(BEV综述)Delving into the Devils of Bird’s-eye-view Perception: A Review, Evaluation and Recipe
0、Abstract
自驾特征融合背景:自驾传感器方案由复杂的多个摄像头,激光雷达,rada等组成, 而融合多个传感器输入到统一视图的表示特征至关重要
BEV感知实现特征融合好处:BEV特征表示是 融合好的和直观的(可以直接在规控中使用)
BEV感知核心问题:
- (a)如何通过透视视图到BEV的视图变换来重建丢失的三维信息
- (b)如何获取BEV网格中的Ground True注释
- (c)如何融合来自不同传感器和不同视角的特征
- (d)当传感器配置在不同场景中不同时如何适应和泛化算法
本文的主要分下面方面进行讲述: - 1、回顾最近BEV感知工作,并对不同的解决方案进行深入分析
- 2、BEV感知在业界系统设计
- 3、提高BEV感知任务的性能实用的指南,包括相机、激光雷达和彼此融合;
- 4、该领域未来的研究方向。
1、INTRODUCTION
- BEV表示的优势
- 不存在二维任务中普遍存在的遮挡和尺度问题,识别有遮挡或交叉交通的车辆可以得到更好的解决。
- BEV表示物体或道路元素将有利于后续模块(如规划、控制)的开发和部署
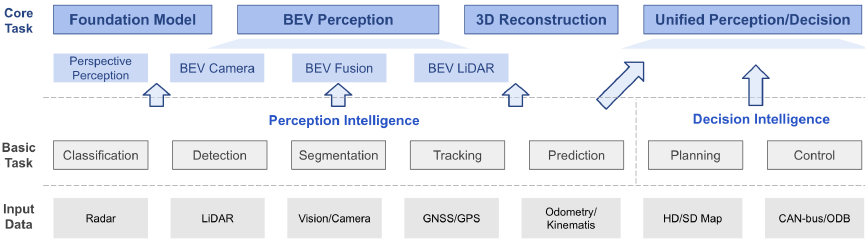
- BEV感知定义:处理BEV视图表示的视觉算法,算法主要是研究 如何更好的融合多传感器的输入 到BEV视图的方法/pipeline/框架
1.1、BEV感知划分
根据输入数据将BEV感知研究主要分为BEV相机、BEV激光雷达和BEV融合
BEV相机:指仅视觉或以视觉为中心的算法,利用多个周围摄像机进行三维物体检测或分割;
BEV LiDAR:指以点云为输入的检测或分割任务;
BEV融合:指融合来自多个传感器输入,如相机、激光雷达、GNSS、里程计、HD-Map、can总线等。
1.2、BEV感知研究动机
1.2.1 意义-是否会对学术界和工业界产生价值
- 1、基于相机/视觉的方案与基于激光雷达或融合的方案性能差距还很大,例如截至2022年8月提交,就nuScenes数据集上的NDS而言,排名第一的方法在仅视觉和LiDAR之间的差距超过20%;在Waymo基准上,差距甚至超过了30%,这促使研究视觉方案赶上或者超过激光雷达方法
- 2、从学术角度来看,设计一个基于相机的算法使其优于激光雷达方法,需要解决的问题是如何处理从二维的外观输入转换到三维的几何输出; 如何像在点云中那样将相机特征转换成3D几何表示形式对学术界有着重要的影响;
- 3、从工业角度考虑,激光雷达的成本通常是相机的10倍,激光雷达成本较高,设备制造商(如福特、宝马等)更喜欢廉价的软件算法,此外基于相机的算法可以识别远距离物体和道路元素(如红绿灯),这两者都是激光雷达方法所不能做到的
- 4、基于相机和雷达的有不同的方案,但是使用BEV表征是最好的方法之一,原因是1、激光雷达性能好,部署友好 2、相机和雷达可以投影到统一的BEV空间进行特征融合
1.2.2 空间-是否存在需要实质性创新的未决问题
- 问题一:从原始传感器输入进行深度估计,特别是对于相机分支(2D-3D)
BEV感知关键是从相机和激光雷达输入中学习健壮的和可泛化的特征表示。这在LiDAR分支中很容易,因为输入(点云)具有这样的3D属性,但在相机分支中从单目或多目相机输入中学习3D空间信息非常困难;BEV感知背后的核心问题需要从原始传感器输入进行深度估计的实质性创新,特别是对于相机分支,当前有一些尝试通过姿势估计或时间运动来学习更好的2D-3D对应关系 - 问题二:不同模态特征前/中融合
大多数传感器融合算法只是简单的做目标级融合(后融合)或cat特征拼接(简单的cat拼接),这也就是为什么融合算法的表现不如仅用激光雷达方法效果好,其主要由于相机和激光雷达之间的不对齐或不准确的深度预测;如何从多模态输入中对齐和整合特征是一个至关重要的问题,因此有广阔的创新空间
1.2.3 关键条件-(例如数据集、benchmark)是否准备好进行BEV感知研究?
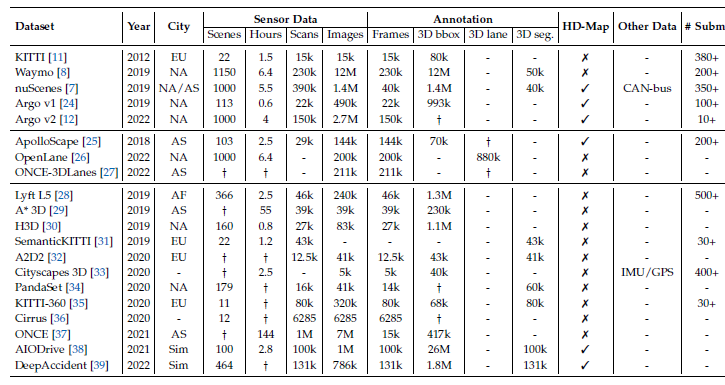
数据集、benchmark标注满足任务的评估,数据集包含高质量的2D和3D Object标注,2D和3DObject精确对齐是两个关键评估点;
- 1、KITTI数据集较为全面,在早期自动驾驶研究中备受关注
- 2、Waymo、nuScenes、Argoverse等大规模、多样化的基准为验证BEV感知算法提供了坚实的平台这些新提出的基准通常包括高质量的标签、场景多样性和大数据量,此外这些排行榜上的开放挑战提供了一个公平的设置,所有的算法都可以在开放和及时的意义上进行比较
1.3、贡献
- 1、回顾了近年来BEV感知研究的全貌,包括高水平的理论和深入细致的讨论。
- 2、对BEV感知文献进行了综合分析,涵盖了深度估计、视图变换、传感器融合、域自适应等核心问题,介绍和讨论了几种重要的BEV感知工业系统级设计。
- 3、除了理论贡献外还提供了一个实用的操作指南以提高在各种BEV感知任务中的表现。
2、BACKGROUND IN 3D PERCEPTION
包括 1、任务/算法:单目相机3D object detection、 基于LiDAR 3D object detection and segmentation、相机和激光雷达融合 2、数据集:KITTI、nuScenes、Waymo
2.1 任务/算法定义和相关工作
