

尝试理解神经网络训练过程
神经网络基本原理: https://www.cnblogs.com/ms-uap/p/9928254.html#4150272
梯度下降概念: https://www.cnblogs.com/ms-uap/p/9945871.html
损失函数和最小二乘:https://www.cnblogs.com/ms-uap/p/9983758.html
在上一次,https://www.cnblogs.com/pylblog/p/10345255.html
仅仅在原函数的基础上,使用了一个“假的”梯度下降方法

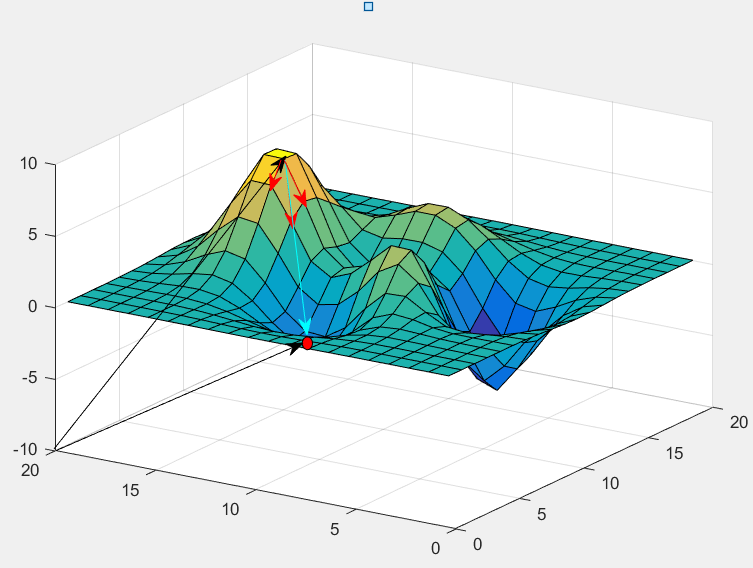
图中三个箭头,代表w1,w2方向,在“山顶”处,沿各自方向的斜率;红点是山底;
红色箭头的长度,代表下降速度。
(w1,或w2方向走同样的距离,Z的下降速度显然不同)
如果按上一篇的说法,求解△w1 = △Z / (dZ / dw1);但是仅仅限于,明确知道△Z的情况下,而且没有考虑,有没有一下子,在W1方向跨过了最低点(如图,顶点的下山速度是比较慢的,中间比较快,会导致w1方向一下子跑过了);
梯度下降,其实是:
w1 = w1 - a * dZ / dw1;
也就是△w1 = a * dZ / dw1;
和之前的求法,不需要除以斜率,为什么?
***
这里,是和上一篇的重要分割点,上一篇只讨论到平面曲线,通过X = X + △X,△Y / △X = dY / dX,△Y = Y - Y估计值,来迭代解△X,以用来说明,通过(“损失值” = 已知样本值Y - 估计值Y'),是可以通过求导数,通过“反向传播”,来迭代解X的。
而这里,原函数不再是Y = X*X,“损失值”不再是Y-Y' 。原函数是线性函数 Z = WX + b ,而损失函数,要以空间向量的(Z1,Z2,.......),(Z1',Z2',......)为数据源来衡量,无论从变量的维度,或是样本的数量都不一样。
无论如何,能得到一个十分重要的结论:计算机实际解决数学问题,特别是求参数,都是要将原函数,转化为可使用迭代求解的方式来求参数,通过将参数代回原函数,求收敛来结束
***
假设并不知道山脚的位置,只能沿蓝色箭头方向,走一小段距离,b;
分到w1方向,肯定是dZ/dw1 * a
分到w2方向,肯定是dZ/dw2 * a
a是一个常数;
梯度下降跟神经网络的关系:
假设样本:
样本1:
(x1,x2,......Y),(x1,x2,......Y),……
样本2:
(x1,x2,......Y),(x1,x2,......Y),……
(与以往不同的是,每个样本都是集合)
那么,使用一个样本来训练数据:
神经网络有函数:z = w1*x1+w2*x2+……+b;
假设激活函数:A = σ (z) = z;
那么损失函数:loss = 1 / 2 * Σ(z - y)² / m
(这里可以看出,loss是一个三维曲面,其参数是w1,w2,b,那么使用迭代更新的办法,当loss达到一定小的时候,即可);
(loss其实就是中误差,要不断达到均方差最小,和最小二乘法的目标是一致的。乘以0.5其实就是为了求导消除系数2);
(loss函数不止使用均方差(MSE)来衡量。如果将样本数据的值,看成向量(Y1,Y2,Y3,........),而激活函数值(Z1,Z2,Z3,......), MSE实际上就是求空间两点的距离,还有类似求空间夹角,https://www.cnblogs.com/pylblog/p/8352910.html)
dloss/dwi = Σ[(z-y) *1 * xi] / m;
wi = wi - a * dloss/dwi

模拟数据:y = 0.3 * x1 + 0.7 * x2 + 1 初始值:W1=0.22500,W2=0.52500 b=0.75000 步长:a=0.01000 样本一: X1=0 X2=0 Y=0.9980 Error=-0.0020 X1=0 X2=1 Y=1.7340 Error=0.0340 X1=0 X2=2 Y=2.4800 Error=0.0800 X1=0 X2=3 Y=3.1830 Error=0.0830 X1=0 X2=4 Y=3.7840 Error=-0.0160 X1=0 X2=5 Y=4.4740 Error=-0.0260 X1=1 X2=0 Y=1.3150 Error=0.0150 X1=1 X2=1 Y=2.0550 Error=0.0550 X1=1 X2=2 Y=2.7850 Error=0.0850 X1=1 X2=3 Y=3.4930 Error=0.0930 X1=1 X2=4 Y=4.0540 Error=-0.0460 X1=1 X2=5 Y=4.8780 Error=0.0780 X1=2 X2=0 Y=1.6170 Error=0.0170 X1=2 X2=1 