redis数据库基础篇
一、Redis介绍
Redis 是一个高性能的key-value数据格式的内存缓存,NoSQL数据库。NOSQL:not only sql,泛指非关系型数据库。关系型数据库: (mysql, oracle, sql server, sqlite)
1. 数据存放在表中,表之间有关系。 2. 通用的SQL操作语言。 3. 大部分支持事务。
非关系型数据库[ redis,hadoop,mangoDB]:
1. 没有数据表的概念,不同的nosql数据库存放数据位置不同。 2. nosql数据库没有通用的操作语言。 3. 基本不支持事务。 redis支持简单事务
redis是业界主流的key-value nosql 数据库之一。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。redis是一款基于CS架构的数据库,所以redis有客户端,也有服务端。
Redis优点
- 异常快速 : Redis是非常快的,每秒可以执行大约110000设置操作,81000个/每秒的读取操作。
- 支持丰富的数据类型 : Redis支持最大多数开发人员已经知道如列表,集合,可排序集合,哈希等数据类型。
- 原子 – Redis的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过MULTI和EXEC指令包起来。
- Redis是一个多功能实用工具,可以在很多如,消息传递队列中使用(Redis原生支持发布/订阅)
- 单线程特性,秒杀系统,基于redis是单线程特征,防止出现数据库“爆破”
redis的典型应用
(一)性能
Redis 中缓存热点数据,能够保护数据库,提高查询效率。如下图所示,我们在碰到需要执行耗时特别久,且结果不频繁变动的SQL,就特别适合将运行结果放入缓存。这样,后面的请求就去缓存中读取,使得请求能够迅速响应。
(二)并发
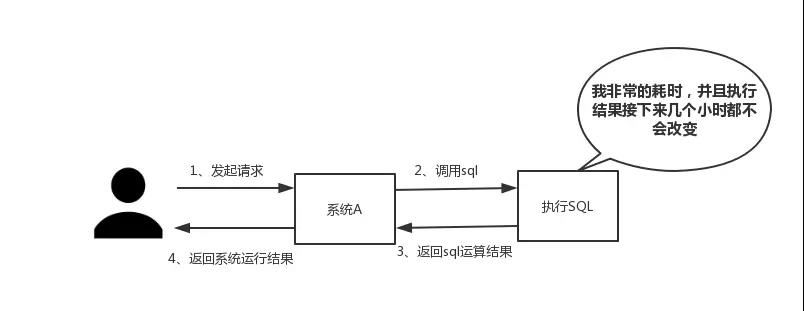
还是如上图所示,在大并发的情况下,所有的请求直接访问数据库,数据库会出现连接异常。这个时候,就需要使用redis做一个缓冲操作,让请求先访问到redis,而不是直接访问数据库。
安装Redis环境
$sudo apt-get update $sudo apt-get install redis-server
启动 Redis
$redis-server
查看 redis 是否还在运行
$redis-cli
redis 127.0.0.1:6379>
redis 127.0.0.1:6379> ping PONG
二、Python操作Redis
redis-py 的API的使用可以分类为:
- 连接方式
- 操作
- String 操作
- Hash 操作
- List 操作
- Set 操作
- Sort Set 操作
- 管道
- 发布订阅
2.1、连接方式
1、操作模式
redis-py提供两个类Redis和StrictRedis用于实现Redis的命令,StrictRedis用于实现大部分官方的命令,并使用官方的语法和命令,Redis是StrictRedis的子类,用于向后兼容旧版本的redis-py。
import redis
r = redis.Redis(host='10.211.55.4', port=6379)
r.set('foo', 'Bar')
print r.get('foo')
2、连接池
redis-py使用connection pool来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。默认,每个Redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接池。
import redis
pool = redis.ConnectionPool(host='10.211.55.4', port=6379)
r = redis.Redis(connection_pool=pool)
r.set('foo', 'Bar')
print r.get('foo')
2.2、操作
1. string类型: 字符串类型是 Redis 中最为基础的数据存储类型,它在 Redis 中是二进制安全的,也就是byte类型 最大容量是512M。 2. hash类型: hash用于存储对象,对象的结构为属性、值,值的类型为string。 key:{ 域:值[这里的值只能是字符串], 域:值, 域:值, 域:值, ... } 3. list类型: 列表的元素类型为string。 key:[ 值1,值2,值3..... ] 4. set类型: 无序集合,元素为string类型,元素唯一不重复,没有修改操作。 {值1,值4,值3,值5} 5. zset类型: 有序集合,元素为string类型,元素唯一不重复,没有修改操作。
2.2.1、String 操作
redis中的String在在内存中按照一个name对应一个value来存储。如图:

set(name, value, ex=None, px=None, nx=False, xx=False)
在Redis中设置值,默认,不存在则创建,存在则修改
参数:
ex,过期时间(秒)
px,过期时间(毫秒)
nx,如果设置为True,则只有name不存在时,当前set操作才执行
xx,如果设置为True,则只有name存在时,岗前set操作才执行
setnx(name, value)
设置值,只有name不存在时,执行设置操作(添加)