- 1、单目相机3D目标检测
定义:RGB图像作为输入,输出3D位置和类别
关键问题:RGB图像缺少深度信息,所以关键问题是预测深度。由于从单个图像估计深度是一个病态问题,通常基于单目相机的方法比基于LiDAR的方法性能差 - 2、基于LiDAR 3D object detection and segmentation
LiDAR在3D空间中使用一组点描述周围环境,这些点捕获对象的几何信息。即使缺乏颜色和纹理信息,以及有限的感知范围,基于LiDAR的方法由于深度先验而大大优于基于相机的方法 - 3、传感器融合
现代自动驾驶汽车配备了不同的传感器,如摄像头、激光雷达和雷达,每种传感器都有优缺点。相机数据包含密集的颜色和纹理信息,但无法捕获深度信息。激光雷达提供准确的深度和结构信息,但范围有限和稀疏。雷达比LiDAR更稀疏,但感知范围更长,可以从运动物体中捕获信息。理想情况下,传感器融合将提高感知系统的上限性能,但如何融合来自不同模式的数据仍然是一个具有挑战性的问题
2.2、数据集和指标
数据集包含重要的3D bounding box annotation and 3D segmentation annotation,新出的数据集也都包含 HD-Map configuration
-
KITTI:KITTI是2012年提出的一个开创性的自动驾驶数据集,它有7481张训练图像和7518张测试图像用于三维目标检测任务,它也有相应的从Velodyne激光扫描仪捕获的点云,测试集分为易、中、难3部分,主要根据bbox大小和遮挡程度进行划分,目标检测评估分为两类:三维目标检测评估和鸟瞰图目标检测评估。KITTI是第一个针对多个自动驾驶任务的综合数据集
-
Waymo:Waymo Open Dataset v1.3在训练集、验证集和测试集中分别包含798、202和80个视频序列,每个序列有5个激光雷达和侧左,前左,前,前右和侧右5个视图,图像分辨率为1920 × 1280像素或1920 × 886像素,Waymo规模庞大,种类多样,随着数据集版本的不断更新,它也在不断发展。每年Waymo开放挑战赛都会定义新的任务,并鼓励社区解决这些问题。
-
nuScenes:nuScenes数据集是一个大型自动驾驶数据集,包含了两个城市的1000个驾驶场景,850个场景用于训练验证,150个场景用于测试,每个场景有20s长,它有40k关键帧和整个传感器套件,包括6个摄像头,1个激光雷达和5个雷达,图像分辨率为1600 × 900,同时发布相应的HD-Map和CANbus数据,探讨多输入辅助,nuScenes由于提供了多样化的多传感器设置,在学术文献中越来越受欢迎,
数据规模没有Waymo的那么大,可以在这个基准上快速验证想法 -
Evaluation Metrics
3、BEV感知方法
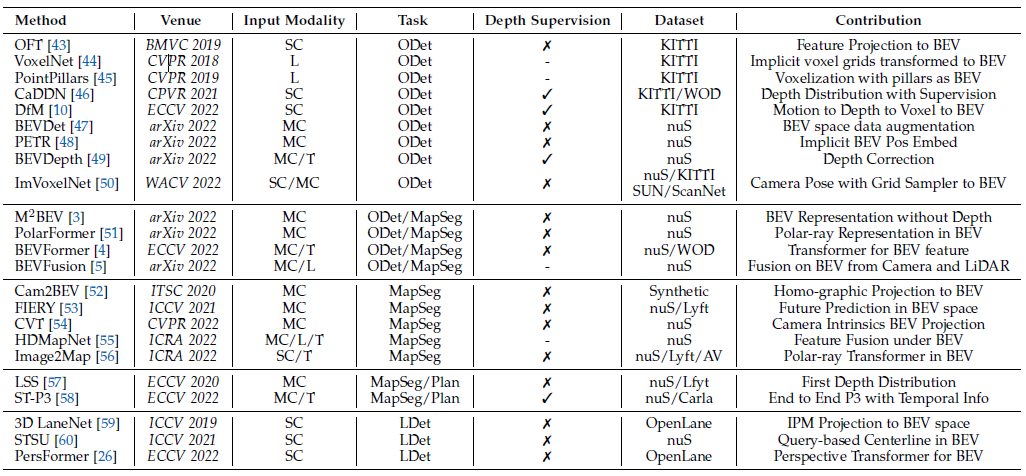
主要包括:1、学术界按照输入数据的模态分基于Camera BEV感知、基于LiDAR BEV感知、Camera和LiDAR融合的BEV感知 2、工业界BEV感知
下图按时间顺序总结了基于输入数据和任务类型的BEV感知文献分类,格列值含义:
Input Modality:“L” = LiDAR, “SC” = single camera, “MC” = multi camera, “T” = temporal information
Task: “ODet” = 3D object detection, “LDet” = 3D lane detection, “MapSeg” = map segmentation, “Plan” = motion planning, “MOT” = multi-object tracking
Depth Supervision:相机输入模型是否使用稀疏/密集深度图来监督模型,√使用深度监督,×不适用深度监督, -是雷达输入
Dataset:“nuS”=nuScenes, “WOD”=Waymo, “KITTI”=KITTI, “Lyft”=Lyft Level 5 Dataset, “OpenLane”=OpenLane , “AV”=Argoverse, “Carla”=carla simulator,“SUN”=SUN RGB-D, “ScanNet”=ScanNet indoor scenes
3.1、Camera BEV感知
3.1.1 通用pipeline
仅基于相机的3D感知与基于lidar的3D感知相比是一个仍未解决的问题,受到了学术界的广泛关注。其核心问题是二维图像不保留三维信息,当二维图像深度信息提取不准确时很难获得准确的目标三维定位,仅基于摄像头3D感知可分为三个方面:单摄像头设置、立体相机设置和多摄像头设置,它们处理深度问题的技巧各不相同
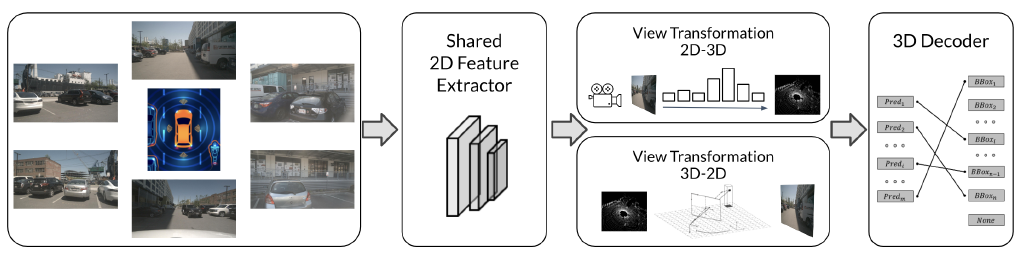
一般的单目相机3D感知系统可以分为三个部分:2D特征提取器、视图转换模块(可选)和3D解码器
- 2D特征提取器
可以表述为: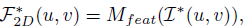
其中F表示二维特征,I表示图像,M表示二维特征提取器,u、v表示二维平面上的坐标,*表示一张或多张图像和相应的二维特征 - 视图转换(可选,有些3D感知方法是直接在2D特征做3D目标检测)
如上图所示进行视图转换一般有两种方式,一种是从三维空间到二维空间的转换,另一种是从二维空间到三维空间的转换,这两种方式都是利用三维空间中的物理先验或者利用三维监督,这样的转换可以表述为: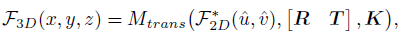
