
Tensorflow分布式部署和开发
关于tensorflow的分布式训练和部署, 官方有个英文的文档介绍,但是写的比较简单, 给的例子也比较简单,刚接触分布式深度学习的可能不太容易理解。在网上看到一些资料,总感觉说的不够通俗易懂,不如自己写一个通俗易懂给大家分享一下。
如果大家有看不懂的,欢迎留言,我再改文章,改到大学一年级的学生可以看懂的程度。
1. 单机多GPU训练
先简单介绍下单机的多GPU训练,然后再介绍分布式的多机多GPU训练。
单机的多GPU训练, tensorflow的官方已经给了一个cifar的例子,已经有比较详细的代码和文档介绍, 这里大致说下多GPU的过程,以便方便引入到多机多GPU的介绍。
单机多GPU的训练过程:
a) 假设你的机器上有3个GPU;
b) 在单机单GPU的训练中,数据是一个batch一个batch的训练。 在单机多GPU中,数据一次处理3个batch(假设是3个GPU训练), 每个GPU处理一个batch的数据计算。
c) 变量,或者说参数,保存在CPU上
d) 刚开始的时候数据由CPU分发给3个GPU, 在GPU上完成了计算,得到每个batch要更新的梯度。
e) 然后在CPU上收集完了3个GPU上的要更新的梯度, 计算一下平均梯度,然后更新参数。
f) 然后继续循环这个过程。
通过这个过程,处理的速度取决于最慢的那个GPU的速度。如果3个GPU的处理速度差不多的话, 处理速度就相当于单机单GPU的速度的3倍减去数据在CPU和GPU之间传输的开销,实际的效率提升看CPU和GPU之间数据的速度和处理数据的大小。
写到这里觉得自己写的还是不同通俗易懂, 下面就打一个更加通俗的比方来解释一下:
老师给小明和小华布置了10000张纸的乘法题并且把所有的乘法的结果加起来, 每张纸上有128道乘法题。 这里一张纸就是一个batch, batch_size就是128. 小明算加法比较快, 小华算乘法比较快,于是小华就负责计算乘法, 小明负责把小华的乘法结果加起来 。 这样小明就是CPU,小华就是GPU.
这样计算的话, 预计小明和小华两个人得要花费一个星期的时间才能完成老师布置的题目。 于是小明就招来2个算乘法也很快的小红和小亮。 于是每次小明就给小华,小红,小亮各分发一张纸,让他们算乘法, 他们三个人算完了之后, 把结果告诉小明, 小明把他们的结果加起来,然后再给他们没人分发一张算乘法的纸,依次循环,知道所有的算完。
这里小明采用的是同步模式,就是每次要等他们三个都算完了之后, 再统一算加法,算完了加法之后,再给他们三个分发纸张。这样速度就取决于他们三个中算乘法算的最慢的那个人, 和分发纸张的速度。
2. 分布式多机多GPU训练
随着设计的模型越来越复杂,模型参数越来越多,越来越大, 大到什么程度?多到什么程度? 多参数的个数上百亿个, 训练的数据多到按TB级别来衡量。大家知道每次计算一轮,都要计算梯度,更新参数。 当参数的量级上升到百亿量级甚至更大之后, 参数的更新的性能都是问题。 如果是单机16个GPU, 一个step最多也是处理16个batch, 这对于上TB级别的数据来说,不知道要训练到什么时候。于是就有了分布式的深度学习训练方法,或者说框架。
参数服务器
在介绍tensorflow的分布式训练之前,先说下参数服务器的概念。
前面说道, 当你的模型越来越大, 模型的参数越来越多,多到模型参数的更新,一台机器的性能都不够的时候, 很自然的我们就会想到把参数分开放到不同的机器去存储和更新。
因为碰到上面提到的那些问题, 所有参数服务器就被单独拧出来, 于是就有了参数服务器的概念。 参数服务器可以是多台机器组成的集群, 这个就有点类似分布式的存储架构了, 涉及到数据的同步,一致性等等, 一般是key-value的形式,可以理解为一个分布式的key-value内存数据库,然后再加上一些参数更新的操作。 详细的细节可以去google一下, 这里就不详细说了。 反正就是当性能不够的时候, 几百亿的参数分散到不同的机器上去保存和更新,解决参数存储和更新的性能问题。
借用上面的小明算题的例子,小明觉得自己算加法都算不过来了, 于是就叫了10个小明过来一起帮忙算。
tensorflow的分布式
不过据说tensorflow的分布式没有用参数服务器,用的是数据流图, 这个暂时还没研究,不过应该和参数服务器有很多相似的地方,这里介绍先按照参数服务器的结构来介绍。
tensorflow的分布式有in-graph和between-gragh两种架构模式。 这里分别介绍一下。
in-graph 模式:
in-graph模式和单机多GPU模型有点类似。 还是一个小明算加法, 但是算乘法的就可以不止是他们一个教室的小华,小红,小亮了。 可以是其他教师的小张,小李。。。。.