Y=2.2090 Error=-0.0910 X1=2 X2=2 Y=3.0610 Error=0.0610 X1=2 X2=3 Y=3.7810 Error=0.0810 X1=2 X2=4 Y=4.3460 Error=-0.0540 X1=2 X2=5 Y=5.0740 Error=-0.0260 X1=3 X2=0 Y=1.8840 Error=-0.0160 X1=3 X2=1 Y=2.5180 Error=-0.0820 X1=3 X2=2 Y=3.3740 Error=0.0740 X1=3 X2=3 Y=4.0340 Error=0.0340 X1=3 X2=4 Y=4.7760 Error=0.0760 X1=3 X2=5 Y=5.4050 Error=0.0050 X1=4 X2=0 Y=2.2650 Error=0.0650 X1=4 X2=1 Y=2.9460 Error=0.0460 X1=4 X2=2 Y=3.5980 Error=-0.0020 X1=4 X2=3 Y=4.3790 Error=0.0790 X1=4 X2=4 Y=4.9210 Error=-0.0790 X1=4 X2=5 Y=5.7370 Error=0.0370 X1=5 X2=0 Y=2.4170 Error=-0.0830 X1=5 X2=1 Y=3.1260 Error=-0.0740 X1=5 X2=2 Y=3.8540 Error=-0.0460 X1=5 X2=3 Y=4.6320 Error=0.0320 X1=5 X2=4 Y=5.2610 Error=-0.0390 X1=5 X2=5 Y=5.9220 Error=-0.0780 迭代次数:245 w1 = 0.32104,w2 = 0.72978,b=0.84882,loss=0.01000 样本二: X1=0 X2=6 Y=5.2040 Error=0.0040 X1=0 X2=7 Y=5.8520 Error=-0.0480 X1=0 X2=8 Y=6.6460 Error=0.0460 X1=0 X2=9 Y=7.2130 Error=-0.0870 X1=0 X2=10 Y=7.9690 Error=-0.0310 X1=0 X2=11 Y=8.6050 Error=-0.0950 X1=1 X2=6 Y=5.4760 Error=-0.0240 X1=1 X2=7 Y=6.2240 Error=0.0240 X1=1 X2=8 Y=6.8420 Error=-0.0580 X1=1 X2=9 Y=7.5310 Error=-0.0690 X1=1 X2=10 Y=8.2230 Error=-0.0770 X1=1 X2=11 Y=9.0830 Error=0.0830 X1=2 X2=6 Y=5.8110 Error=0.0110 X1=2 X2=7 Y=6.5500 Error=0.0500 X1=2 X2=8 Y=7.2400 Error=0.0400 X1=2 X2=9 Y=7.8270 Error=-0.0730 X1=2 X2=10 Y=8.6410 Error=0.0410 X1=2 X2=11 Y=9.3170 Error=0.0170 X1=3 X2=6 Y=6.1740 Error=0.0740 X1=3 X2=7 Y=6.7880 Error=-0.0120 X1=3 X2=8 Y=7.5260 Error=0.0260 X1=3 X2=9 Y=8.2060 Error=0.0060 X1=3 X2=10 Y=8.8250 Error=-0.0750 X1=3 X2=11 Y=9.5140 Error=-0.0860 X1=4 X2=6 Y=6.3420 Error=-0.0580 X1=4 X2=7 Y=7.0910 Error=-0.0090 X1=4 X2=8 Y=7.8550 Error=0.0550 X1=4 X2=9 Y=8.5040 Error=0.0040 X1=4 X2=10 Y=9.2090 Error=0.0090 X1=4 X2=11 Y=9.8170 Error=-0.0830 X1=5 X2=6 Y=6.6300 Error=-0.0700 X1=5 X2=7 Y=7.3650 Error=-0.0350 X1=5 X2=8 Y=8.1940 Error=0.0940 X1=5 X2=9 Y=8.8710 Error=0.0710 X1=5 X2=10 Y=9.4700 Error=-0.0300 X1=5 X2=11 Y=10.2620 Error=0.0620 迭代次数:4 w1 = 0.31666,w2 = 0.71543,b=0.84728,loss=0.00742 样本三: X1=6 X2=0 Y=2.8250 Error=0.0250 X1=6 X2=1 Y=3.4760 Error=-0.0240 