其中F表示3D(或体素)特征,x, y, z表示3D空间中的坐标,M表示视图转换模块, u,v表示x, y, z对应的2D坐标,[R、T]和K分别为相机外参和内参; - 3D解码器
三维解码器接收2D/3D空间的特征,输出三维边界框、BEV地图分割、3D线关键点等三维感知结果;
对做过特征视图变换的特征,大多数3D解码器来自基于LiDAR的方法,这些方法在体素空间/BEV空间中执行检测;
没有做视图变换的2D图像特征的3D解码器,利用2D空间中的特征并直接回归3D对象的定位。
3.1.2 2D特征提取器
在2D特征提取器中,在2D感知中存在大量的经验,这些经验可以在3D感知中以backbone预训练中使用
3.1.3 视图转换
视图转换是构建三维信息和编码三维先验假设的主要模块,主要分2种,一种2D-3D,利用2D特征生成深度信息将2D特征转3D特征;二是3D-2D,通过3D到2D的投影映射方法,采样2D特征来生成3D特征。给出了通过这两种方法执行视图转换的概要路线图,下面将对它们进行详细分析

3.1.3.1 2D->3D
- LSS
2D-3D方法是由LSS引入的,它预测2D特征上每个网格的深度分布,然后通过相应的深度把每个网格的2D特征“提升”到体素空间 ,并遵循基于lidar的方法执行下游任务,该过程可以表述为:
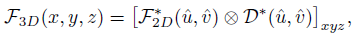
F3D表示3D(或体素)特征,x, y, z表示3D空间中的坐标,F2D表示2D特征,u,v表示x, y, z对应的2D坐标,D为u,v位置的预测的深度值/分布,x表示投影/相似度。
上面这个方法和由图片生成伪雷达方法不太一样,不同点在1、伪雷达的方法是在 生成2D特征之前,由预训练深度估计模型 生成深度信息,然后由图片+深度信息提升到3D(这个地方的深度图是每像素的深度信息?) - CaDDN
在LSS[57]之后,还有一项工作遵循了将深度公式化为逐仓分布的相同思想,即CaDDN[46]。CaDDN使用类似的网络来预测深度分布(分类深度分布),将体素空间特征压缩到BEV空间,并在最后执行3D检测。
LSS[57]和CaDDN[46]之间的主要区别在于,CaDDN使用深度GT来监督其确定的深度分布预测,因此从2D空间提取3D信息由优势。 - 双目相机
注意,当我们声称“一个更好的深度网络”时,它实际上是在学习一个在特征层面上的在路面和透视图之间的隐含投影。这一轨迹来自后续工作,如BEVDet[47]及其时间版本BEVDet4D[64]、BEVDepth[49]、BEVFusion[5、91]和其他[65、81、92]。注意,在立体设置中,通过假设相机对之间的距离(即系统的基线)是恒定的强先验,更容易获得深度值/分布,该过程可以表述为:
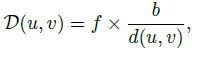
其中,D是u,v位置深度值,d是u,v位置处图像对的水平视差,f是摄像机的焦距,b是基线的长度。LIGA Stereo[92]和DSGN[65]等立体方法利用了这一强大的优势,在KITTI排行榜上的表现与基于LiDAR的替代方案不相上下
3.1.3.2 3D->2D
追溯到30年前,当时反向透视映射(IPM)提出了从3D空间到2D空间的投影;这个方法假设3D空间中的对应点位于水平面上,这样的变换矩阵可以由相机的内、外参数进行数学推导,之后一系列的工作应用IPM以预处理或后处理的方式将元素从透视视图转换为鸟瞰视图,
- OFTNet
最早提出2D特征到3D空间方法OFTNet,这是基于这样的假设:从相机原点到3D空间中的特定点,沿光线的深度分布是均匀的,这个驾驶适用于自动驾驶中的大多数场景,除了起伏不平的道路时
再之后许多BEV地图分割工作利用多层感知器或transformer架构隐式建模3D-2D投影,不需要相机参数,最近受特斯拉发布感知系统技术路线图的启发,3D-2D几何投影与神经网络的结合开始流行起来,transformer架构中的交叉注意机制在概念上满足了这种几何投影的需要,如下所示:
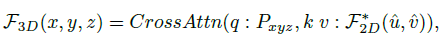
其中,其中q、k、v分别代表查询、键和值,P是体素空间中预定义的锚点,该公式含义是 query为3D空间预定义的anchor点,借助cross attention机制从2D特征value获取值
一些方法利用相机参数将3D空间点P投影到图像平面为了模型快速收敛;BEVFormer利用transformer中的交叉注意机制来增强3D-2D视图转换的建模,从而获得鲁棒的检测结果;其他利用grid sampler有效加速这一过程以实现大规模生产.然而,
3.1.3.3 BEV和透视方法的讨论
在仅基于相机三维感知的初期,主要关注的是如何从透视图(即二维空间)中预测三维物体的定位;正是因为在这一阶段,2D感知能力已经发展得很好,如何在3D感知中使用2D检测器成为主流方法;
后来又有一些研究到了BEV表示,因为在这种视图下很容易解决三维空间中相同大小的物体由于与摄像机的距离而在像平面上大小相差很大的问题,这一系列的工作要么预测深度信息,要么利用3D先验假设来补偿相机输入中3D信息的损失;
虽然最近基于bev的方法已经席卷了3D感知领域,但值得注意的是这种成功主要得益于三个方面:第一个原因是Nusences数据集,它具有多摄像头设置,非常适合在BEV下应用多视图特征聚合;第二个原因是大多数纯相机的BEV感知方法在检测头和相应的损失设计上都得到了基于lidar的方法的很大帮助;第三个原因是单目方法的长期发展使基于bev的方法蓬勃发展,这是在透视视图中处理特征表示形式的良好起点,