in-graph模式, 把计算已经从单机多GPU,已经扩展到了多机多GPU了, 不过数据分发还是在一个节点。 这样的好处是配置简单, 其他多机多GPU的计算节点,只要起个join操作, 暴露一个网络接口,等在那里接受任务就好了。 这些计算节点暴露出来的网络接口,使用起来就跟本机的一个GPU的使用一样, 只要在操作的时候指定tf.device("/job:worker/task:n"), 就可以向指定GPU一样,把操作指定到一个计算节点上计算,使用起来和多GPU的类似。 但是这样的坏处是训练数据的分发依然在一个节点上, 要把训练数据分发到不同的机器上, 严重影响并发训练速度。在大数据训练的情况下, 不推荐使用这种模式。
between-graph模式
between-graph模式下,训练的参数保存在参数服务器, 数据不用分发, 数据分片的保存在各个计算节点, 各个计算节点自己算自己的, 算完了之后, 把要更新的参数告诉参数服务器,参数服务器更新参数。这种模式的优点是不用训练数据的分发了, 尤其是在数据量在TB级的时候, 节省了大量的时间,所以大数据深度学习还是推荐使用between-graph模式。
同步更新和异步更新
in-graph模式和between-graph模式都支持同步和异步更新
在同步更新的时候, 每次梯度更新,要等所有分发出去的数据计算完成后,返回回来结果之后,把梯度累加算了均值之后,再更新参数。 这样的好处是loss的下降比较稳定, 但是这个的坏处也很明显, 处理的速度取决于最慢的那个分片计算的时间。
在异步更新的时候, 所有的计算节点,各自算自己的, 更新参数也是自己更新自己计算的结果, 这样的优点就是计算速度快, 计算资源能得到充分利用,但是缺点是loss的下降不稳定, 抖动大。
在数据量小的情况下, 各个节点的计算能力比较均衡的情况下, 推荐使用同步模式;数据量很大,各个机器的计算性能掺差不齐的情况下,推荐使用异步的方式。
例子
tensorflow官方有个分布式tensorflow的文档,但是例子没有完整的代码, 这里写了一个最简单的可以跑起来的例子,供大家参考,这里也傻瓜式给大家解释一下代码,以便更加通俗的理解。
代码位置:
https://github.com/thewintersun/distributeTensorflowExample
功能说明:
代码实现的功能: 对于表达式 Y = 2 * X + 10, 其中X是输入,Y是输出, 现在有很多X和Y的样本, 怎么估算出来weight是2和biasis是10.
