常用模块讲解
常用模块讲解
re模块补充说明
-
findall分组优先展示
findall默认是分组优先展示,正则表达式中如果有括号分组,那么在展示匹配结果的时候,默认只演示括号内正则表达式匹配到的内容。
import re
res = re.findall('asd', 'asdasdasd')
res1 = re.findall('as(d)', 'asdasdasd')
res2 = re.findall('(a)(s)(d)', 'asdasdasd')
print(res) # ['asd', 'asd', 'asd']
print(res1) # ['d', 'd', 'd']
print(res2) # [('a', 's', 'd'), ('a', 's', 'd'), ('a', 's', 'd')]
也可以取消分组优先展示的机制,就是在括号里面加问号和冒号。
res1 = re.findall('as(?:d)', 'asdasdasd')
res2 = re.findall('(a)(?:s)(?:d)', 'asdasdasd')
print(res1) # ['asd', 'asd', 'asd']
print(res2) # ['a', 'a', 'a']
-
通过索引的方式单独获取分组内匹配到的数据
res1 = re.search('asd', 'asdasdasd')
res2 = re.search('(a)s(d)', 'asdasdasd')
print(res1.group()) # asd
print(res2.group()) # asd
print(res2.group(0)) # asd
print(res2.group(1)) # a 通过索引的方式单独获取分组内匹配到的数据
print(res2.group(2)) # d 通过索引的方式单独获取分组内匹配到的数据
针对search和match,有几个分组,group括号里面的参数最大就可以填几。
-
给组起别名
res1 = re.search('(?P<aaa>a)s(?P<ddd>d)', 'asdasdasd')
print(res1.group('aaa')) # a
print(res1.group('ddd')) # d
针对search和match,因为findall不支持关键字group取值。
collections模块
-
具名元组
from collections import namedtuple
# 先产生一个元组对象模板
point = namedtuple('翻译',['center','coin'])
# 创建元组对象数据
p1 = point('中央','硬币')
print(p1) # 翻译(center='中央', coin='硬币')
print(p1.center) # 中央
具名元组的应用非常广泛,比如数学中的坐标系,娱乐活动中的扑克牌......
-
双端队列
我们之前讲过队列与堆栈,队列就是先进先出,堆栈就是先进后出,队列默认只有一端进一端出,而我们今天讲的双端队列两端都可以进出。
在讲双端队列之前我们先讲一下单端队列:
import queue
a = queue.Queue(3) # 最多只能存放三个数据
a.put(111)
a.put(222)
a.put(333)
# a.put(444) # 如果队列满了继续添加就会原地等待,等待其他数据被取出腾出位置
print(a.get()) # 111
print(a.get()) # 222
print(a.get()) # 333
# print(a.get()) # 如果队列空了继续取值就会原地等待,等待其他数据的添加
这是单端队列,我们来看看双端队列与他的区别:
from collections import deque
a = deque([111, 222, 333])
print(a) # deque([111, 222, 333])
a.append(444) # 右面添加元素
print(a) # deque([111, 222, 333, 444])
a.appendleft(0) # 左面添加元素
print(a) # deque([0, 111, 222, 333, 444])
print(a.pop()) # 444 右边取出数据
print(a.popleft()) # 0 左边取出数据
-
有序字典
正常的字典内部都是无序,因为字典的内部遵循的是哈希算法,我们之所以看到的字典数据有序是因为pycharm内部给我们做了优化,更加美观。而collections模块有一个方法,可以创建有序字典:
from collections import OrderedDict
d = OrderedDict([('name','oscar'),('age',15)])
print(d) # OrderedDict([('name', 'oscar'), ('age', 15)])
# print(d['name']) # oscar
d['name'] = 'jason'