setex(name, value, time)
# 设置值
# 参数:
# time,过期时间(数字秒 或 timedelta对象)
psetex(name, time_ms, value)
# 设置值
# 参数:
# time_ms,过期时间(数字毫秒 或 timedelta对象)
mset(*args, **kwargs)
批量设置值
如:
mset(k1='v1', k2='v2')
或
mget({'k1': 'v1', 'k2': 'v2'})
get(name)
获取值
mget(keys, *args)
批量获取
如:
mget('ylr', 'wupeiqi')
或
r.mget(['ylr', 'wupeiqi'])
getset(name, value)
设置新值并获取原来的值
getrange(key, start, end)
# 获取子序列(根据字节获取,非字符)
# 参数:
# name,Redis 的 name
# start,起始位置(字节)
# end,结束位置(字节)
setrange(name, offset, value)
# 修改字符串内容,从指定字符串索引开始向后替换(新值太长时,则向后添加)
# 参数:
# offset,字符串的索引,字节(一个汉字三个字节)
# value,要设置的值
strlen(name)
# 返回name对应值的字节长度(一个汉字3个字节)
incr(self, name, amount=1)
# 自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。
# 参数:
# name,Redis的name
# amount,自增数(必须是整数)
# 注:同incrby
incrbyfloat(self, name, amount=1.0)
# 自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。
# 参数:
# name,Redis的name
# amount,自增数(浮点型)
decr(self, name, amount=1)
# 自减 name对应的值,当name不存在时,则创建name=amount,否则,则自减。
# 参数:
# name,Redis的name
# amount,自减数(整数)
append(key, value)
# 在redis name对应的值后面追加内容
# 参数:
key, redis的name
value, 要追加的字符串
2.2.2、Hash 操作
hash表现形式上有些像pyhton中的dict,可以存储一组关联性较强的数据 , redis中Hash在内存中的存储格式如下图:

hset(name, key, value)
# name对应的hash中设置一个键值对(不存在,则创建;否则,修改)
# 参数:
# name,redis的name
# key,name对应的hash中的key
# value,name对应的hash中的value
# 注:
# hsetnx(name, key, value),当name对应的hash中不存在当前key时则创建(相当于添加)
hmset(name, mapping)
# 在name对应的hash中批量设置键值对
# 参数:
# name,redis的name
# mapping,字典,如:{'k1':'v1', 'k2': 'v2'}
# 如:
# r.hmset('xx', {'k1':'v1', 'k2': 'v2'})
hget(name,key)
# 在name对应的hash中获取根据key获取value
hmget(name, keys, *args)
# 在name对应的hash中获取多个key的值
# 参数:
# name,reids对应的name
# keys,要获取key集合,如:['k1', 'k2', 'k3']
# *args,要获取的key,如:k1,k2,k3
# 如:
# r.mget('xx', ['k1', 'k2'])
# 或
# print r.hmget('xx', 'k1', 'k2')
hgetall(name)
# 获取name对应hash的所有键值
hlen(name)
# 获取name对应的hash中键值对的个数
hkeys(name)
# 获取name对应的hash中所有的key的值
hvals(name)
# 获取name对应的hash中所有的value的值
hexists(name, key)
# 检查name对应的hash是否存在当前传入的key
hdel(name,*keys)
# 将name对应的hash中指定key的键值对删除
hincrby(name, key, amount=1)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount
# 参数:
# name,redis中的name
# key, hash对应的key
# amount,自增数(整数)
hincrbyfloat(name, key, amount=1.0)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount
# 参数:
# name,redis中的name
# key, hash对应的key
# amount,自增数(浮点数)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount
hscan_iter(name, match=None, count=None)