3.2 BEV LiDAR
3.2.1 General Pipeline
如下图是BEV激光雷达感知的普通流程。主要有两个分支将点云数据转换为BEV表示,分别是pre-BEV和post-BEV,区别是输入到backbone网络是3D表征还是BEV表征:上分支3D点云输入到backbone;下分支输入BEV特征输入到backbone
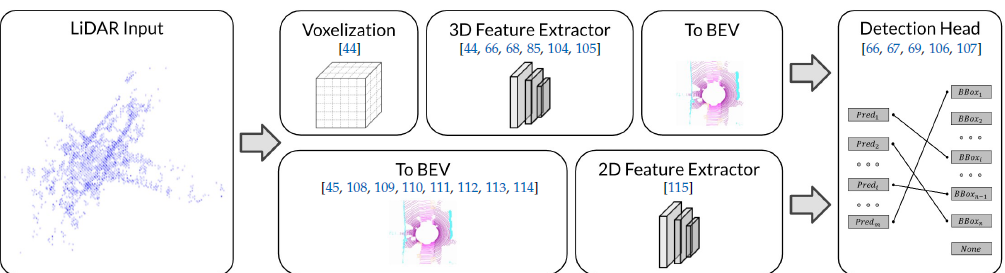
3.2.2 Pre-BEV Feature Extraction
除了在原始点云上进行处理的基于点的方法能外,基于体素的方法还将点云中点体素化为离散网格,通过离散化连续的3D坐标提供更高效的表示,基于离散体素表示,3D卷积或3D稀疏卷积可用于提取点云特征
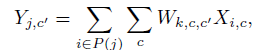
通用的3D卷积操作如上图,Y表示在通道c第j个体素输出,X表示在通道c第i个体素输入;P用于获得输入索引i和滤波器偏移的函数;W为偏移量k的filter的kernel weight;为稀疏化输入输出,公式可以简化如下: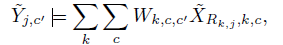
其中R表示在给定内核偏移k和输出索引j的情况下指定输入索引i的矩阵。
大多数最先进的方法通常利用3D稀疏卷积进行特征提取,然后通过加密和压缩高度轴,可以将3D体素特征格式化为BEV中的2D张量
VoxelNet堆叠多个体素特征编码(VFE)层,通过一个FCN网络,将体素中的点云分布编码为体素特征,FCN是线性层、BN和激活函数的组成,体素的特征是体素点特征逐个元素最大池化,3D卷积用于进一步聚合局部体素特征,在合并通道和高度的维度后,特征图隐式转换为BEV后,通过区域建议网络(RPN)处理,生成目标提议
SECOND在处理体素表示时引入稀疏卷积以大幅降低训练和推理速度。
CenterPoint是一种功能强大的基于中心无锚3D检测器,也遵循这种模式,成为3D目标检测的基线方法。PV-RCNN结合点分支和体素分支,学习更具区分性的点云特征,具体来说高质量的3D方案是由体素分支生成的,而点分支为方案优化提供了额外的信息。
SA-SSD设计了一个辅助网络,将主干网络中的体素特征转换到点级的表示,明确利用3D点云的结构信息,并减少下采样的损失。
Voxel R-CNN采用3D卷积主干提取点云特征,然后在BEV上应用2D网络提供目标提议,通过提取的特征可进行细化。其性能与基于点的方法相当。Object DGCNN将3D目标检测任务建模为BEV中动态图的消息传递。将点云转换为BEV特征图后,预测的查询点从关键点迭代收集BEV特征。
VoTr引入“局部注意(Local Attention)”、“扩展注意(Dilated Attention)”和“快速体素查询(Fast Voxel Query)”,在大量体素采用注意机制,可获得大量上下文信息。
SST将提取的体素特征作为token,然后在非重叠区域应用稀疏区域注意(Sparse Regional Attention)和区域偏移(Region Shift),以避免对基于体素的网络进行下采样。
AFDetV2通过引入关键点辅助监督和多任务头,制定了一个单级无锚网络。
3.2.3 Post-BEV Feature Extraction
由于三维空间中的体素稀疏且不规则,应用三维卷积是低效的。对于工业应用,可能不支持3D卷积等运算符;需要合适且高效的3D检测网络。
MV3D是将点云数据转换为BEV表示的第一种方法,在点离散化为BEV网格后,根据网格中点获得高度、强度和密度特征用于表示网格特征;
由于BEV网格有许多点,因此在这一处理过程中,信息损失相当大。
不少方法遵循类似模式,用BEV网格中的统计数据表示点云,例如最大高度和强度平均值。
PointPillars首先介绍了Pillar的概念,这是一种特殊类型的无限高度体素。它使用简化版本的PointNet来学习Pillar的点表示,然后编码特征可以由标准2D卷积网络和检测头处理,虽然PointPilllars的性能不如其他3D主干,但它及其变型效率高,因此适合工业应用。
3.2.4 Discussion
可以看到,
BEV前的特征提取技术SOTA方法 利用细粒度的体素,保留点云数据中的大部分3D信息,因此有利于3D检测。作为一种trade-off,它需要高内存消耗和计算成本。
3.3 BEV Fusion
3.3.1 General Pipeline
逆透视映射(IPM),利用摄像机内外矩阵的几何约束将像素映射到BEV平面。尽管由于平地假设不准确,但提供了在BEV中统一图像和点云的可能性。
Lift -Splat-Shot(LSS)是第一种预测图像特征深度分布的方法,引入神经网络来学习病态的摄像头到激光雷达转换问题。其他工作开发了不同的方法来进行视图转换
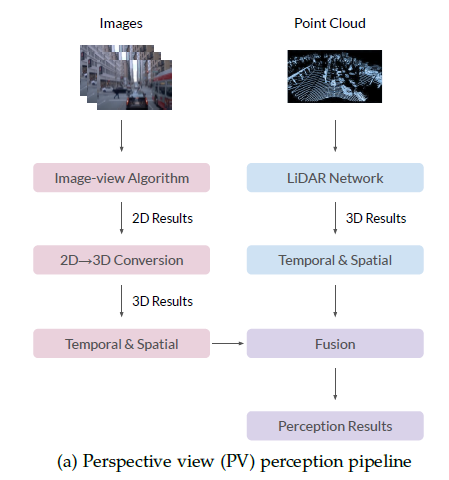
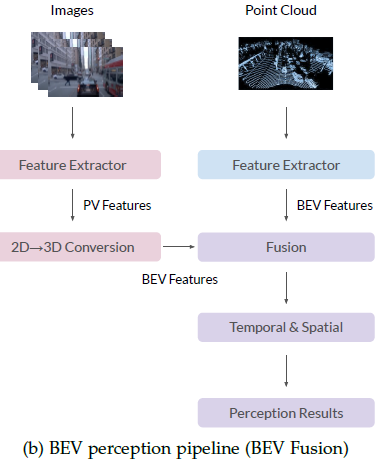
BEV融合算法的两种典型pipeline设计,适用于学术界和工业界。主要区别在于2D到3D转换和融合模块。在PV(透视视图)感知pipeline(图a)中,不同算法的结果首先转换为3D空间,然后使用先验或手工规则进行融合。BEV感知流水线(图b)首先将PV特征转换为BEV,然后融合特征获得最终预测,从而保持大多数原始信息,避免手工设计。
