数封装成字典,赋值给data。
login_in = requests.post(url,headers=header,data=data)
print(login_in)
1234567891011121314151617181920212223好极,这次返回值是200了。
接下来干嘛?接下来找一篇博客评论一下这事儿就算过去了。
cookies = login_in.cookies
#提取cookies的方法:调用requests对象(login_in)的cookies属性获得登录的cookies,并赋值给变量cookies。
url_1 = 自己找
#我们想要评论的文章网址。
data_1 = {
'content': 'test',
'articleId':个人填
}
#把有关评论的参数封装成字典。
comment = requests.post(url_1,headers=header,data=data_1,cookies=cookies)
#用requests.post发起发表评论的请求,放入参数:文章网址、headers、评论参数、cookies参数,赋值给comment。
#调用cookies的方法就是在post请求中传入cookies=cookies的参数。
print(comment.status_code)
#打印出comment的状态码,若状态码等于200,则证明我们评论成功。
123456789101112131415以状态码为准,有时候慢起来要等一天你才能看得到。
如果真等了一天还评论不上去,没事,我跟你说,那应该是被后台给切了。
没事,我们后面还会有更好的办法。
把小饼干装进饼干盒
算了,为了看着直观,我还是把之前那段爬学生证的代码节选一下吧。
import requests
from bs4 import BeautifulSoup
cookie = '''*此处粘贴从chrome中复制的cookie信息*'''
header = {
'User-Agent': '放你自己的',
'Connection': 'keep-alive',
'accept': '放你自己的',
'Cookie': cookie,
'referer': '放你自己的博客主页地址'
}
url = 'https://blog.csdn.net/python_miao?spm=1010.2135.3001.5113' # csdn 个人中心中,加载名字的js地址
seesion = requests.session()
response = seesion.get(url,headers=header)
print(type(session.cookies))
#打印cookies的类型,session.cookies就是登录的cookies
123456789101112131415好极,可以看到结果是:<class ‘requests.cookies.RequestsCookieJar’>
这玩意儿怕是不能存到文本里面吧,谁去试一下看看。
不过仔细观察一下吧,这个cookies有没有长得挺像一个字典型字符串啊

自己动手啊,我就说要一句:其实不用转字符串也可以试一下,不行了再转也不迟。
当然了,还有其他的方式获取到cookies,不过我这套方法是最直接的了。
自动化实现:selenium
现在的网站啊,也都不是傻子,哪个登录不要你验证码的?极少数吧。
那这验证码不就得你手动去输入了,当然,也有人说什么机器学习啊,破解验证码啊,想法不错,动手试试嘛。
还有的网站啊,想必你也碰到过吧,阡陌交通,错综复杂的,爬个球啊爬。
就更不要说那些URL加密了啊,或者直接禁止爬虫的网站了。
好,接下来我们就来看看这项即将要接触的新技术:selenium能够帮助我们闯过多少障碍。
先展示一下
粗略展示一下,打开浏览器,打开一篇博客,然后关掉,至于其他高端操作,我们后面通过代码来展示:
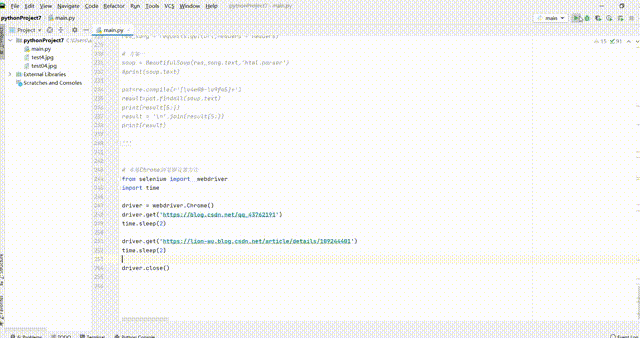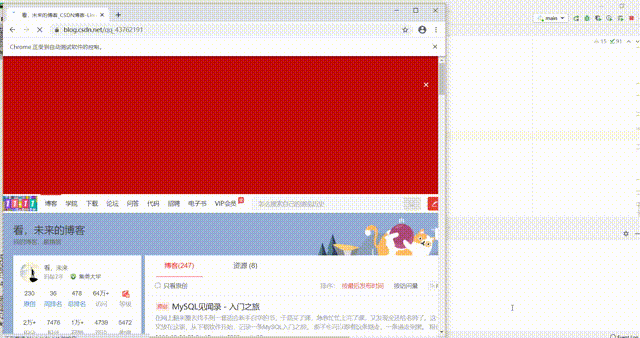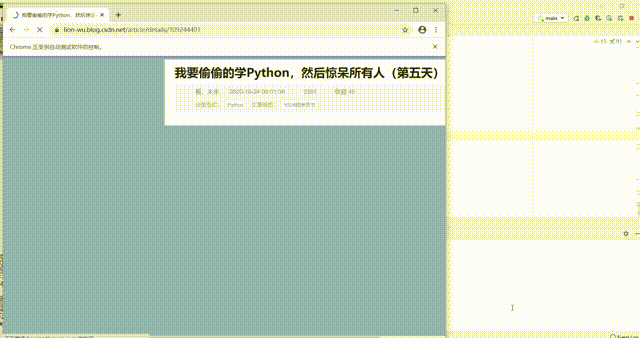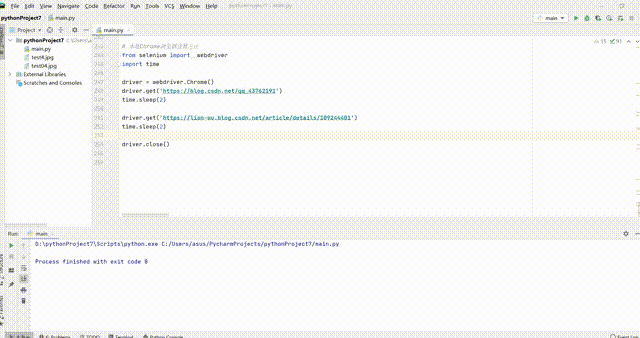
代码展示