# 利用yield封装hscan创建生成器,实现分批去redis中获取数据
# 参数:
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
# 如:
# for item in r.hscan_iter('xx'):
# print item
2.2.3、List 操作
List操作,redis中的List在在内存中按照一个name对应一个List来存储。如图:

lpush(name,values)
# 在name对应的list中添加元素,每个新的元素都添加到列表的最左边
# 如:
# r.lpush('oo', 11,22,33)
# 保存顺序为: 33,22,11
# 扩展:
# rpush(name, values) 表示从右向左操作
lpushx(name,value)
# 在name对应的list中添加元素,只有name已经存在时,值添加到列表的最左边
# 更多:
# rpushx(name, value) 表示从右向左操作
llen(name)
# name对应的list元素的个数
linsert(name, where, refvalue, value))
# 在name对应的列表的某一个值前或后插入一个新值
# 参数:
# name,redis的name
# where,BEFORE或AFTER
# refvalue,标杆值,即:在它前后插入数据
# value,要插入的数据
r.lset(name, index, value)
# 对name对应的list中的某一个索引位置重新赋值
# 参数:
# name,redis的name
# index,list的索引位置
# value,要设置的值
r.lrem(name, value, num)
# 在name对应的list中删除指定的值
# 参数:
# name,redis的name
# value,要删除的值
# num, num=0,删除列表中所有的指定值;
# num=2,从前到后,删除2个;
# num=-2,从后向前,删除2个
lpop(name)
# 在name对应的列表的左侧获取第一个元素并在列表中移除,返回值则是第一个元素
# 更多:
# rpop(name) 表示从右向左操作
lindex(name, index)
# 在name对应的列表中根据索引获取列表元素
lrange(name, start, end)
# 在name对应的列表分片获取数据
# 参数:
# name,redis的name
# start,索引的起始位置
# end,索引结束位置
ltrim(name, start, end)
# 在name对应的列表中移除没有在start-end索引之间的值
# 参数:
# name,redis的name
# start,索引的起始位置
# end,索引结束位置
2.2.4、Set 操作
Set操作,Set集合就是不允许重复的列表
sadd(name,values)
# name对应的集合中添加元素
scard(name)
# 获取name对应的集合中元素个数
sdiff(keys, *args)
# 在第一个name对应的集合中且不在其他name对应的集合的元素集合
sinter(keys, *args)
# 获取多一个name对应集合的交集
sismember(name, value)
# 检查value是否是name对应的集合的成员
smembers(name)
# 获取name对应的集合的所有成员
spop(name)
# 从集合中随机移除一个成员,并将其返回
srandmember(name, numbers)
# 从name对应的集合中随机获取 numbers 个元素
srem(name, values)
# 在name对应的集合中删除某些值
sunion(keys, *args)
# 获取多一个name对应的集合的并集
sscan_iter(name, match=None, count=None)
# 同字符串的操作,用于增量迭代分批获取元素,避免内存消耗太大
2.2.5、Sort Set 操作
有序集合,在集合的基础上,为每元素排序;元素的排序需要根据另外一个值来进行比较,所以,对于有序集合,每一个元素有两个值,即:值和分数,分数专门用来做排序。
zadd(name, *args, **kwargs)
# 在name对应的有序集合中添加元素
# 如:print(r.zadd("zz",{"n1":1,"n2":2,"n3":3,"n4":4}))
# 查看:print(r.zscan("zz"))
zcard(name)
# 获取name对应的有序集合元素的数量
zcount(name, min, max)
# 获取name对应的有序集合中分数 在 [min,max] 之间的个数
zincrby(name, value, amount)
# 自增name对应的有序集合的 name 对应的分数
zrange( name, start, end, desc=False, withscores=False, score_cast_func=float)
# 按照索引范围获取name对应的有序集合的元素 aa=r.zrange("zset_name",0,1,desc=False,withscores=True,score_cast_func=int) print(aa) '''参数: name redis的name start 有序集合索引起始位置 end 有序集合索引结束位置 desc 排序规则,默认按照分数从小到大排序 withscores 是否获取元素的分数,默认只获取元素的值 score_cast_func 对分数进行数据转换的函数'''
zscore(name, value)
