
day-9 sklearn库和python自带库实现最近邻KNN算法
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。谁和我隔得近,我就跟谁是一类,有点中国古语说的近墨者黑近朱者赤意思。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 KNN方法虽然从原理上也依赖于极限定理,但在类别决策时,只与极少量的相邻样本有关。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
优点:
- 简单,易于理解,易于实现,无需估计参数,无需训练;
- 适合对稀有事件进行分类;
- 特别适合于多分类问题(multi-modal,对象具有多个类别标签), kNN比SVM的表现要好。
缺点:
- 该算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。 该算法只计算“最近的”邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎样,数量并不能影响运行结果。
- 该方法的另一个不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。
- 可理解性差,无法给出像决策树那样的规则。
kNN算法因其提出时间较早,随着其他技术的不断更新和完善,kNN算法的诸多不足之处也逐渐显露,因此许多kNN算法的改进算法也应运而生。
针对以上算法的不足,算法的改进方向主要分成了分类效率和分类效果两方面。
分类效率:事先对样本属性进行约简,删除对分类结果影响较小的属性,快速的得出待分类样本的类别。该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。
分类效果:采用权值的方法(和该样本距离小的邻居权值大)来改进,Han等人于2002年尝试利用贪心法,针对文件分类实做可调整权重的k最近邻居法WAkNN (weighted adjusted k nearest neighbor),以促进分类效果;而Li等人于2004年提出由于不同分类的文件本身有数量上有差异,因此也应该依照训练集合中各种分类的文件数量,选取不同数目的最近邻居,来参与分类。
同样,sklearn也为我们提供了一个算法接口,如下是代码示例:
from sklearn import neighbors from sklearn import datasets knn = neighbors.KNeighborsClassifier() iris = datasets.load_iris() knn.fit(iris.data,iris.target) predictedLabel = knn.predict([[0.1,0.2,0.3,0.4]]) print(predictedLabel)
通过调用datasets.load_iris()接口,我们可以获取一个150个实例的训练数据集,记录萼片长度,萼片宽度,花瓣长度,花瓣宽度(sepal length, sepal width, petal length and petal width),对应Iris setosa, Iris versicolor, Iris virginica类别。调用knn.predict([[0.1,0.2,0.3,0.4]])接口时,内部会将该测试数据与所有一直数据求欧几里得举例,然后取K个最近点,算得最后的类别。
如下是执行结果:
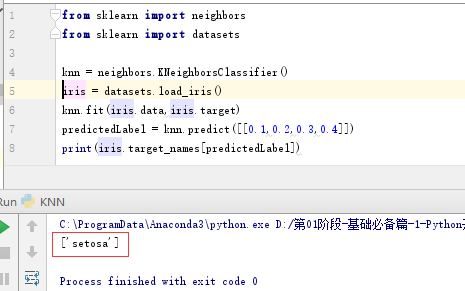
在此基础上,我们利用python自带库,实现了该算法,训练和测试数据集如下:


5.1,3.5,1.4,0.2,Iris-setosa 4.9,3.0,1.4,0.2,Iris-setosa 4.7,3.2,1.3,0.2,Iris-setosa 4.6,3.1,1.5,0.2,Iris-setosa 5.0,3.6,1.4,0.2,Iris-setosa 5.4,3.9,1.7,0.4,Iris-setosa 4.6,3.4,1.4,0.3,Iris-setosa 5.0,3.4,1.5,0.2,Iris-setosa 4.4,2.9,1.4,0.2,Iris-setosa 4.9,3.1,1.5,0.1,Iris-setosa 5.4,3.7,1.5,0.2,Iris-setosa 4.8,3.4,1.6,0.2,Iris-setosa 4.8,3.0,1.4,0.1,Iris-setosa 4.3,3.0,1.1,0.1,Iris-setosa 5.8,4.0,1.2,0.2,Iris-setosa 5.7,4.4,1.5,0.4,Iris-setosa 5.4,3.9,1.3,0.4,Iris-setosa 5.1,3.5,1.4,0.3,Iris-setosa 5.7,3.8,1.7,0.3,Iris-setosa 5.1,3.8,1.5,0.3,Iris-setosa 5.4,3.4,1.7,0.2,Iris-setosa 5.1,3.7,1.5,0.4,Iris-setosa 4.6,3.6,1.0,0.2,Iris-setosa 