print(d['name']) # jason
print(d.keys()) # odict_keys(['name', 'age'])
print(d.values()) # odict_values(['jason', 15])
-
默认字典
"""
有如下值集合 [11,22,33,44,55,67,77,88,99,999],
将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中。
"""
l = [11,22,33,44,55,67,77,88,99,999]
# dict_new = {'<66': [], '>66': []}
# for i in l:
# if i > 66:
# dict_new['>66'].append(i)
# else:
# dict_new['<66'].append(i)
#
# print(dict_new)
# TODO 默认字典
from collections import defaultdict
dict_new = defaultdict(list) # 默认一个字典,里面的元素是列表
for i in l:
if i > 66:
dict_new['>66'].append(i)
else:
dict_new['<66'].append(i)
print(dict_new) # defaultdict(<class 'list'>, {'<66': [11, 22, 33, 44, 55], '>66': [67, 77, 88, 99, 999]})
-
计数器
# 统计字符串中元素出现的个数,返回的字典格式
s = 'asasdssadsasasd'
# dict_new = {}
# for i in s:
# if i not in dict_new.keys():
# dict_new[i] = 1
# else:
# dict_new[i] += 1
# print(dict_new) # {'a': 5, 's': 7, 'd': 3}
from collections import Counter
res = Counter(s)
print(res) # Counter({'s': 7, 'a': 5, 'd': 3})
print(res['d']) # 3 也可以当成字典用
time模块
-
常用方法
import time
# time.sleep(3) # 指定程序推迟运行的时间,单位为秒
# print('aaa')
# 时间戳,从1970年一月一号零点零分零秒至今的秒数
print(time.time()) # 1648544115.3788862
-
三种表现时间的格式
(1). 时间戳
从1970年一月一号零点零分零秒至今的秒数
(2). 结构化时间
该时间类型主要是给计算机看,人看起来不太方便
| 结构化时间 | 代表的含义 |
|---|---|
| tm_year | 年(比如2022) |
| tm_mon | 月(1-12) |
| tm_mday | 日(1-31) |
| tm_hour | 时(0-23) |
| tm_min | 分(0-59) |
| tm_sec | 秒(0-60) |
| tm_wday | 一周(0-6,0表示周一) |
| tm_yday | 一年中的第几天 |
| tm_isdst | 是否是夏令时(默认为0) |
print(time.localtime()) # time.struct_time(tm_year=2022, tm_mon=3, tm_mday=29, tm_hour=17, tm_min=18, tm_sec=15, tm_wday=1, tm_yday=88, tm_isdst=0)
(3).格式化时间
人最容易接受的一种格式。
| 格式化时间 | 代表的含义 |
|---|---|
| %y | 两位数的年份表示(00-99) |
| %Y | 四位数的年份表示(000-9999) |
| %m | 月份(01-12) |
| %d | 月内中的一天(0-31) |
| %H | 24小时制小时数(0-23) |
| %I | 12小时制小时数(01-12) |
| %M | 分钟数(00=59) |
| %S | 秒(00-59) |
| %a | 本地简化星期名称 |
| %A | 本地完整星期名称 |
|---|---|
| %b | 本地简化的月份名称 |
| %B | 本地完整的月份名称 |
| %c | 本地相应的日期表示和时间表示 |
| %j | 年内的一天(001-366) |
| %p | 本地A.M.或P.M.的等价符 |
| %U | 一年中的星期数(00-53)星期天为星期的开始 |
| %w | 星期(0-6),星期天为星期的开始 |
| %W | 一年中的星期数(00-53)星期一为星期的开始 |
| %x | 本地相应的日期表示 |
| %X | 本地相应的时间表示 |
