
来测试下 2019 你一共写了多少行代码?
自己动手实现一个代码统计工具
导入所需的库
这个程序需要用到的库有:os,time
这两个库都是 Python 自带的,所以我们直接 import 就行
1 import os 2 import time
现在我们已经导入要使用的库了,可以直接写代码了
定义要读取的文件地址
首先,我们定义一个路径吧,因为要读取文件统计代码行数嘛
1 # 指定读取的路径 2 base_dir = './' 3 4 # 定义一个文件列表 5 file_lists = []
- base_dir :假设我们读取的是当前目录下的目录 / 文件
- file_lists:因为我们读取的文件不止一个,所以使用列表来存储
指定你要读取的文件类型
1 file_type = ['py']
这里以 Python 文件为例,因为代码是用 Python 写的嘛,所以读取 py 为后缀的文件
遍历目录 / 文件
上面我们定义了路径是 ./ (当前目录下),文件类型是 py 的,接下来我们需要遍历一下当前路径中的文件,代码如下:
1 # 定义一个 getDir_or_File 函数,看名字都应该知道是什么意思了吧 2 # base_dir 是我们定义的路径(路径为 ./) 3 def getDir_or_File(base_dir): 4 5 # 将文件列表定义为全局的 6 global file_lists 7 8 # 遍历当前目录下所有的目录路径,目录名,文件名 9 for parent,dirnames,filenames in os.walk(base_dir): 10 # 遍历文件名 11 for filename in filenames: 12 # 获取后缀 13 file= filename.split('.')[-1] 14 # 如果获取的后缀是我们定义文件类型 15 if file in file_type: 16 # 将目录路径与文件名连接起来,如('./code.py') 17 file_lists.append(os.path.join(parent,filename))
代码分析
- os.walk(top, topdown=True, οnerrοr=None, followlinks=False):输出在文件夹中的文件名通过在树中游走,向上或者向下
- top :是你所要遍历的目录的地址, 返回的是一个三元组(root,dirs,files)。
- root :所指的是当前正在遍历的这个文件夹的本身的地址
- dirs : 是一个 list ,内容是该文件夹中所有的目录的名字(不包括子目录)
- files :同样是 list , 内容是该文件夹中所有的文件(不包括子目录)
- topdown :可选,为 True,则优先遍历 top 目录,否则优先遍历 top 的子目录(默认为开启)。如果 topdown 参数为 True,walk 会遍历top文件夹,与top 文件夹中每一个子目录。
- onerror : 可选,需要一个 callable 对象,当 walk 需要异常时,会调用。
- followlinks : 可选,如果为 True,则会遍历目录下的快捷方式(linux 下是软连接 symbolic link )实际所指的目录(默认关闭),如果为 False,则优先遍历 top 的子目录
这样讲好像不太好理解,我们实践一下,编写以下代码进行测试
1 import os 2 3 for parent, dirnames, filenames in os.walk("./"): 4 print(parent) 5 print(dirnames) 6 print(filenames)
从图中可知道改代码位于 demo 文件夹下
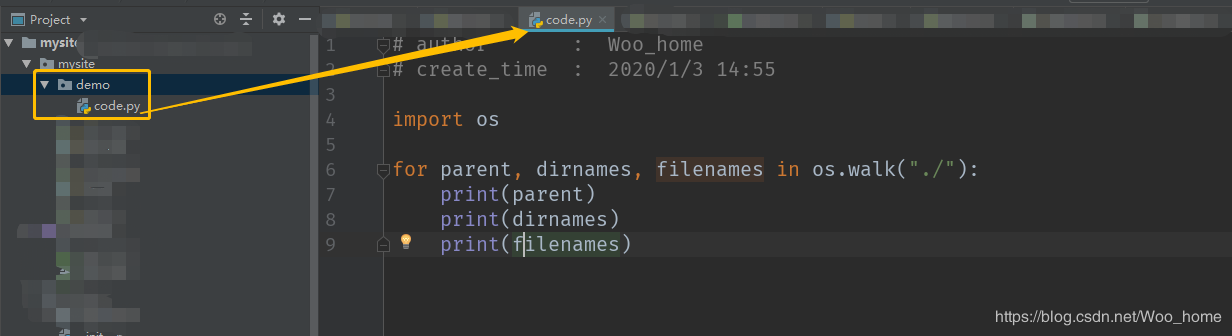
OK,我们运行一下这个程序

没学过 os 库的朋友可能会有点疑问,为什么 for 循环那里要有三个参数?必须的吗?
1 for parent, dirnames, filenames in os.walk("./"):
是的,是必须的,不信?我们去掉一个参数运行一下,代码如下:
1 import os 2 3 for parent, filenames in os.walk("./"): 4 print(parent) 5 print(filenames)
运行,报错了