5.1,3.3,1.7,0.5,Iris-setosa 4.8,3.4,1.9,0.2,Iris-setosa 5.0,3.0,1.6,0.2,Iris-setosa 5.0,3.4,1.6,0.4,Iris-setosa 5.2,3.5,1.5,0.2,Iris-setosa 5.2,3.4,1.4,0.2,Iris-setosa 4.7,3.2,1.6,0.2,Iris-setosa 4.8,3.1,1.6,0.2,Iris-setosa 5.4,3.4,1.5,0.4,Iris-setosa 5.2,4.1,1.5,0.1,Iris-setosa 5.5,4.2,1.4,0.2,Iris-setosa 4.9,3.1,1.5,0.1,Iris-setosa 5.0,3.2,1.2,0.2,Iris-setosa 5.5,3.5,1.3,0.2,Iris-setosa 4.9,3.1,1.5,0.1,Iris-setosa 4.4,3.0,1.3,0.2,Iris-setosa 5.1,3.4,1.5,0.2,Iris-setosa 5.0,3.5,1.3,0.3,Iris-setosa 4.5,2.3,1.3,0.3,Iris-setosa 4.4,3.2,1.3,0.2,Iris-setosa 5.0,3.5,1.6,0.6,Iris-setosa 5.1,3.8,1.9,0.4,Iris-setosa 4.8,3.0,1.4,0.3,Iris-setosa 5.1,3.8,1.6,0.2,Iris-setosa 4.6,3.2,1.4,0.2,Iris-setosa 5.3,3.7,1.5,0.2,Iris-setosa 5.0,3.3,1.4,0.2,Iris-setosa 7.0,3.2,4.7,1.4,Iris-versicolor 6.4,3.2,4.5,1.5,Iris-versicolor 6.9,3.1,4.9,1.5,Iris-versicolor 5.5,2.3,4.0,1.3,Iris-versicolor 6.5,2.8,4.6,1.5,Iris-versicolor 5.7,2.8,4.5,1.3,Iris-versicolor 6.3,3.3,4.7,1.6,Iris-versicolor 4.9,2.4,3.3,1.0,Iris-versicolor 6.6,2.9,4.6,1.3,Iris-versicolor 5.2,2.7,3.9,1.4,Iris-versicolor 5.0,2.0,3.5,1.0,Iris-versicolor 5.9,3.0,4.2,1.5,Iris-versicolor 6.0,2.2,4.0,1.0,Iris-versicolor 6.1,2.9,4.7,1.4,Iris-versicolor 5.6,2.9,3.6,1.3,Iris-versicolor 6.7,3.1,4.4,1.4,Iris-versicolor 5.6,3.0,4.5,1.5,Iris-versicolor 5.8,2.7,4.1,1.0,Iris-versicolor 6.2,2.2,4.5,1.5,Iris-versicolor 5.6,2.5,3.9,1.1,Iris-versicolor 5.9,3.2,4.8,1.8,Iris-versicolor 6.1,2.8,4.0,1.3,Iris-versicolor 6.3,2.5,4.9,1.5,Iris-versicolor 6.1,2.8,4.7,1.2,Iris-versicolor 6.4,2.9,4.3,1.3,Iris-versicolor 6.6,3.0,4.4,1.4,Iris-versicolor 6.8,2.8,4.8,1.4,Iris-versicolor 6.7,3.0,5.0,1.7,Iris-versicolor 6.0,2.9,4.5,1.5,Iris-versicolor 5.7,2.6,3.5,1.0,Iris-versicolor 5.5,2.4,3.8,1.1,Iris-versicolor 5.5,2.4,3.7,1.0,Iris-versicolor 5.8,2.7,3.9,1.2,Iris-versicolor 6.0,2.7,5.1,1.6,Iris-versicolor 5.4,3.0,4.5,1.5,Iris-versicolor 6.0,3.4,4.5,1.6,Iris-versicolor 6.7,3.1,4.7,1.5,Iris-versicolor 6.3,2.3,4.4,1.3,Iris-versicolor 5.6,3.0,4.1,1.3,Iris-versicolor 5.5,2.5,4.0,1.3,Iris-versicolor 5.5,2.6,4.4,1.2,Iris-versicolor 6.1,3.0,4.6,1.4,Iris-versicolor 5.8,2.6,4.0,1.2,Iris-versicolor 5.0,2.3,3.3,1.0,Iris-versicolor 5.6,2.7,4.2,1.3,Iris-versicolor 5.7,3.0,4.2,1.2,Iris-versicolor 5.7,2.9,4.2,1.3,Iris-versicolor 