mysql覆盖索引详解
当发起一个索引覆盖查询时,在explain的extra列可以看到using index的信息
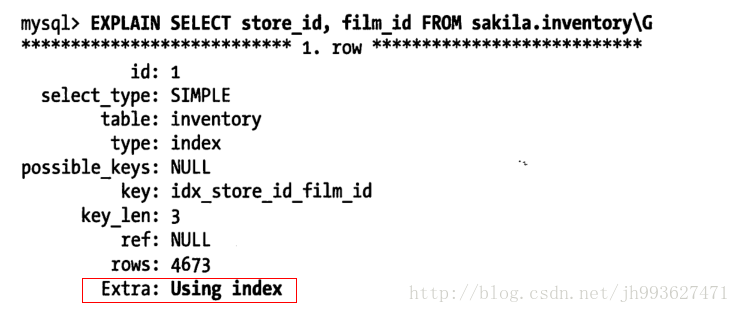
覆盖索引的坑:mysql查询优化器会在执行查询前判断是否有一个索引能进行覆盖,假设索引覆盖了where条件中的字段,但不是整个查询涉及的字段,mysql5.5和之前的版本也会回表获取数据行,尽管并不需要这一行且最终会被过滤掉。

2.mysql不能在索引中执行LIke操作。mysql能在索引中做最左前缀匹配的like比较,但是如果是通配符开头的like查询,存储引擎就无法做比较匹配。这种情况下mysql只能提取数据行的值而不是索引值来做比较
优化后SQL:添加索引(artist,title,prod_id),使用了延迟关联(延迟了对列的访问)
说明:在查询的第一阶段可以使用覆盖索引,在from子句中的子查询找到匹配的prod_id,然后根据prod_id值在外层查询匹配获取需要的所有值。

5.5时API设计不允许mysql将过滤条件传到存储引擎层(是把数据从存储引擎拉到服务器层,在根据条件过滤),5.6之后由于ICP这个特性改善了查询执行方式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号