Oracle索引(Index)介绍使用
1.什么是引
索引是建立在表的一列或多个列上的辅助对象,目的是加快访问表中的数据;Oracle存储索引的数据结构是B*树,位图索引也是如此,只不过是叶子节点不同B*数索引;索引由根节点、分支节点和叶子节点组成,上级索引块包含下级索引块的索引数据,叶节点包含索引数据和确定行实际位置的rowid。
2.使用索引的目的
当查询返回的记录数排序表<40%非排序表 <7%且表的碎片较多(频繁增加、删除)时可以加快查询速度减少I/O操作消除磁盘排序
3.索引的分类及结构
从物理上说,索引通常可以分为:分区和非分区索引、常规B树索引、位图(bitmap)索引、翻转(reverse)索引等。其中,B树索引属于最常见的索引,由于我们的这篇文章主要就是对B树索引所做的探讨,因此下面只要说到索引,都是指B树索引。
B树索引是一个典型的树结构,其包含的组件主要是:
1) 叶子节点(Leaf node):包含条目直接指向表里的数据行。
2) 分支节点(Branch node):包含的条目指向索引里其他的分支节点或者是叶子节点。
3) 根节点(Root node):一个B树索引只有一个根节点,它实际就是位于树的最顶端的分支节点。
可以用下图一来描述B树索引的结构。其中,B表示分支节点,而L表示叶子节点。
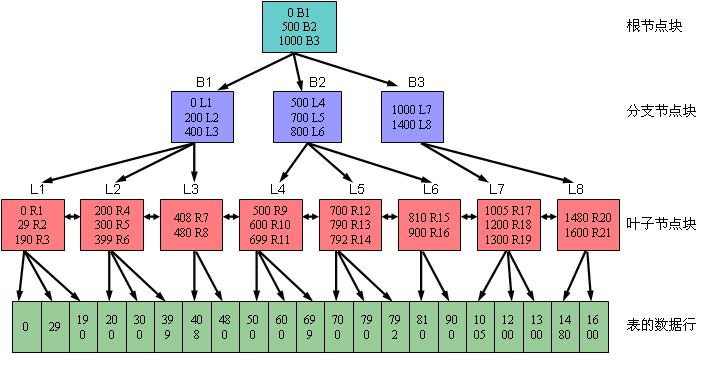
对于分支节点块(包括根节点块)来说,其所包含的索引条目都是按照顺序排列的(缺省是升序排列,也可以在创建索引时指定为降序排列)。每个索引条目(也可以叫做每条记录)都具有两个字段。第一个字段表示当前该分支节点块下面所链接的索引块中所包含的最小键值;第二个字段为四个字节,表示所链接的索引块的地址,该地址指向下面一个索引块。在一个分支节点块中所能容纳的记录行数由数据块大小以及索引键值的长度决定。比如从上图一可以看到,对于根节点块来说,包含三条记录,分别为(0 B1)、(500 B2)、(1000 B3),它们指向三个分支节点块。其中的0、500和1000分别表示这三个分支节点块所链接的键值的最小值。而B1、B2和B3则表示所指向的三个分支节点块的地址。
对于叶子节点块来说,其所包含的索引条目与分支节点一样,都是按照顺序排列的(缺省是升序排列,也可以在创建索引时指定为降序排列)。每个索引条目(也可以叫做每条记录)也具有两个字段。第一个字段表示索引的键值,对于单列索引来说是一个值;而对于多列索引来说则是多个值组合在一起的。第二个字段表示键值所对应的记录行的ROWID,该ROWID是记录行在表里的物理地址。如果索引是创建在非分区表上或者索引是分区表上的本地索引的话,则该ROWID占用6个字节;如果索引是创建在分区表上的全局索引的话,则该ROWID占用10个字节。
知道这些信息以后,我们可以举个例子来说明如何估算每个索引能够包含多少条目,以及对于表来说,所产生的索引大约多大。对于每个索引块来说,缺省的PCTFREE为10%,也就是说最多只能使用其中的90%。同时9i以后,这90%中也不可能用尽,只能使用其中的87%左右。也就是说,8KB的数据块中能够实际用来存放索引数据的空间大约为6488(8192×90%×88%)个字节。
假设我们有一个非分区表,表名为warecountd,其数据行数为130万行。该表中有一个列,列名为goodid,其类型为char(8),那么也就是说该goodid的长度为固定值:8。同时在该列上创建了一个B树索引。
在叶子节点中,每个索引条目都会在数据块中占一行空间。每一行用2到3个字节作为行头,行头用来存放标记以及锁定类型等信息。同时,在第一个表示索引的键值的字段中,每一个索引列都有1个字节表示数据长度,后面则是该列具体的值。那么对于本例来说,在叶子节点中的一行所包含的数据大致如下图二所示:

从上图可以看到,在本例的叶子节点中,一个索引条目占18个字节。同时我们知道8KB的数据块中真正可以用来存放索引条目的空间为6488字节,那么在本例中,一个数据块中大约可以放360(6488/18)个索引条目。而对于我们表中的130万条记录来说,则需要大约3611(1300000/360)个叶子节点块。
而对于分支节点里的一个条目(一行)来说,由于它只需保存所链接的其他索引块的地址即可,而不需要保存具体的数据行在哪里,因此它所占用的空间要比叶子节点要少。分支节点的一行中所存放的所链接的最小键值所需空间与上面所描述的叶子节点相同;而存放的索引块的地址只需要4个字节,比叶子节点中所存放的ROWID少了2个字节,少的这2个字节也就是ROWID中用来描述在数据块中的行号所需的空间。因此,本例中在分支节点中的一行所包含的数据大致如下图三所示:

4.怎样建立索引
create index <index_name> on <table_name>(<column_name>) [tablespace<tablespace_name>];
1、普通索引
create index index_text_txt on test(txt);
2、唯一索引 Oracle 自动在表的主键上创建唯一索引
create unique index <index_name> on <index_name>(<coiumn_name>);
3、位图索引
作用范围及优点:
1、位图索引适合创建在低级数列(重复的数值多,如性别)上
2、减少响应时间
3、节省空间占用
create bitmap index <index_name> on <table_name>(<column_name>)
4、组合索引
作用范围及优点:
1、组合索引是在表的多个列上创建的索引
2、索引中的顺序是任意的
3、如果SQL语言的WHERE子句中引用了组合索引的所有或大多数列,则可以提高检索速度
create index <index_name> on <table_name>(<column_name1><column_name2>)
5、基于函数索引
create index <index_name> on <table_name>(<function_name>(<column_name>));
6、反向键索引
create index <index_name> on <table_name>(column_name) reverse;
7.重置索引
alter index <index_name> rebuild;
8.删除索引
drop index <index_name>
5.索引失效细节
1.使用不等于操作符(<>, !=)
下面这种情况,即使在列dept_id有一个索引,查询语句仍然执行一次全表扫描
select * from dept where staff_num <> 1000;
但是开发中的确需要这样的查询,难道没有解决问题的办法了吗?
有!
通过把用 or 语法替代不等号进行查询,就可以使用索引,以避免全表扫描:上面的语句改成下面这样的,就可以使用索引了。
select * from dept shere staff_num < 1000 or dept_id > 1000;
2.使用 is null 或 is not null
使用 is null 或is nuo null也会限制索引的使用,因为数据库并没有定义null值。如果被索引的列中有很多null,就不会使用这个索引(除非索引是一个位图索引,关于位图索引,会在以后的blog文章里做详细解释)。在sql语句中使用null会造成很多麻烦。
解决这个问题的办法就是:建表时把需要索引的列定义为非空(not null)
3..使用函数
如果没有使用基于函数的索引,那么where子句中对存在索引的列使用函数时,会使优化器忽略掉这些索引。下面的查询就不会使用索引:
select * from staff where trunc(birthdate) = '01-MAY-82';
但是把函数应用在条件上,索引是可以生效的,把上面的语句改成下面的语句,就可以通过索引进行查找。
select * from staff where birthdate < (to_date('01-MAY-82') + 0.9999);
4.比较不匹配的数据类型
比较不匹配的数据类型也是难于发现的性能问题之一。下面的例子中,dept_id是一个varchar2型的字段,在这个字段上有索引,但是下面的语句会执行全表扫描。
select * from dept where dept_id = 900198;
这是因为oracle会自动把where子句转换成to_number(dept_id)=900198,就是3所说的情况,这样就限制了索引的使用。把SQL语句改为如下形式就可以使用索引
select * from dept where dept_id = '900198';
5.使用like子句
使用like子句查询时,数据需要把所有的记录都遍历来进行判断,索引不能发挥作用,这种情况也要尽量避免。
Like 的字符串中第一个字符如果是‘%’则用不到索引
Column1 like ‘aaa%’ 是可以的
Column1 like ‘%aaa%’用不到
6.使用in
尽管In写法要比exists简单一些,exists一般来说性能要比In要高的多
用In还是用Exists的时机
当in的集合比较小的时候,或者用Exists无法用到选择性高的索引的时候,用In要好,否则就要用Exists
例:select count(*) from person_info where xb in (select xb_id from dic_sex);
Select count(*) from n_acntbasic a where shbxdjm =:a and exists(select 1 from person_info where pid=a.pid and …);
Select * from person_info where zjhm=3101….;将会对person_info全表扫描
Select * from person_info where zjhm =‘3101…’才能用到索引
假定TEST表的dt字段是date类型的并且对dt建了索引。
如果要查‘20041010’一天的数据.下面的方法用不到索引
Select * from test where to_char(dt,’yyyymmdd’) =‘20041010’;
而select * from test where dt >=to_date(‘20041010’,’yyyymmdd’) and dt < to_date(‘20041010’,’yyyymmdd’) + 1 将会用到索引。
7.如果能不用到排序,则尽量避免排序
用到排序的情况有
集合操作。Union ,minus ,intersect等,注:union all 是不排序的。
Order by
Group by
Distinct
In 有时候也会用到排序
确实要排序的时候也尽量要排序小数据量
,尽量让排序在内存中执行,有文章说,内存排序的速度是硬盘排序的1万倍。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号