#获取name对应有序集合中 value 对应的分数
zrank(name, value)
# 获取某个值在 name对应的有序集合中的排行(从 0 开始)
# 更多:
# zrevrank(name, value),从大到小排序
zrem(name, values)
# 删除name对应的有序集合中值是values的成员
# 如:zrem('zz', ['s1', 's2'])
zremrangebyrank(name, min, max)
# 根据排行范围删除
zremrangebyscore(name, min, max)
# 根据分数范围删除
zinterstore(dest, keys, aggregate=None)
# 获取两个有序集合的交集,如果遇到相同值不同分数,则按照aggregate进行操作 # aggregate的值为: SUM MIN MAX
zunionstore(dest, keys, aggregate=None)
# 获取两个有序集合的并集,如果遇到相同值不同分数,则按照aggregate进行操作 # aggregate的值为: SUM MIN MAX
2.2.6、其他常用操作
delete(*names)
# 根据删除redis中的任意数据类型
exists(name)
# 检测redis的name是否存在
keys(pattern='*')
# 根据模型获取redis的name
# 更多:
# KEYS * 匹配数据库中所有 key 。
# KEYS h?llo 匹配 hello , hallo 和 hxllo 等。
# KEYS h*llo 匹配 hllo 和 heeeeello 等。
# KEYS h[ae]llo 匹配 hello 和 hallo ,但不匹配 hillo
expire(name ,time)
# 为某个redis的某个name设置超时时间
rename(src, dst)
# 对redis的name重命名为
randomkey()
# 随机获取一个redis的name(不删除)
type(name)
# 获取name对应值的类型
scan_iter(match=None, count=None)
# 同字符串操作,用于增量迭代获取key
2.2.7、使用场景
针对各种数据类型使用场景如下:
(一)String
这个其实没啥好说的,最常规的set/get操作,value可以是String也可以是数字。一般做一些复杂的计数功能的缓存,比如减少库存。
(二)hash
这里value存放的是结构化的对象,比较方便的就是操作其中的某个字段。博主在做单点登录的时候,就是用这种数据结构存储用户信息,以cookieId作为key,设置30分钟为缓存过期时间,能很好的模拟出类似session的效果。
(三)list
使用List的数据结构,可以做简单的消息队列的功能。另外还有一个就是,可以利用lrange命令,做基于redis的分页功能,性能极佳,用户体验好。本人还用一个场景,很合适---取行情信息。就也是个生产者和消费者的场景。LIST可以很好的完成排队,先进先出的原则。
(四)set
因为set堆放的是一堆不重复值的集合。所以可以做全局去重的功能。
另外,就是利用交集、并集、差集等操作,可以计算共同喜好,全部的喜好,自己独有的喜好等功能。
(五)sorted set
sorted set多了一个权重参数score,集合中的元素能够按score进行排列。可以做排行榜应用,取TOP N操作。
2.3、管道
redis-py默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作,如果想要在一次请求中指定多个命令,则可以使用pipline实现一次请求指定多个命令,并且默认情况下一次pipline 是原子性操作。
import redis
pool = redis.ConnectionPool(host='10.211.55.4', port=6379)
r = redis.Redis(connection_pool=pool)
# pipe = r.pipeline(transaction=False)
pipe = r.pipeline(transaction=True)
pipe.set('name', 'alex')
pipe.set('role', 'sb')
pipe.execute()
2.4、发布订阅
订阅者:
import redis
r=redis.Redis(host='127.0.0.1')
pub=r.pubsub()
pub.subscribe("fm104.5")
pub.parse_response()
while 1:
msg = pub.parse_response()
print(msg)
发布者:
import redis
r=redis.Redis(host='127.0.0.1')
r.publish("fm104.5", "Hi,yuan!")
发布订阅的特性用来做一个简单的实时聊天系统再适合不过了,当然这样的东西开发中很少涉及到。再比如在分布式架构中,常常会遇到读写分离的场景,在写入的过程中,就可以使用redis发布订阅,使得写入值及时发布到各个读的程序中,就保证数据的完整一致性。再比如,在一个博客网站中,有100个粉丝订阅了你,当你发布新文章,就可以推送消息给粉丝们拉。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号