3.3.2 LiDAR-camera Fusion
有两个同名的BEVFusion模型从不同的方向探索BEV的融合;由于
两个BEVFusion之外,UVTR对不同的输入模态的特定体素空间中,没有进行高度压缩,避免语义歧义并支持进一步的交互。每个视图的图像特征转换为预先定义的带有深度分布的空间,这样可以构建图像体素空间。点体素空间使用普通三维卷积网络构建。然后在两个体素空间之间进行跨模态交互,以增强模态特定信息。
3.3.3 Temporal Fusion
时间信息在推断目标运动状态和识别遮挡物方面起着重要作用。BEV为连接不同时间戳中的场景表示提供了一个理想的桥梁,因为BEV特征图的中心位置对自车来说是持续的。
MVFuseNet利用BEV和距离视图进行时间特征提取。其他方法用自运动将之前的BEV特征与当前坐标对齐,然后融合当前BEV特征以获得时间特征。
BEVDet4D采用空间对齐操作然后连接多个特征图,将先前的特征图与当前帧融合。
BEVFormer和UniFormer采用软方式融合时间信息。
注意模块用于融合分别来自先前BEV特征图和先前帧的时间信息。关于自车运动,在不同时间戳的表征中,注意模块参与的位置也会被自运动信息所修正
3.3.4 Discussion
由于图像在透视坐标,点云在3D坐标,两种模态之间的空间对齐成为一个重要问题。尽管使用几何投影关系很容易将点云数据投影到图像坐标上,但点云数据的稀疏特性使得提取信息特征变得困难。相反,由于透视图中缺乏深度信息,将透视图中的图像转换为3D空间将是一个不适定问题。基于先验知识,先前的工作,如IPM和LSS使透视图中的信息转换为BEV成为可能,为多传感器融合和时域融合提供了统一的表示。
激光雷达和摄像机数据在BEV空间的融合为3D检测任务提供了令人满意的性能。这种方法还保持了不同模态的独立性,这为构建更强大的感知系统提供了机会。对于时域融合,通过考虑自运动信息,可以在BEV空间中直接融合不同时间戳的表示。由于BEV坐标与3D坐标一致,通过监控控制和运动信息很容易获得自运动补偿。考虑到鲁棒性和一致性,BEV是多传感器和时域融合的理想表征。
3.4 BEV感知工业设计架构
在BEV感知研究之前,大多数自动驾驶公司基于视角输入构建感知系统。如上图a所示,透视图(PV)pipeline,LiDAR分支直接生成3D结果,图像分支的3D结果是基于几何结构先验从2D结果转换而来。然后利用手动设计方法 融合图片和LiDAR结果,这手动设计方法在一些现实场景表现的不好。上图b方法,用神经网络做2D-3D转换,然后融合的是BEV的特征,而不是结果,没有手工设计部分,鲁棒性更强
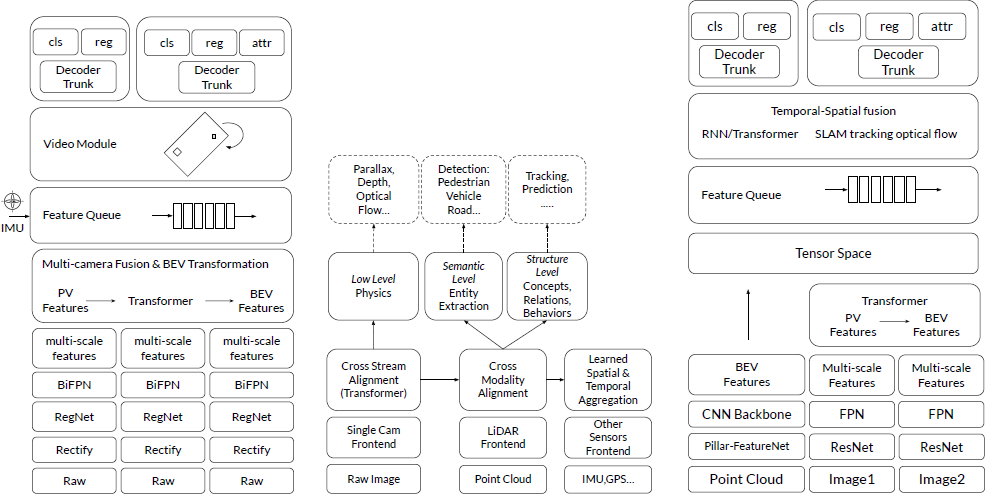
如图总结工业界各种BEV感知的架构:特斯拉、地平线和毫末,上图流程范式和3.3.1 图b类似,首先,它们用backbone对输入数据进行编码,并通过transformer进行BEV投影;然后,在时域和空域融合BEV特征。最后,他们用不同的头解码BEV特征。每种设计都略有不同。特斯拉将摄像机图像和IMU作为输入,而Horizon和HAOMO将点云作为输入。主干在不同的体系结构中有所不同;下面按照输入数据,特征提取,PV/BEV转换,特征融合,时空模块,预测头 分别讲述
3.4.1 输入数据
基于BEV的感知算法支持不同的数据模式,包括相机、激光雷达、雷达、IMU和GPS。摄像机和激光雷达是自动驾驶的主要感知传感器。一些产品仅使用摄像机作为输入传感器,例如特斯拉、鉴智机器人、Mobileye。其他采用一套相机和激光雷达组合,例如地平线,毫末。请注意,IMU和GPS信号通常用于传感器融合,特斯拉和地平线等的情况也是如此
3.4.2 特征提取/Feature Extractor
特征提取器用于将原始数据转换为适当的特征表示,该模块通常由主干和颈网组成。特征提取器作为主干和颈网有不同的组合。例如,毫末的ResNet和Tesla的RegNet可以用作图像主干。颈网可以是毫末的FPN、Tesla的BiFPN等。至于点云输入,毫末的基于pillar的选项,或Mobileye的基于体素的选项,是主干的理想选择
3.4.3 PV/BEV转换/PV to BEV Transformation
在行业中执行视图转换主要有四种方法:
- (a)固定IPM:基于平坦地面假设,固定变换可以将PV特征投影到BEV空间;固定IPM投影也处理地平面;然而,对车辆颠簸和路面平整度比较敏感。
- (b)自适应IPM:利用一些姿态估计方法获得自动驾驶车的外部参数,并相应地将特征投影到BEV;尽管自适应IPM对车辆姿态具有鲁棒性,但仍然假设地面平坦。
- (c)基于Transformer的BEV变换采用密集Transformer将PV特征投影到BEV空间。这种数据驱动的转换在没有事先假设的情况下运行良好,因此被特斯拉、地平线和毫末广泛采用。
- (d)ViDAR于2018年初由Waymo和Mobileye在不同地点并行提出,表明基于摄像头或视觉输入用像素级深度将PV特征投影到BEV空间的实践,类似于激光雷达中的表示形式。术语ViDAR相当于大多数学术文献中提出的伪激光雷达概念。配备ViDAR,可以将图像和后续特征直接转换为点云。然后,可以应用基于点云的方法来获得BEV特征。最近看到了许多ViDAR应用,例如特斯拉、Mobileye、Waymo和丰田等。总体而言,Transformer和ViDAR的选择在行业中最为普遍。
3.4.4 特征融合/Fusion Module
在先前的BEV变换模块中已经完成了不同相机源之间的对准。