|---|---|
| %Z | 当前时区的名称 |
| %% | %号本身 |
-
时间类型的转换
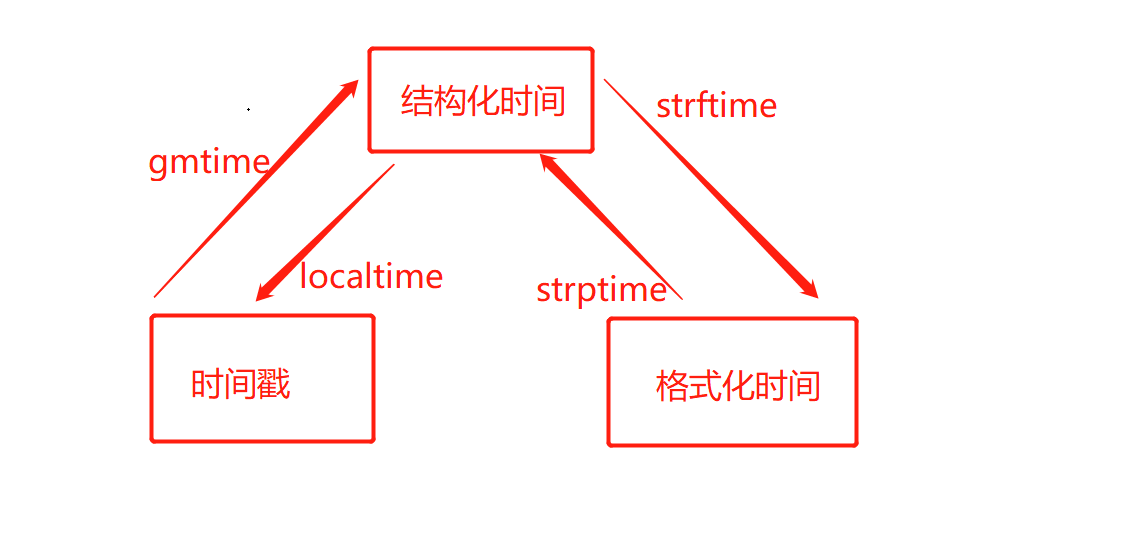
点击查看代码
# 时间戳-->结构化时间
print(time.gmtime(1100000000)) # time.struct_time(tm_year=2004, tm_mon=11, tm_mday=9, tm_hour=11, tm_min=33, tm_sec=20, tm_wday=1, tm_yday=314, tm_isdst=0)
print(time.localtime(1100000000)) # time.struct_time(tm_year=2004, tm_mon=11, tm_mday=9, tm_hour=19, tm_min=33, tm_sec=20, tm_wday=1, tm_yday=314, tm_isdst=0)
# 结构化时间-->时间戳
res = time.localtime(1100000000)
print(res) # time.struct_time(tm_year=2004, tm_mon=11, tm_mday=9, tm_hour=19, tm_min=33, tm_sec=20, tm_wday=1, tm_yday=314, tm_isdst=0)
# print(time.mktime(res)) # 1100000000.0
# 结构化时间-->格式化时间
print(time.strftime('%Y/%m/%d %X')) # 2022/03/29 17:43:53
# 格式化时间-->结构化时间
res1 = time.strptime('2022/03/29','%Y/%m/%d') #切记strptime的参数,第一个参数是格式化时间,第二个参数是格式化时间的表达式,必须一致
print(res1) # time.struct_time(tm_year=2022, tm_mon=3, tm_mday=29, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=1, tm_yday=88, tm_isdst=-1)
datetime模块
-
基本操作
import datetime
# date就是年月日
# print(datetime.date.today()) # 2022-03-29
# datetime就是年月日时分秒
# print(datetime.datetime.today()) # 2022-03-29 17:50:34.204416
res = datetime.date.today()
print(res.year) # 2022
print(res.month) # 3
print(res.day) # 29
print(res.weekday()) # 1 一周的哪一天(0-6),0是周一
print(res.isoweekday()) # 2 一周的哪一天(1-7),1是周一
-
时间差
'''
时间差计算公式:
日期对象 = 日期对象 +/- timedelta对象
timedelta对象 = 日期对象 +/- 日期对象
'''
ctime = datetime.datetime.today()
time_tel = datetime.timedelta(days=2)
print(ctime) # 2022-03-29 18:00:13.445878
print(ctime + time_tel) # 2022-03-31 18:00:39.982673
print(ctime - time_tel) # 2022-03-27 18:00:55.687872
res = ctime + time_tel
print(res - ctime) # 2 days, 0:00:00
random模块
# 随机数模块
import random
print(random.random()) # 随机生产一个0到1之间的小数
print(random.uniform(9,10)) # 随机生产一个9到10之间的小数
print(random.randint(2,6)) # 随机生产一个2到6之间的整数,包括2和6
l = [11, 22, 33, 44, 55, 66, 77, 88, 99]
random.shuffle(l) # 随机打散一个数据集合
print(l) # [44, 22, 33, 88, 77, 11, 66, 55, 99]
print(random.choice(l)) # 随机抽取一个数据集合的元素
print(random.sample(l,3)) # [88, 44, 33] 随机抽取数据集合的元素,抽取的个数可以指定
这里是IT小白陆禄绯,欢迎各位大佬的指点!!!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号