# 本地Chrome浏览器设置方法
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get('https://mp.toutiao.com/profile_v4/graphic/articles')
time.sleep(2)
driver.get('https://www.toutiao.com/i6887003700720566795/')
time.sleep(2)
driver.close()
1234567891011121314代码给你们,你们拿去试试看,多半是运行不起来的,因为你们多半没有配置环境。
环境配置
好,没环境都不用着急,一切都会如期而至的嘛。
首先,你需要一个谷歌浏览器,一直在说,应该没有小伙伴还没下载吧。
其次,你需要看一下你的谷歌浏览器的版本,这个很重要,因为一代版本对应的是一代驱动,匹配不上的话问题就会有点麻烦了。
接下来,我们来下载一个驱动:http://npm.taobao.org/mirrors/chromedriver/
版本自己挑啊。
下载完之后,解压,把这个驱动放到Python安装的同级目录下,如果不知道是哪个,那就下载了有多少个Python安装嫌疑目录就放多少个呗。
好,再打开pycharm,运行前面的代码。
哦,对了,你还要下载一个selenium的包,还有点大。
今天不讲太多的操作,就开个头,字数也八千多了,把好玩的东西都留到下一篇嘛。
那接下来来讲一下上面那几行代码,开个好头,我知道,可能会有小伙伴接着就自己去查了啊。
selenium简单讲解
设置浏览器引擎
#第一步,导入模块,不过多赘述
from selenium import webdriver
import time
driver = webdriver.Chrome() #获取对谷歌浏览器的控制权,这里如果没有驱动的话是会直接报错的
driver.get('') #命令谷歌浏览器:嘿,小样儿,给我打开这个网页
time.sleep(2) #主要是因为浏览器慢了点,还是说网络慢了点,反正就是有延迟,你等两秒呗。
driver.get('https://lion-wu.blog.csdn.net/article/details/109244401') #再开一个
time.sleep(2) #同上
driver.close() #行了,玩到这里,关了
123456789101112selenium能干嘛?
我就这么说吧,上面这一段,把Chrome浏览器设置为引擎,然后赋值给变量driver。driver是实例化的浏览器,在后面你会总是能看到它的影子,这也可以理解,因为我们要控制这个实例化的浏览器为我们做一些事情。
你懂得。
为什么selenium这么能干?
selenium能把我们前面遇到的问题简化,爬动态网页如爬静态网页一样简单。
刚开始我们直接用BeautifulSoup就能处理掉的那种网页,就是静态网页。我们使用BeautifulSoup爬取这类型网页,因为网页源代码中就包含着网页的所有信息,因此,网页地址栏的URL就是网页源代码的URL。
后来,我们开始接触更复杂的网页,我要是没有记错的话,咱是从抓取CSDN的评论开始的吧,那时候我们开始接触到了json。
还有后面的QQ音乐,要爬取的数据不在HTML源代码中,而是在json中,你就不能直接使用网址栏的URL了,而需要找到json数据的真实URL。这就是一种动态网页。
不论数据存在哪里,浏览器总是在向服务器发起各式各样的请求,当这些请求完成后,它们会一起组成开发者工具的Elements中所展示的,渲染完成的网页源代码。
在遇到页面交互复杂或是URL加密逻辑复杂的情况时,selenium就派上了用场,它可以真实地打开一个浏览器,等待所有数据都加载到Elements中之后,再把这个网页当做静态网页爬取就好了。
说了这么多优点,使用selenium时,当然也有美中不足之处。
由于要真实地运行本地浏览器,打开浏览器以及等待网渲染完成需要一些时间,selenium的工作不可避免地牺牲了速度和更多资源,不过,至少不会比人慢。所以上面让你等着,年轻人嘛,宁停三分钟,不抢一秒钟嘛。
就到这里啊,留点悬念嘛。

最后多说一句,想学习Python可联系小编,这里有我自己整理的整套python学习资料和路线,想要这些资料的都可以进q裙947618024领取。
本文章素材来源于网络,如有侵权请联系删除。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号