在融合单元中,他们进一步聚合来自相机和激光雷达的BEV特征。通过这样做,来自不同模式的特征最终被集成到一个统一的形式中。
3.4.5 时空模块/Temporal & Spatial Module
在时间和空间堆叠BEV特征,可以构建特征队列。时间堆栈每固定时间推送和弹出一个特征点,而空间堆栈每固定距离推送一个。将这些堆栈中的特征融合为一种形式,可以获得对遮挡具有鲁棒性的时空BEV特征。聚合模块可以是3D卷积、RNN或Transformer的形式。基于时域模块和车辆运动学,可以维护围绕自车的大型BEV特征图,并局部更新特征图,就像特斯拉的spatial-RNN模块那样。
3.4.6 Prediction Head
在BEV感知中,多头设计被广泛采用。由于BEV特征聚集了来自所有传感器的信息,所有3D检测结果都从BEV特征空间进行解码。同时,PV结果(对自动驾驶仍有价值)也从某些设计中对应的PV特征进行解码。预测结果可分为三类:(a)低级结果与物理约束有关,如光流、深度等。(b)实体级结果包括目标概念,即车辆检测、车道线检测等。(c)结构级结果表示目标之间的关系,包括目标跟踪、运动预测等
4、技巧和实践
4.1 Data Augmentation
4.1.1 BEV Camera (Camera-only) Detection
用于2D识别任务的图像通用数据增强适用于基于摄像头的BEV感知任务。一般来说,可以将增强分为静态增强和空间变换,静态增强仅涉及颜色变化。对于涉及空间变换的增强,除了相应变换的真值外,还需要校准摄像头参数。采用的常见增强是颜色抖动、翻转、多尺度调整大小、旋转、裁剪和网格掩码。
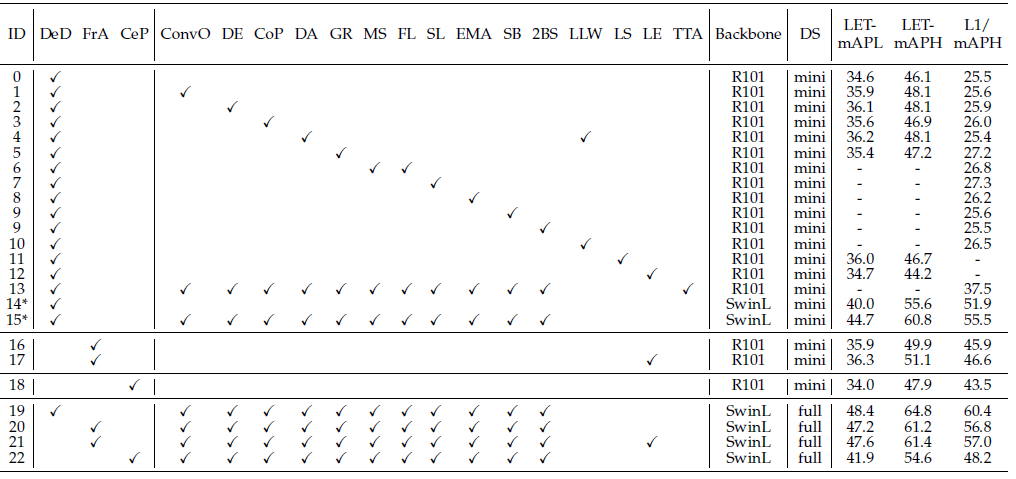
在商汤和上海AI提出的BEVFormer++中,采用了颜色抖动、翻转、多尺度调整大小和网格掩码。输入图像按0.5和1.2之间的因子缩放,以0.5的比率翻转;总面积最大30%被正方形掩码随机遮挡。值得注意的是,在BEV感知中有两种翻转图像的方法。第一种方法是简单相应地翻转图像、真值和摄像头参数。第二种方法还翻转图像顺序,以保持图像之间重叠区域的一致性,这类似于对称翻转整个3D空间。BEVFormer++采用了第二种翻转方式。如表5所示实验中描述了相关消融研究。由于BEVFormer采用序列输入,确保了输入增强后序列的每帧变换是一致的。
4.1.2 LiDAR Segmentaion
激光雷达数据的分割方面,与检测任务不同,数据增强可以应用随机旋转、缩放、翻转和点平移。对于随机旋转,从[0,2π]范围中选取一个角度,旋转应用于x-y平面上的每个点。从[0.9,1.1]范围中选择比例因子,然后乘以点云坐标。沿X轴、Y轴或X轴和Y轴进行随机翻转。对于随机平移,每个轴的偏移分别从均值0、标准方差0.1的正态分布中采样。
除了坐标和反射率,还可以利用额外的信息来提高模型性能。Painting技术用图像信息增强点云数据。对于未标记的图像数据,将点云标签投影到相应的图像上并致密化稀疏标注,从标注的点云数据中获得图像的语义标签。训练图像模型提供2D语义分割结果。然后,将预测的语义标签绘制为点云数据的 one-hot矢量,作为表示图像语义信息的附加通道。此外,还可以使用时域信息,因为自动驾驶中的数据集通常是序贯收集的。过去的连续帧与当前帧连接在一起。附加信道可表示不同帧的相对时间信息。为了减少点的数量,应用小的体素化网络。然后,被视为点的体素作为模型输入。表6如下给出一些消融实验分析。
4.2 BEV Encoder
BEVFormer++有多个编码器层,除了三种定制设计,即BEV查询、空域交叉注意和时域自注意机制之外,每个编码器层都遵循transformer的传统结构。具体而言,BEV查询是网格形状的可学习参数,旨在通过注意机制从多摄像机视图中查询BEV空间的特征。空域交叉注意和时域自注意是与BEV查询一起工作的注意层,用于:1)根据BEV查询查找;2)聚合来自多摄像机图像的空域特征以及来自历史BEV的时域特征。
在推理期间,在时间t将多摄像机图像馈送到主干网络(例如,ResNet-101),并获得不同摄像机视图的特征Ft,保留时间t-1的BEV特征Bt−1,是通过时域自注意。在每个编码器层中,首先用BEV查询Q来查找来自先前BEV特征Bt-1的时间信息。然后,用BEV查询Q从多摄像机特征Ft查询空域信息,则通过空域交叉注意。在前馈网络之后,编码器层生成细化的BEV特征,这是下一编码器层的输入。在六个堆叠的编码器层之后,生成当前时间戳t的统一BEV特征Bt。将BEV特征Bt作为输入,3D检测头和地图分割头预测感知结果,如3D边框和语义地图。
为了提高BEV编码器的特征质量,以下讨论三个主要方面:
(a) 2D特征提取器。改善2D感知任务的主干表征质量,也最有可能改善BEV任务的表征质量。为了方便起见,在图像主干中,采用了在大多数2D感知任务中广泛使用的特征金字塔。2D特征提取器的结构设计,如最先进的图像特征提取器、全局信息交互、多级特征融合等,都有助于更好地表示BEV感知的特征。除了结构设计外,辅助任务监督主干对BEV感知性能也很重要,后面会讨论。