报错信息为:ValueError: too many values to unpack (expected 2)
说我们太多值无法解包?(一头雾水)
我们来看下官方是怎么解释的

对于根目录在目录树顶部的每个目录(包括顶部本身,但不包括 ’ . ’ 和 '… '),产生一个三元组目录路径,目录名,文件名
这也就说明了 for 循环中的参数是缺一不可的
读取代码行数
上面我们已经实现了遍历目录和文件了,接下来我们需要读取文件了
说到读取文件相信学习过 Python 的朋友都应该知道,无非就是 open 和 with open,没学习过的朋友也没关系,这里简单教你几下
首先我们定义一个函数 def countLines(file_name): ,具体代码如下:
1 # 统计一个文件的行数 2 def countLines(file_name): 3 # 定义一个变量 count,并赋值为 0 4 count = 0 5 # 这里我们使用 open 函数来读取文件内容,readlines() 的意思是按行读取 6 for file_line in open(file_name,'r',encoding='utf-8').readlines(): 7 # 过滤掉空行,空行总不是你写的代码吧对吧 8 if file_line != '' and file_line != '\n': 9 # 满足上面的条件的话就行数 + 1 10 count += 1 11 # 打印文件名和行数 12 print(file_name + '----' , count) 13 # 返回 count,为什么要返回?因为这只是一个文件而已,既然要统计代码行数总不能只统计一个文件吧? 14 return count
注意: open 那里一定要加上编码格式(encoding=‘utf-8’),否则会报以下错误
UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0x84 in position 48: illegal multibyte sequence
你以为这样就可以了?no,继续上代码:
1 if __name__ == '__main__' : 2 # 用于基准测试的性能计数器。 3 startTime = time.perf_counter() 4 # 调用 getDir_or_File() 函数来遍历目录 and 文件 5 getDir_or_File(base_dir) 6 # 定义代码总行数的变量,并赋值为 0 7 totallines = 0 8 # 遍历所有文件 9 for filelist in file_lists: 10 # 计算总代码行数 11 totallines = totallines + countLines(filelist) 12 # 打印代码行数 13 print('total lines:',totallines) 14 # 打印程序执行时间 15 print('Success! Cost Time: %0.2f seconds' % (time.perf_counter() - startTime))
代码测试
到这里我们的代码已经编写完成,我们测试一下我们的程序,测试之前我们先准备几个 py 文件

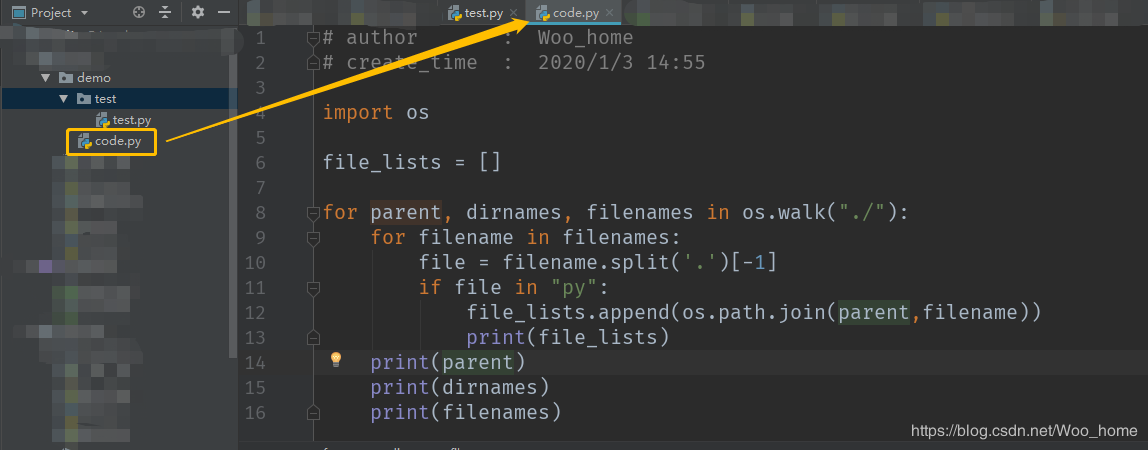
我们在 demo 文件夹下创建了一个 code.py 文件和一个 test 目录,而我们的 test 目录下也有一个 test.py 文件,两个文件的内容是一样的,只是一个没有空行,一个有空行,我们来运行一下我们编写的程序,我们将路径指向 demo 目录
1 base_dir = './demo'