X1=6 X2=2 Y=4.1120 Error=-0.0880 X1=6 X2=3 Y=4.8990 Error=-0.0010 X1=6 X2=4 Y=5.5920 Error=-0.0080 X1=6 X2=5 Y=6.2110 Error=-0.0890 X1=7 X2=0 Y=3.0420 Error=-0.0580 X1=7 X2=1 Y=3.8140 Error=0.0140 X1=7 X2=2 Y=4.4140 Error=-0.0860 X1=7 X2=3 Y=5.1510 Error=-0.0490 X1=7 X2=4 Y=5.9190 Error=0.0190 X1=7 X2=5 Y=6.6010 Error=0.0010 X1=8 X2=0 Y=3.4300 Error=0.0300 X1=8 X2=1 Y=4.0850 Error=-0.0150 X1=8 X2=2 Y=4.7290 Error=-0.0710 X1=8 X2=3 Y=5.5040 Error=0.0040 X1=8 X2=4 Y=6.2700 Error=0.0700 X1=8 X2=5 Y=6.8610 Error=-0.0390 X1=9 X2=0 Y=3.7710 Error=0.0710 X1=9 X2=1 Y=4.4620 Error=0.0620 X1=9 X2=2 Y=5.0910 Error=-0.0090 X1=9 X2=3 Y=5.8280 Error=0.0280 X1=9 X2=4 Y=6.5580 Error=0.0580 X1=9 X2=5 Y=7.2050 Error=0.0050 X1=10 X2=0 Y=4.0470 Error=0.0470 X1=10 X2=1 Y=4.6510 Error=-0.0490 X1=10 X2=2 Y=5.4460 Error=0.0460 X1=10 X2=3 Y=6.0970 Error=-0.0030 X1=10 X2=4 Y=6.7140 Error=-0.0860 X1=10 X2=5 Y=7.4160 Error=-0.0840 X1=11 X2=0 Y=4.3350 Error=0.0350 X1=11 X2=1 Y=5.0010 Error=0.0010 X1=11 X2=2 Y=5.6310 Error=-0.0690 X1=11 X2=3 Y=6.3650 Error=-0.0350 X1=11 X2=4 Y=7.1480 Error=0.0480 X1=11 X2=5 Y=7.8610 Error=0.0610 迭代次数:2 w1 = 0.31507,w2 = 0.71472,b=0.84711,loss=0.00486 样本四: X1=6 X2=0 Y=2.8250 Error=0.0250 X1=6 X2=1 Y=3.4760 Error=-0.0240 X1=6 X2=2 Y=4.1120 Error=-0.0880 X1=6 X2=3 Y=4.8990 Error=-0.0010 X1=6 X2=4 Y=5.5920 Error=-0.0080 X1=6 X2=5 Y=6.2110 Error=-0.0890 X1=7 X2=0 Y=3.0420 Error=-0.0580 X1=7 X2=1 Y=3.8140 Error=0.0140 X1=7 X2=2 Y=4.4140 Error=-0.0860 X1=7 X2=3 Y=5.1510 Error=-0.0490 X1=7 X2=4 Y=5.9190 Error=0.0190 X1=7 X2=5 Y=6.6010 Error=0.0010 X1=8 X2=0 Y=3.4300 Error=0.0300 X1=8 X2=1 Y=4.0850 Error=-0.0150 X1=8 X2=2 Y=4.7290 Error=-0.0710 X1=8 X2=3 Y=5.5040 Error=0.0040 X1=8 X2=4 Y=6.2700 Error=0.0700 X1=8 X2=5 Y=6.8610 Error=-0.0390 X1=9 X2=0 Y=3.7710 Error=0.0710 X1=9 X2=1 Y=4.4620 Error=0.0620 X1=9 X2=2 Y=5.0910 Error=-0.0090 X1=9 X2=3 Y=5.8280 Error=0.0280 X1=9 X2=4 Y=6.5580 Error=0.0580 X1=9 X2=5 Y=7.2050 Error=0.0050 X1=10 X2=0 Y=4.0470 Error=0.0470 X1=10 X2=1 Y=4.6510 Error=-0.0490 X1=10 X2=2 Y=5.4460 Error=0.0460 X1=10 X2=3 Y=6.0970 Error=-0.0030 X1=10 