(b) 视图转换。该变换采用图像特征并将其重新组织到BEV空间中。超参数,包括图像特征的采样范围和频率,以及BEV分辨率,对于BEV感知性能至关重要。采样范围决定图像后面的观察截锥(viewing frustum)多少将被采样到BEV空间。默认情况下,该范围等于激光雷达标注的有效范围。当效率具有更高优先级时,观察截锥的上z轴部分可能会受到影响,因为在大多数情况下,它只包含不重要的信息,如天空。采样频率决定了图像特征的效用。更高的频率确保模型以更高的计算成本精确地采样每个BEV位置对应的图像特征。BEV分辨率决定了BEV特征的表示粒度,其中每个特征可以精确地追溯到世界坐标中的网格。需要高分辨率来更好地表示小尺度目标,如交通灯和行人。在视图变换中,特征提取操作,例如卷积块或变换块,也存在于许多BEV感知网络中。在BEV空间中添加更好的特征提取子网络也可以提高BEV感知性能。
(c) 时域BEV融合。给定BEV特征的结构,BEV空间的时域融合通常利用自车姿态信息来对齐时域BEV特征。然而,在这个对齐过程中,其他智体的移动没有明确建模,因此需要模型进行额外学习。因此,为了增强对其他移动智体特征的融合,在执行时域融合时,增加交叉注意的感知范围是合理的。例如,可以扩大可变形注意模块中注意偏移的核大小,或者使用全局注意。
由于粗略的体素化和激进的下采样,现有的3D感知模型不适合识别小实例。SPVCNN在基于体素的分支中使用了Minkowski U-Net。为了保持点云分辨率,用了一个额外的基于点分支,没有使用下采样。基于点分支和基于体素分支的特征将在网络的不同阶段相互传播。
通过对原始SPVCNN进行两次有效修改,作者提出了Voxel-SPVCNN。与简单地对原始输入特征执行体素化相比,这里采用了一个轻量三层MLP提取点特征,然后应用体素化过程。此外,基于点分支的输入被代替为体素-作-点分支(voxel-as-point branch)。该分支的网络结构仍然是MLP;但输入被替换为体素。Voxel-SPVCNN效率更高,因为基于点分支的计算大大减少,特别是输入是多扫描点云的情况下。
4.3 3D Detection Head in BEVFormer++
对BEV摄像机的检测任务,在BEVFormer++中采用了三个检测头。相应地,这些头涵盖三类检测器设计,包括无锚框、基于锚框和基于中心的方法。选择各种类型的检测器头,尽可能在设计上有所区别,以便充分利用检测框架在不同场景中的潜能力。头部的多样性有助于最终的集成结果。
原始的BEVFormer,用一个改进的可变形DETR解码器作为其3D检测器,可以在没有NMS的情况下端到端检测3D边框。对于该头,遵循原始设计,但使用平滑L1-损失替换原始L1-损失函数。
BEVFormer++采用FreeAnchor和CenterPoint作为替代3D检测器,其中FreeAnchor是基于锚框的检测器,可以自动学习锚框匹配,而CenterPoint是基于中心的无锚框3D检测器。预测头在推理期间提供了各种分布。值得注意的是,3D解码器远未得到很好的开发,因为高效查询设计在2D感知方面发展很成功,而如何将这些成功转移到3D感知领域将是下一步要做的
4.4 测试-时间增强/Test-time Augmentation (TTA)
4.4.1 BEV Camera-only Detection
2D任务常见的测试时间增强(TTA),包括多尺度和翻转测试,可提高3D情况下的准确性。在BEVFormer++中,这一部分用标准数据增强(如多尺度和翻转)形式进行简单探索。多尺度增强的程度与训练时间相同,从0.75到1.25不等。
4.4.2 LiDAR Segmentation
在推理过程中,使用了多个TTA,包括旋转、缩放和翻转。对于缩放,所有模型的缩放因子均设置为{0.90,0.95,1.00,1.05,1.10},因为缩放因子较大或较小对模型性能有害。翻转与训练阶段相同,即沿X轴、Y轴以及同时X轴和Y轴。旋转角度设置为{−π/2 , 0, π/2 , π}. 可以选择更细粒度的缩放因子或旋转角度,但考虑到计算开销和TTA组合策略,更倾向于粗粒度参数。
与细粒度增强参数相比,TTA的组合将进一步提高模型性能。然而,由于TTA倍增,组合还是非常耗时的。组合的模型相关TTA,有20倍推理时间。组合策略的网格搜索,可以进行。根据经验,缩放和翻转的组合更为可取
4.5 Loss
4.5.1 BEV Camera-only Detection
BEV特征表征的一个多样性好处是,可以用2D和3D目标检测中提出的损失来训练模型。相应的损失可以通过最小化修改进行迁移,例如调整损失权重。
除了3D目标的训练损失外,辅助损失在仅摄像机BEV检测中也起着重要作用。一种类型的辅助损失是在2D特征提取器之上添加2D检测损失。这种监督增强了2D图像特征的定位,进而有助于BEV感知中视图变换提供的3D表示。
另一种类型的辅助损失是深度监督。当利用激光雷达系统生成的真值深度时,可以提高BEV感知的隐式深度估计能力,获得精确的3D目标定位。这两个辅助任务都可以在训练期间应用,提高性能。作为旁注,通常2D检测或深度预训练主干,选为初始化权重
4.5.2 LiDAR segmentation
代替传统的交叉熵损失,Geo损失和Lovász损失用于训练所有模型。为了获得更好的不同类边界,Geo损失对有丰富细节的体素具有强烈的响应。Lovász损失作为可微分IoU损失,能缓解类不平衡问题。
4.6 Ensemble
4.6.1 BEV Camera-only Detection
仅摄像机BEV检测而言,集成技术通常在要测试的数据集之间变化;2D/3D目标检测中使用的通用实践可应用于BEV感知,但需进行一些修改。以BEVFormer++为例,在集成阶段采用weighted box fusion(WBF)的改进版本。受Adj NMS的启发,在原始WBF之后采用矩阵NMS来过滤冗余框。为了生成多尺度和翻转结果,采用了两阶段集成策略。在第一阶段,用改进的WBF来整合来自多尺度流水线的预测,生成每个模型的翻转和非翻转结果。如下表7列出了专家模型性能的相关实验。在第二阶段,收集所有专家模型的结果。用改进的WBF来获得最终结果