6.2,2.9,4.3,1.3,Iris-versicolor 5.1,2.5,3.0,1.1,Iris-versicolor 5.7,2.8,4.1,1.3,Iris-versicolor 6.3,3.3,6.0,2.5,Iris-virginica 5.8,2.7,5.1,1.9,Iris-virginica 7.1,3.0,5.9,2.1,Iris-virginica 6.3,2.9,5.6,1.8,Iris-virginica 6.5,3.0,5.8,2.2,Iris-virginica 7.6,3.0,6.6,2.1,Iris-virginica 4.9,2.5,4.5,1.7,Iris-virginica 7.3,2.9,6.3,1.8,Iris-virginica 6.7,2.5,5.8,1.8,Iris-virginica 7.2,3.6,6.1,2.5,Iris-virginica 6.5,3.2,5.1,2.0,Iris-virginica 6.4,2.7,5.3,1.9,Iris-virginica 6.8,3.0,5.5,2.1,Iris-virginica 5.7,2.5,5.0,2.0,Iris-virginica 5.8,2.8,5.1,2.4,Iris-virginica 6.4,3.2,5.3,2.3,Iris-virginica 6.5,3.0,5.5,1.8,Iris-virginica 7.7,3.8,6.7,2.2,Iris-virginica 7.7,2.6,6.9,2.3,Iris-virginica 6.0,2.2,5.0,1.5,Iris-virginica 6.9,3.2,5.7,2.3,Iris-virginica 5.6,2.8,4.9,2.0,Iris-virginica 7.7,2.8,6.7,2.0,Iris-virginica 6.3,2.7,4.9,1.8,Iris-virginica 6.7,3.3,5.7,2.1,Iris-virginica 7.2,3.2,6.0,1.8,Iris-virginica 6.2,2.8,4.8,1.8,Iris-virginica 6.1,3.0,4.9,1.8,Iris-virginica 6.4,2.8,5.6,2.1,Iris-virginica 7.2,3.0,5.8,1.6,Iris-virginica 7.4,2.8,6.1,1.9,Iris-virginica 7.9,3.8,6.4,2.0,Iris-virginica 6.4,2.8,5.6,2.2,Iris-virginica 6.3,2.8,5.1,1.5,Iris-virginica 6.1,2.6,5.6,1.4,Iris-virginica 7.7,3.0,6.1,2.3,Iris-virginica 6.3,3.4,5.6,2.4,Iris-virginica 6.4,3.1,5.5,1.8,Iris-virginica 6.0,3.0,4.8,1.8,Iris-virginica 6.9,3.1,5.4,2.1,Iris-virginica 6.7,3.1,5.6,2.4,Iris-virginica 6.9,3.1,5.1,2.3,Iris-virginica 5.8,2.7,5.1,1.9,Iris-virginica 6.8,3.2,5.9,2.3,Iris-virginica 6.7,3.3,5.7,2.5,Iris-virginica 6.7,3.0,5.2,2.3,Iris-virginica 6.3,2.5,5.0,1.9,Iris-virginica 6.5,3.0,5.2,2.0,Iris-virginica 6.2,3.4,5.4,2.3,Iris-virginica 5.9,3.0,5.1,1.8,Iris-virginica
主程序源码如下:
import math import operator import csv import sys __all__ = ['loadDataSet', 'calculateEuclidean', 'getNeighbors', 'getNeighborsLabel', 'getAccuracy', 'main'] # 加载数据 def loadDataSet(file_name,file_mode): ''' 从文本文件中读取数据集,返回最后的数据集结果 :param file_name: 输入文件名称 :param file_mode: 打开文件模式 :return traning_datasets: 训练数据集 test_datasets:测试数据集 ''' traning_datasets = [] test_datasets = [] with open(file_name,file_mode) as csv_file: lines = csv.reader(csv_file) try: k = 0 for row in lines: # 进行实数转换 [5.1, 3.5, 1.4, 0.2, 'Iris-setosa'] for i in range(len(row)-1): row[i] = float(row[i]) if k%2 == 0: traning_datasets.append(row) else: test_datasets.append(row) k += 1 except csv.Error as e: sys.exit('file %s, line %d: %s' % (file_name, lines.line_num, e)) return traning_datasets,test_datasets # 计算欧几里得距离 def calculateEuclidean(single_data1,single_data2): ''' 根据输入的两点,求欧几里得距离 :param single_data1: 输入点1 :param single_data2: 输入点2 :return euclidean_distance: 两点之间的欧几里得距离 ''' euclidean_distance = 0.0 if len(single_data1) != len(single_data2): return sum = 0.0 for i in range(len(single_data1)-1): sum += float(math.pow((single_data1[i] - single_data2[i]),2)) euclidean_distance = math.sqrt(sum) return euclidean_distance # 获取最近邻点 def getNeighbors(test_data_set,tranning_data_set,k): ''' 根据测试数据、训练数据集和K值,求取最近K个邻点 :param test_data_set: :param tranning_data_set: :param k: :return neighbors:训练数据集中K个最近邻点 ''' neighbors = [] results = [] for i in range(len(tranning_data_set)): euclidistance = calculateEuclidean(test_data_set,tranning_data_set[i]) results.append((tranning_data_set[i],euclidistance)) results.sort(key=operator.itemgetter(1)) for i in range(k): neighbors.append(results[i][0]) return neighbors # 获取结果 def getNeighborsLabel(neighbors): ''' 输入最近邻点,求取其所属分类 :param neighbors:K个最近邻点 :return result:判定数据所属类 ''' results = {} for row in neighbors: if row[-1] not in results.keys(): results[row[-1]] = 1 else: results[row[-1]] += 1 # 对字典进行排序 sorted_results = sorted(results.items(),key=operator.itemgetter(1),reverse=True) result = sorted_results[0][0] return result # 获取准确率 def getAccuracy(predictions): ''' 获取准确率 :param predictions:预测结果集 :return accuracy: 准确率 ''' accuracy = 0.0 sum = 0 for row in predictions: if row[1] == row[0][-1]: sum += 1 accuracy = float(sum/len(predictions))*100.0 return accuracy def main(): predictions = [] traning_datasets,test_datasets = loadDataSet(r'irisdata.txt','r') for test_data in test_datasets: neighbors = getNeighbors(test_data,traning_datasets,k=10) result = getNeighborsLabel(neighbors) predictions.append((test_data,result)) print('> predicted = ', result, ',actual = ', test_data) accuracy = getAccuracy(predictions) print('准确率为:%f%%'%(accuracy)) if __name__ == "__main__": import KNN_euklidean print(help(KNN_euklidean)) main()
在该样本集下,测试的准确率为96%,实际准确率会随样本而变化:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号