X2=4 Y=6.7140 Error=-0.0860 X1=10 X2=5 Y=7.4160 Error=-0.0840 X1=11 X2=0 Y=4.3350 Error=0.0350 X1=11 X2=1 Y=5.0010 Error=0.0010 X1=11 X2=2 Y=5.6310 Error=-0.0690 X1=11 X2=3 Y=6.3650 Error=-0.0350 X1=11 X2=4 Y=7.1480 Error=0.0480 X1=11 X2=5 Y=7.8610 Error=0.0610 迭代次数:2 w1 = 0.31416,w2 = 0.71420,b=0.84702,loss=0.00388 最终:W1 = 0.31416,W2 = 0.71420,b=0.84702
static void Main(string[] args) { // Console.WriteLine("模拟数据:y = 0.3 * x1 + 0.7 * x2 + 1 "); // // var sample1 = GetSamples(0, 0, 6, 6); var sample2 = GetSamples(0, 6, 6, 12); var sample3 = GetSamples(6, 0, 12, 6); var sample4 = GetSamples(6, 6, 12, 12); var errors = Errors(sample1.Length + sample2.Length + sample3.Length + sample4.Length); // int index = 0; SetErrors(sample1, errors, ref index); SetErrors(sample2, errors, ref index); SetErrors(sample3, errors, ref index); SetErrors(sample4, errors, ref index); // double W1 = 0.3 * 0.75, W2 = 0.7 * 0.75, b = 0.75, a = 0.01; // Console.WriteLine("\r\n初始值:W1={0:F5},W2={1:F5} b={2:F5}", W1, W2, b); Console.WriteLine("步长:a={0:F5}", a); // Console.WriteLine("\r\n样本一:"); Train(sample1, ref W1, ref W2, ref b, a); // Console.WriteLine("\r\n样本二:"); Train(sample2, ref W1, ref W2, ref b, a); // Console.WriteLine("\r\n样本三:"); Train(sample3, ref W1, ref W2, ref b, a); // Console.WriteLine("\r\n样本四:"); Train(sample3, ref W1, ref W2, ref b, a); // Console.WriteLine("\r\n最终:W1 = {0:F5},W2 = {1:F5},b={2:F5}", W1, W2, b); // Console.ReadKey(); } private static void SetErrors(p[] sample1, double[] errors, ref int index) { for (int i = 0; i < sample1.Length; i++, index++) { sample1[i].Error = errors[index]; sample1[i].Y += sample1[i].Error; } } // private static void Train(p[] ps, ref double W1, ref double W2, ref double b, double a) { // foreach (var pp in ps) { Console.WriteLine("X1={0} X2={1} Y={2:F4} Error={3:F4}", pp.X1, pp.X2, pp.Y, pp.Error); } // double loss = 1; int inter = 1; while (loss > 0.01) { double dW1 = 0; double dW2 = 0; double db = 0; loss = 0; for (int i = 0; i < ps.Length; i++) { var z = W1 * ps[i].X1 + W2 * ps[i].X2 + b; var l = z - ps[i].Y; loss += l * l; dW1 += l * 1 * ps[i].X1; dW2 += l * 1 * ps[i].X2; db += l * 1; } //使用传统的求均方差 loss = loss / ps.Length; dW1 = dW1 / 2 / ps.Length; dW2 = dW2 / 2 / ps.Length; db = db / 2 / ps.Length; // //loss = loss / ps.Count / 2; //dW1 = dW1 / ps.Count; //dW2 = dW2 / ps.Count; //db = db / ps.Count; // W1 -= a * dW1; W2 -= a * dW2; b -= a * db; // inter++; // } Console.WriteLine("迭代次数:" + inter); Console.WriteLine("w1 = {0:F5},w2 = {1:F5},b={2:F5},loss={3:F5}", W1, W2, b, loss); } // private static p[] GetSamples(int minX, int minY, int maxX, int maxY) { var ps = new p[(maxX - minX) * (maxY - minY)]; for (int i = minX, count = 0; i < maxX; i++) { for (int j = minY; j < maxY; j++) { // ps[count++] = new p() { X1 = i, X2 = j, Y = 0.3 * i + 0.7 * j + 1 }; } } return ps; } /// <summary> /// 获取一组不重复的随机小数 /// </summary> /// <param name="count"></param> /// <returns></returns> static double[] Errors(int count) { Random r = new Random(); double[] errors = new double[count]; for (int i = 0; i < count; i++) { while (true) { errors[i] = (r.NextDouble() > 0.5 ? 1 : -1) * r.Next(0, 100) * 0.001; bool repeat = false; for (int j = 0; j < i; j++) { //10个数字内不能重复 if (errors[j] == errors[i] && i - j < 10) { repeat = true; break; } } if (repeat == false) { break; } } } return errors; } // } class p { public double X1 { get; set; } public double X2 { get; set; } public double Y { get; set; } public double Error { get; set; } }
经过试验,发现loss,a严重影响迭代次数,loss阈值,最好不要小于随机误差。
如果a过大,有导致不收敛现象;
如果随机误差是0.1~0.01,那么loss和a阈值就为0.01。
最重要一点就是,随机误差 / 样本Y 越小(样本真值1000,误差0.001,误差都可以快忽略不计了),w1,w2,b的还原度越高。
那么其实loss可以设置得更小(拟合的误差更小),a更大(拟合的速度更快)都可以。
总的来看,样本数据质量越好,拟合越佳;
//
以下下是另一波设置:
将loss除以10,即精度要求更高;
将随机误差error除以10,即数据质量更好;
改变a(实际中,步长不要轻易改变,变大可能不收敛,变小迭代可能更多次)
初始值:W1=0.22500,W2=0.52500 b=0.50000 步长:a=0.00100 随机误差: error=0.00010 loss阈值: 0.00100 样本一: 迭代次数:20155 w1 = 0.31195,w2 = 0.71082,b=0.93036,loss=0.00100 样本二: 迭代次数:23 w1 = 0.31061,w2 = 0.70726,b=0.92997,loss=0.00099 样本三: 迭代次数:11 w1 = 0.30916,w2 = 0.70678,b=0.92982,loss=0.00099 样本四: 迭代次数:2 w1 = 0.30905,w2 = 0.70674,b=0.92981,loss=0.00093 最终:W1 = 0.30905,W2 = 0.70674,b=0.92981 总迭代次数:20191
