卡尔曼滤波(七)——非线性系统
非线性系统卡尔曼滤波,又叫“扩展卡尔曼滤波”
模型公式:
Xk=AXk-1+BUk+Wk-1
Zk = HXk + Vk
p(w) ~ N(0,Q)
p(v) ~ N(0,R)
预测:
先验值:X-k = AX^k-1 + BUk-1
先验协方差:P-k = A Pk-1 AT + Qk-1
校正:
卡尔曼增益:Kk = P-kHT / (HP-kHT + R)
后验值:X^k = X-k + Kk (Zk - HX-K)
后验协方差:Pk = (I - KkH)P-k
对于非线性系统,没办法用【Xk=AXk-1+BUk+Wk-1 】表达
只能表达成:xk = f(xk-1,uk-1,wk-1)
zk = h(xk,vk)
p(w) ~ N(0,Q)
p(v) ~ N(0,R)
正态分布的随机变量,通过非线性系统后,就不是正态分布了。
线性正态分布:
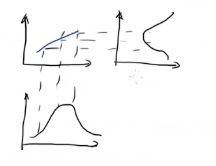
y = kx,x正态,y也是正态
非线性正态分布:
y = f(x)
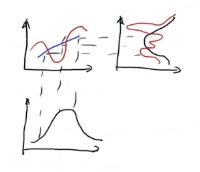
线性化,泰勒一阶展开(当X0非常接近要求的X时,而X不可知,所以X0 相当于初始值,靠猜或用低精度仪器测,但是不能太离谱):
f(x) = f(x0) + δf / δx ( x - x0)
对于高维度,要用到【雅可比矩阵】
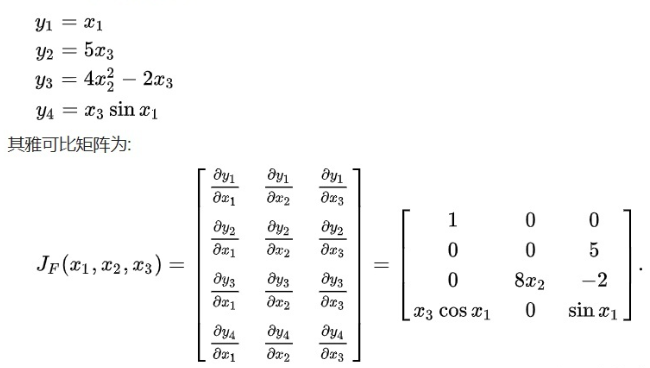
f(x) = f(x0) + J*(X-X0)
对于模型来说,Xk = f(xk-1,uk-1,wk-1) 泰勒展开:
那么,使用Xk 初始值 = X^k-1 (第K-1次后验值)
Xk = f(x^k-1,uk-1,wk-1) + J (Xk - X^k-1) + WkWk-1
疑问:按照泰勒公式,为不是J (Xk-1 - X^k-1)??难道是Xk-1 - X^k-1 与Xk - X^k-1 相当接近??
疑问:WkWk-1 是怎么来的?这个是对Wk-1进行求导的项,在W=0处对Wk-1的偏导
理解起来
1. f(x^k-1,uk-1,wk-1) 为 f(x0)
2. J (Xk - X^k-1) 应该为 J (Xk - Xk初始值 )
3. J = δf / δx,将(X^k-1 , Uk-1 代进去)
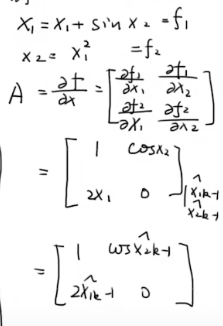
4. 那么J,或者A矩阵,每一步都是变化的,每次都要重新算。
因为wk-1 一般不可以知道,假设为0,那么:
Xk = f(x^k-1,uk-1,0) + J (Xk - X^k-1) + Wwk-1
同理,对于【Zk = HXk + Vk】,令X~k = f(x^k-1,uk-1,0) ,因为模型算出的X~k ,比起X^k-1更加接近真实的Xk
Zk = h(Xk , Vk)
Zk = h(X~k,0) + H (Xk - X~k) + Vvk
H = δh / δx (用X~k 代 Xk)
V = δh / δv (用X~k 代 Xk)
令:Z~k = h(X~k,0)
整理,得到:
Xk = X~k + J (Xk - X^k-1) + Wkwk-1
Zk = Z~k + H (Xk - X~k) + Vvk
p(w) ~ N(0,Q)
p(Ww) ~ N(0,WQWT)
预测:
X-k = f( X^k-1 , uk-1,0)
P-k= A Pk-1AT + WQWT
矫正:
Kk = P-k HT / (HP-kHT + VRVT)
X^k = X-k + Kk(Zk - h(X-k,0))
Pk = (I - KkH) P-k

 浙公网安备 33010602011771号
浙公网安备 33010602011771号