考虑到每个模型的性能差异,参数调整被认为更为复杂。因此,采用进化算法搜索WBF参数和模型权重。利用NNI中的进化思路来自动搜索参数,其中演化群体总数为100。搜索过程基于3000张验证图像的性能;不同的类分别搜索,如表8所示。
4.6.2 LiDAR Segmentation
对激光雷达分割而言,作为点分类任务,分割以平均方式从不同模型中集成每点概率。具体而言,简单地将不同模型预测的概率相加,然后使用argmax操作确定每个点的分类结果。为了提高模型的多样性,用不同的数据重采样策略(称为export模型)来训练模型。根据场景和天气条件的上下文信息,在基于所有数据训练的模型上,微调多个上下文特定模型。
模型的概率在特定于模型的TTA之后以分层方式聚合。考虑到模型的多样性,模型集成分两个阶段处理。在第一阶段,同类模型的概率,例如具有不同超参数的模型,以不同的权重进行平均。然后,在第二阶段,非同类模型(即具有不同架构的模型)的概率,以不同的权重进行平均。在NNI中具有最大试验数160的退火算法,用于同时两个阶段搜索验证集的权重
4.7 后处理/Post-Processing
4.7.1 BEV Camera-only Detection
还是先说仅摄像机BEV检测。虽然BEV检测消除了多摄像机目标级融合的负担,但观察到从进一步后处理中获益的显著事实。根据BEV变换的性质,重复特征可能沿着光线到摄像头中心在不同的BEV位置进行采样。这将导致对一个前景目标进行重复假检测,其中每个假检测具有不同的深度,但都可以投影回图像空间中的相同前景目标。
为了缓解这个问题,利用2D检测结果对3D检测结果进行重复移除是有益的,其中2D边框和3D边框是二分匹配(bipartite match)。在实验中,用真实2D边框作为过滤器可以提高3D检测性能。然而,当辅助监督训练的2D检测头去预测2D边框时,发现几乎无法取得改进。这可能是由于2D检测训练不足造成的。因此,需要进一步研究联合2D/3D冗余检测的去除。
检测头设计是否体现出无NMS的特性,可以以此决定应用NMS。通常,对于一对多的分配,NMS是需要的。值得注意的是,将NMS中常用的IoU度量替换为新提出的LET IoU,以去除冗余结果,这个可以改善检测结果。这种设计更适用于仅用摄像机BEV的3D检测器。由于两个相互冗余结果的3D IoU在数值上很小,这通常导致无法消除FP结果。使用LET IoU,冗余结果往往会困扰更高的IoU,从而在很大程度上被删除。
4.7.2 LiDAR Segmentation
分析混淆矩阵(confusion matrix),发现大多数错误分类发生在相似类中。因此,语义类可以分为组,其中的类与组外的类相比非常混乱。
现有的分割方法执行逐点分类,而不考虑单个目标的一致性。例如,一些标记为前景目标的点,被错误预测为背景。基于上述分级分类,进行目标级细化可进一步提高目标级完整性。基于预测掩码同一语义组中的点,并执行欧几里德聚类,可以将点分组为实例。然后通过大多数表决(majority voting)确定每个实例的预测。此外,对于每个目标,由轻量级分类网络执行目标级分类的合理性,确定目标的最终预测类。
当获得目标级预测时,跟踪可进一步细化预测的时间一致性。执行跟踪,从所有先前帧中找到对应目标。通过考虑所有前预测,对当前帧中目标的预测类进行细化
5 CONLUSION
该文对近年来人们对BEV的认知进行了全面的回顾,并根据自身在BEV设计流水线中的分析,提供了一个实用的对策。巨大的挑战和未来的努力可能是:
(a)如何设计更精确的深度估计器;
(b) 如何在新的融合机制中更好地对齐来自多个传感器的特征表示;
(c) 如何设计一个无参网络,使算法性能不受姿态变化或传感器位置的影响,在各种场景中实现更好的泛化能力;
(d)如何结合基础模型中的成功知识来促进BEV感知
6 三维视觉经典投影变换
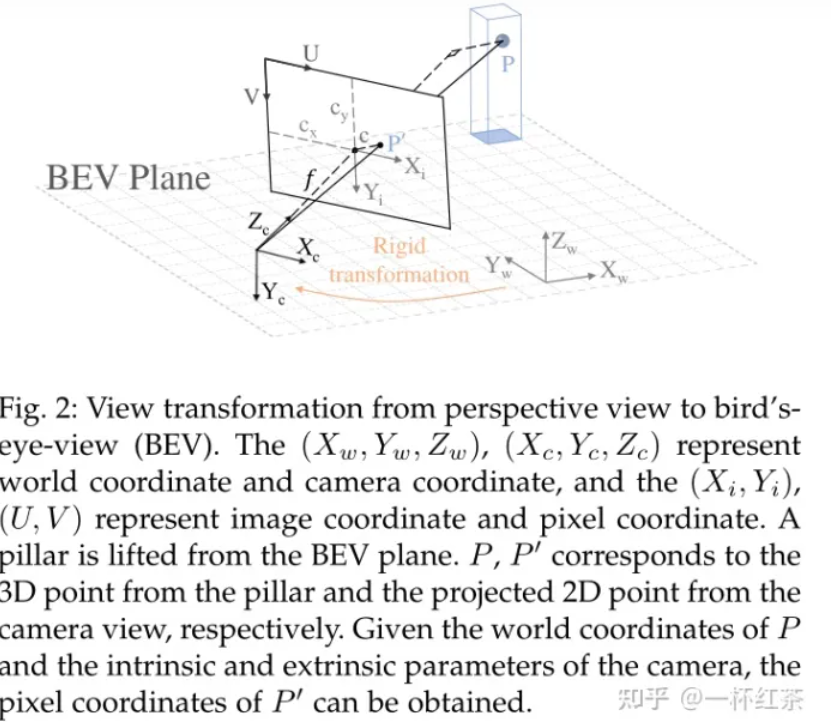
从世界坐标到相机坐标的转换是一种刚性转换,只需要平移和旋转,设 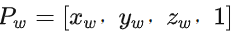
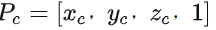 为三维点P在世界坐标系下和相机坐标系下的齐次表示,他们之间的转换为:
为三维点P在世界坐标系下和相机坐标系下的齐次表示,他们之间的转换为:
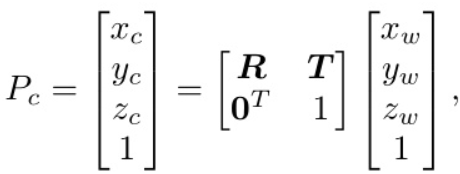
引入图像坐标系来描述相机坐标系对图像的透视投影,在不考虑相机畸变的情况下,三维点与其在像面上的投影关系可以简化为针孔模型。图像坐标(xi, yi)计算为:
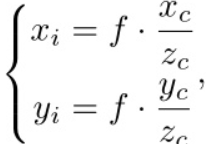
图像坐标系与像素坐标系之间存在平移和缩放变换关系,设α和β表示横坐标和纵坐标的比例因子,cx、cy表示坐标原点的平移值,像素坐标(u, v)用数学表示为:
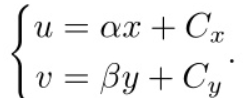
联立等式5、6,得
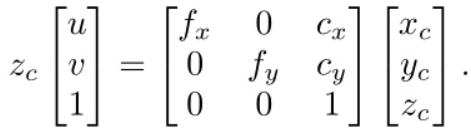
综上,三维点P在世界坐标系中与其在像素坐标系中的投影p0之间的关系可以描述为:
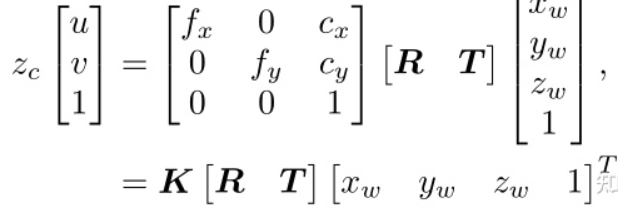

 浙公网安备 33010602011771号
浙公网安备 33010602011771号