初始值:W1=0.22500,W2=0.52500 b=0.50000 步长:a=0.01000 随机误差: error=0.00010 loss阈值: 0.00100 样本一: 迭代次数:2015 w1 = 0.31094,w2 = 0.71132,b=0.93140,loss=0.00100 样本二: 迭代次数:4 w1 = 0.30917,w2 = 0.70643,b=0.93087,loss=0.00079 样本三: 迭代次数:3 w1 = 0.30723,w2 = 0.70574,b=0.93067,loss=0.00051 样本四: 迭代次数:2 w1 = 0.30682,w2 = 0.70557,b=0.93063,loss=0.00032 最终:W1 = 0.30682,W2 = 0.70557,b=0.93063 总迭代次数:2024
初始值:W1=0.22500,W2=0.52500 b=0.50000 步长:a=0.04000 随机误差: error=0.00010 loss阈值: 0.00100 样本一: 迭代次数:503 w1 = 0.31196,w2 = 0.71266,b=0.92561,loss=0.00100 样本二: 迭代次数:5 w1 = 0.30873,w2 = 0.70728,b=0.92517,loss=0.00068 样本三: 迭代次数:2 w1 = 0.30527,w2 = 0.70598,b=0.92482,loss=0.00072 样本四: 迭代次数:2 w1 = 0.30762,w2 = 0.70640,b=0.92513,loss=0.00047 最终:W1 = 0.30762,W2 = 0.70640,b=0.92513 总迭代次数:512
初始值:W1=0.22500,W2=0.52500 b=0.50000 步长:a=0.05000 随机误差: error=0.00010 loss阈值: 0.00100 样本一: 迭代次数:403 w1 = 0.31253,w2 = 0.71132,b=0.92852,loss=0.00100 样本二: 迭代次数:12229 w1 = NaN,w2 = NaN,b=NaN,loss=NaN 样本三: 迭代次数:2 w1 = NaN,w2 = NaN,b=NaN,loss=NaN 样本四: 迭代次数:2 w1 = NaN,w2 = NaN,b=NaN,loss=NaN 最终:W1 = NaN,W2 = NaN,b=NaN 总迭代次数:12636
另外设置初值:
初始值:W1=0.03000,W2=0.07000 b=0.05000 步长:a=0.00100 随机误差: error=0.00010 loss阈值: 0.00010 样本一: 迭代次数:41463 w1 = 0.30282,w2 = 0.70276,b=0.98260,loss=0.00010 样本二: 迭代次数:18 w1 = 0.30259,w2 = 0.70207,b=0.98253,loss=0.00010 样本三: 迭代次数:10 w1 = 0.30227,w2 = 0.70197,b=0.98250,loss=0.00010 样本四: 迭代次数:2 w1 = 0.30224,w2 = 0.70196,b=0.98249,loss=0.00010 最终:W1 = 0.30224,W2 = 0.70196,b=0.98249 总迭代次数:41493
初始值离谱一些,迭代次数自然高。
适当提高a:
初始值:W1=0.03000,W2=0.07000 b=0.05000
步长:a=0.01000
随机误差: error=0.00010
loss阈值: 0.00010
样本一:
迭代次数:4027
w1 = 0.30278,w2 = 0.70351,b=0.98056,loss=0.00010
样本二:
迭代次数:4
w1 = 0.30228,w2 = 0.70200,b=0.98040,loss=0.00009
样本三:
迭代次数:2
w1 = 0.30212,w2 = 0.70193,b=0.98039,loss=0.00007
样本四:
迭代次数:2
w1 = 0.30202,w2 = 0.70188,b=0.98038,loss=0.00006
最终:W1 = 0.30202,W2 = 0.70188,b=0.98038
总迭代次数:4035
总结:利用梯度下降求解参数,1. 数据质量要够好(误差够小);2. 步长a要适中, 应该要实际测试才知道,根据初始值,和数据质量评判,a能确定是否收敛和迭代速度
;3. loss也要根据数据质量评判,loss决定收敛速度以及参数还原度。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 25岁的心里话
· 按钮权限的设计及实现
2018-02-01 学习笔记68_朴素贝叶斯分类