OK,运行一下程序

从图中我们可以看到程序执行成功了,而且行数也统计出来了,那么统计到底对不对呢?是正确的,我们上面的 code.py 是有空行的,去掉空行就是 13 行,而 test.py 本来就是 13 行且没有空行
全部代码
全部代码如下:
视频代码学习群:887934385
1 # 导入库 2 import os 3 import time 4 5 # 指定读取的路径 6 base_dir = '需要指定的路径' 7 8 # 文件列表 9 file_lists = [] 10 11 # 指定想要统计的文件类型 12 file_type = ['py'] 13 14 #遍历文件, 递归遍历文件夹中的所有 15 # 定义一个 getDir_or_File 函数,看名字都应该知道是什么意思了吧 16 # base_dir 是我们定义的路径(路径为 ./) 17 def getDir_or_File(base_dir): 18 19 # 将文件列表定义为全局的 20 global file_lists 21 22 # 遍历当前目录下所有的目录路径,目录名,文件名 23 for parent,dirnames,filenames in os.walk(base_dir): 24 # 遍历文件名 25 for filename in filenames: 26 # 获取后缀 27 file= filename.split('.')[-1] 28 # 如果获取的后缀是我们定义文件类型 29 if file in file_type: 30 # 将目录路径与文件名连接起来,如('./code.py') 31 file_lists.append(os.path.join(parent,filename)) 32 33 # 统计一个文件的行数 34 def countLines(file_name): 35 # 定义一个变量 count,并赋值为 0 36 count = 0 37 # 这里我们使用 open 函数来读取文件内容,readlines() 的意思是按行读取 38 for file_line in open(file_name,'r',encoding='utf-8').readlines(): 39 # 过滤掉空行,空行总不是你写的代码吧对吧 40 if file_line != '' and file_line != '\n': 41 # 满足上面的条件的话就行数 + 1 42 count += 1 43 # 打印文件名和行数 44 print(file_name + '----' , count) 45 # 返回 count,为什么要返回?因为这只是一个文件而已,既然要统计代码行数总不能只统计一个文件吧? 46 return count 47 48 if __name__ == '__main__' : 49 # 用于基准测试的性能计数器。 50 startTime = time.perf_counter() 51 # 调用 getDir_or_File() 函数来遍历目录 and 文件 52 getDir_or_File(base_dir) 53 # 定义代码总行数的变量,并赋值为 0 54 totallines = 0 55 # 遍历所有文件 56 for filelist in file_lists: 57 # 计算总代码行数 58 totallines = totallines + countLines(filelist) 59 # 打印代码行数 60 print('total lines:',totallines) 61 # 打印程序执行时间 62 print('Success! Cost Time: %0.2f seconds' % (time.perf_counter() - startTime))
打包成可执行程序
其实我们还可以修改一下代码将代码打包成 exe 文件,这样就可以转发给别人使用了,如我们将这个文件命名为 test.py,使用 pyinstaller 打包程序
1 pyinstaller -F test.py -w
这个实现很简单,但是也有个缺点,就是需要把程序放到你要统计的路径下才能统计不能指定路径统计,其实也差不多,只要把程序放到你要统计的目录就行了,来测试一下:
打包后的程序如下

放到我的一个 Django 项目下,双击 test.exe

双击运行后会在该目录下创建一个 totalcount 的 txt 文本

我们打开这个文本看下,可以看到文本中显示还读取到了 html 了,是自己设置的哈,并不是代码写错了哈哈
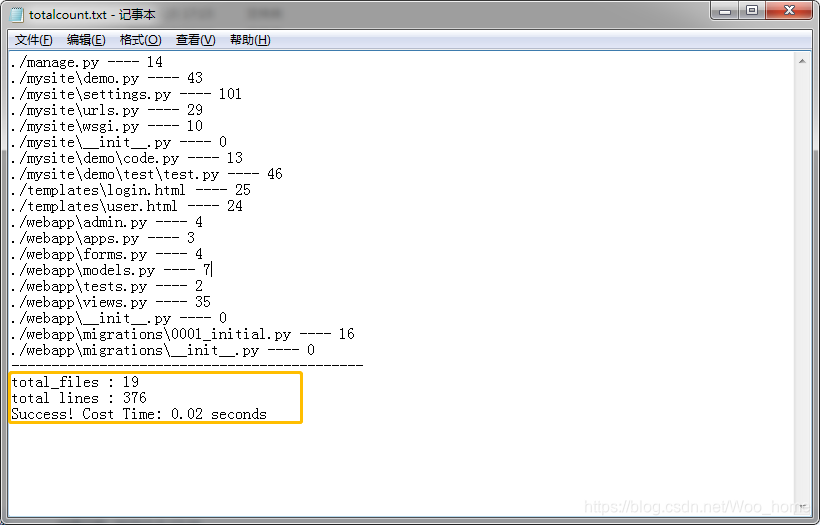
一共读取了 19 个文件
376 行代码
用时 0.02s
关于很多朋友问我打包成 exe 运行无法生成 txt 文件,其实还稍作了修改的哈
我把打包好的 exe 放到了Github了 文件下载地址,想要的朋友可以去下载哦,喜欢的朋友记得给个star哦,非常感谢

 浙公网安备 33010602011771号
浙公网安备 33010602011771号