所有的节点,不管是ps节点还是worker节点,运行的都是同一份代码, 只是命令参数指定不一样。
执行的命令示例:
ps 节点执行:
CUDA_VISIBLE_DEVICES='' python distribute.py --ps_hosts=192.168.100.42:2222 --worker_hosts=192.168.100.42:2224,192.168.100.253:2225 --job_name=ps --task_index=0
worker 节点执行:
CUDA_VISIBLE_DEVICES=0 python distribute.py --ps_hosts=192.168.100.42:2222 --worker_hosts=192.168.100.42:2224,192.168.100.253:2225 --job_name=worker --task_index=0 CUDA_VISIBLE_DEVICES=0 python distribute.py --ps_hosts=192.168.100.42:2222 --worker_hosts=192.168.100.42:2224,192.168.100.253:2225 --job_name=worker --task_index=1 80
1 # Define parameters 2 FLAGS = tf.app.flags.FLAGS 3 tf.app.flags.DEFINE_float('learning_rate', 0.00003, 'Initial learning rate.') 4 tf.app.flags.DEFINE_integer('steps_to_validate', 1000, 5 'Steps to validate and print loss') 6 # For distributed 7 tf.app.flags.DEFINE_string("ps_hosts", "", 8 "Comma-separated list of hostname:port pairs") 9 tf.app.flags.DEFINE_string("worker_hosts", "", 10 "Comma-separated list of hostname:port pairs") 11 tf.app.flags.DEFINE_string("job_name", "", "One of 'ps', 'worker'") 12 tf.app.flags.DEFINE_integer("task_index", 0, "Index of task within the job") 13 # Hyperparameters 14 learning_rate = FLAGS.learning_rate 15 steps_to_validate = FLAGS.steps_to_validate
代码说明:
1. 故意把学习率设置的特别小,是想让它算慢点,好看见过程;
2. 通过命令行参数可以传入ps节点的ip和端口, worker节点的ip和端口。ps节点就是paramter server的缩写, 主要是保存和更新参数的节点, worker节点主要是负责计算的节点。这里说的节点都是虚拟的节点,不一定是物理上的节点;
3. 多个节点用逗号分隔;
1 ps_hosts = FLAGS.ps_hosts.split(",") 2 worker_hosts = FLAGS.worker_hosts.split(",") 3 cluster = tf.train.ClusterSpec({"ps": ps_hosts, "worker": worker_hosts}) 4 server = tf.train.Server(cluster,job_name=FLAGS.job_name,task_index=FLAGS.task_index) 5 6 if FLAGS.job_name == "ps": 7 server.join() 8 elif FLAGS.job_name == "worker": 9 with tf.device(tf.train.replica_device_setter( 10 worker_device="/job:worker/task:%d" % FLAGS.task_index, 11 cluster=cluster)):
代码说明:
1. ClusterSpec的定义,需要把你要跑这个任务的所有的ps和worker 的节点的ip和端口的信息都包含进去,所有的节点都要执行这段代码, 就大家互相知道了, 这个集群里面都有哪些成员,不同的成员的类型是什么, 是ps节点还是worker节点。
2. tf.train.Server这个的定义开始,就每个节点不一样了。 根据执行的命令的参数不同,决定了这个任务是哪个任务。
如果任务名字是ps的话, 程序就join到这里,作为参数更新的服务, 等待其他worker节点给他提交参数更新的数据。
