(开集检测系列)MDETR - Modulated Detection for End-to-End Multi-Modal Understanding
caption数据+DETR做开集检测
1、动机
- 1、只在固定object和属性上训练,解决不了长尾的问题/开集
2、方法
2.1 优势
- 1、MDETR仅依赖于文本和对齐的框作为图像中概念形式进行监督;不像目标检测,这个文本概念是free-form,因此可以泛化到unseen 目标或者属性
2.2 架构图

流程图步骤:
- 1.image 通过conv网络提取特征,拉直并加上2-D的位置编码,产生image embedding
- 2.text经过预训练的语言模型产生text embedding
- 3.image embedding和text embedding分别经过线性投影层到相同特征空间
- 4.image embedding和text embedding进行concat,然后输入到transformer encoder,这里叫做cross encoder
- 5.然后接和DETR一样的transformer decoder,其中queries为text中个形容词+名词内容,然后根据名词+内容和box作为gt,来学习优化预测框(上图右边部分)
2.3 loss
Loss主要包括box预测loss(L1+GIoU)+soft-token prediction loss+contrastive alignment loss
其中box预测loss和DETR一致
2.3.1 soft-token prediction loss
该loss替代分类loss,可以理解为让text先后顺序编码为token,然后queries中先后输入名词+形容词,然后是queries输出对应的特征和text token中对应位置的weight最大
+1.text先后顺序编码为token,设置text的token最大长度为L=256
+2.queries输入text中的名词+形容词,各queries对应的输出的特征和text token中对应位置的weight最大
2.3.2 Contrastive alignment
网络decoder输出的object的embedding和cross encoder输出对应的文本的那个object的text embedding(这里的object的text emebedding和其他文本和图像做了cross attention)对齐(对比学习,和对应上的object文本特征拉近,不对应的文本特征远离)
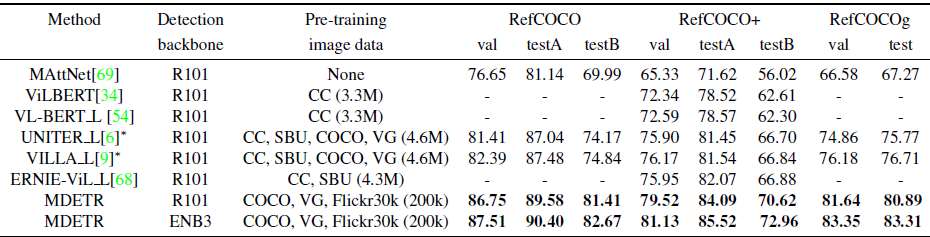
3.效果
4.消融实验
无

 浙公网安备 33010602011771号
浙公网安备 33010602011771号