会员
周边
新闻
博问
闪存
众包
赞助商
Chat2DB
所有博客
当前博客
我的博客
我的园子
账号设置
会员中心
简洁模式
...
退出登录
注册
登录
哈哈哈喽喽喽
博客园
首页
新随笔
联系
订阅
管理
SSL
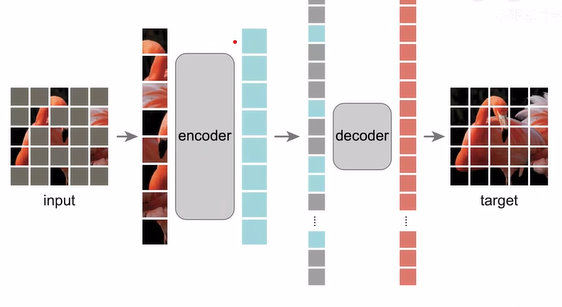
1、MAE
基于VIT,BERT自监督的算法引用到CV;主要思路是遮住大量的块,使用非对称的编码解码器(编码器看非mask块)
视觉和BERT不同点: 1.图片的信息密度高,仅mask部分像素,可以通过周围像素差值来获得,因此这里需要mask掉很大的比例 2、NLP还原的是词,因此通过简单的全连接就可以还原出词,图像还原到像素,因此需要比MLP复杂的解码器
实现细节
1、encoder和decoder不一样
2、不编码mask部分
3、mask掉75%patch
posted @
2022-12-19 08:57
哈哈哈喽喽喽
阅读(
43
) 评论(
0
)
收藏
举报
刷新页面
返回顶部
公告

 浙公网安备 33010602011771号
浙公网安备 33010602011771号