如果是worker任务,就执行后面的计算任务。
3. replica_device_setter, 这个大家可以注意一下, 可以看看tensorflow的文档对这个的解释和python的源码。 在这个with语句之下定义的参数, 会自动分配到参数服务器上去定义,如果有多个参数服务器, 就轮流循环分配。
1 global_step = tf.Variable(0, name='global_step', trainable=False) 2 3 input = tf.placeholder("float") 4 label = tf.placeholder("float") 5 6 weight = tf.get_variable("weight", [1], tf.float32, initializer=tf.random_normal_initializer()) 7 biase = tf.get_variable("biase", [1], tf.float32, initializer=tf.random_normal_initializer()) 8 pred = tf.mul(input, weight) + biase 9 10 loss_value = loss(label, pred) 11 12 train_op = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss_value, global_step=global_step) 13 init_op = tf.initialize_all_variables() 14 saver = tf.train.Saver() 15 tf.scalar_summary('cost', loss_value) 16 summary_op = tf.merge_all_summaries()
1 sv = tf.train.Supervisor(is_chief=(FLAGS.task_index == 0), 2 logdir="./checkpoint/", 3 init_op=init_op, 4 summary_op=None, 5 saver=saver, 6 global_step=global_step, 7 save_model_secs=60) 8 with sv.managed_session(server.target) as sess: 9 step = 0 10 while step < 1000000: 11 train_x = np.random.randn(1) 12 train_y = 2 * train_x + np.random.randn(1) * 0.33 + 10 13 _, loss_v, step = sess.run([train_op, loss_value,global_step], feed_dict={input:train_x, label:train_y}) 14 if step % steps_to_validate == 0: 15 w,b = sess.run([weight,biase]) 16 print("step: %d, weight: %f, biase: %f, loss: %f" %(step, w, b, loss_v))
代码说明:
1. Supervisor。 含义类似一个监督者, 就是因为分布式了, 很多机器都在运行, 像什么参数初始化, 保存模型, 写summary什么的,这个supervisoer帮你一起弄起来了, 就不用自己去手工去做这些事情了,而且在分布式的环境下设计到各种参数的共享, 其中的过程自己手工写也不好写, 于是tensorflow就给大家包装好这么一个东西了。 这里的参数is_chief比较重要, 在所有的计算节点里还是有一个主节点的, 这个主节点来负责初始化参数, 模型的保存,summary的保存。 logdir就是保存和装载模型的路径。 不过这个似乎的启动就会去这个logdir的目录去看有没有checkpoint的文件,有的话就自动装载了,没有就用init_op指定的初始化参数, 好像没有参数指定不让它自动load的;
2. 主的worker节点负责模型参数初始化等工作, 在这个过程中, 其他worker节点等待主节点完成初始化工作, 等主节点初始化完成后, 好了, 大家一起开心的跑数据。
3. 这里的global_step的值,是可以所有计算节点共享的, 在执行optimizer的minimize的时候, 会自动加1, 所以可以通过这个可以知道所有的计算节点一共计算了多少步了。
程序结果示例:
好了,然后我们就开始跑,结果显示如下:

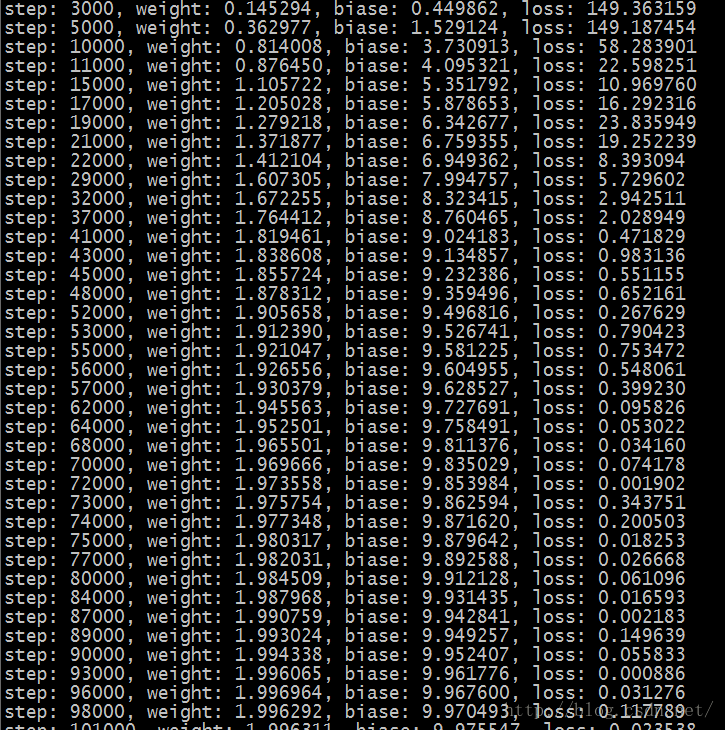
如果还有问题未能得到解决,搜索887934385交流群,进入后下载资料工具安装包等。最后,感谢观看!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号