(开集检测系列)Learning to Prompt for Open-Vocabulary Object Detection with Vision-Language Model
ViLD基础上引入prompt
1、动机
1、ViLD使用的text embedding的方式是使用prompt template(a photo of categoryg in the scene)和同义词,然后输入clip text encoder 生成 text embedding,使用prompt应该能提升ViLD的性能
2、CLIP预训练的image是以目标为中心背景不多的整图和检测的proposal可能包含背景的域不一样,所以引入prompt
2、方法
检测引入Prompt,由于提取的Proposal存在背景proposal,前景proposal框不准的话存在不同程度的背景上下文,因此需处理2个问题,一个是背景proposal没有具体类别名称,一个是前景proposal可能包含不同程度的背景图
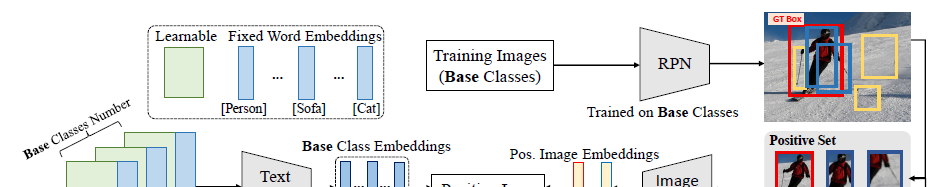
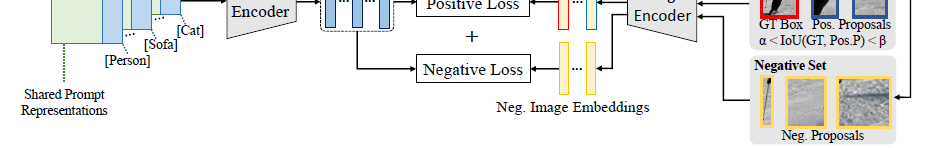
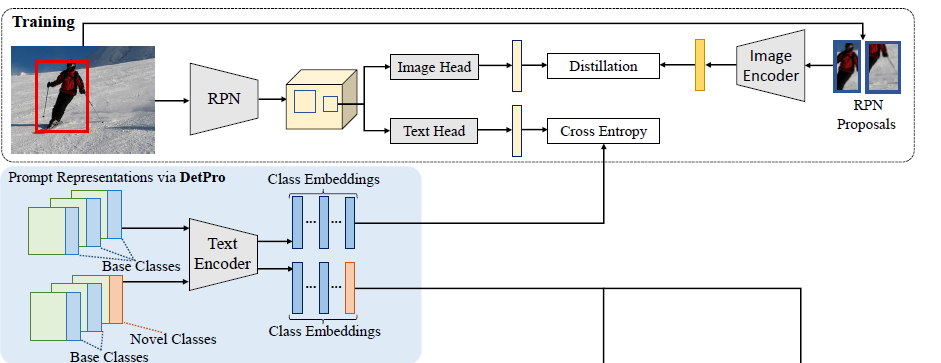

引入background interpretation scheme和context grading scheme分别解决以上2个问题
2.1 background interpretation scheme
使用背景解释方法,使背景类和前景所有类都不相似来解决
loss计算如下
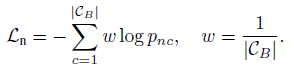
其中pnc为计算如下
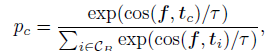
2.2 context grading scheme
上下文打分方法,根绝proposal和GT的IOU分成不同的阶段,按照不同类不同阶段学习不同的prompt,然后取均值作为最终的prompt
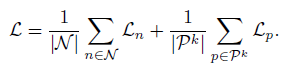
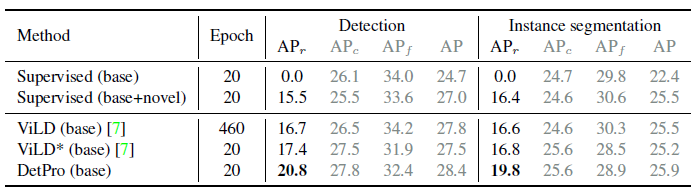
3、效果
LVIS效果如下,其中ViLD和ViLD的backbone不同,本文使用预训练SoCo的模型,从ViLD到DetPro是有提升的,但是从ViLD没有结果
4、消融实验
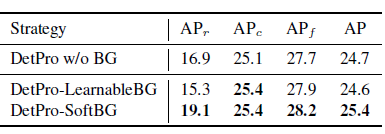
4.1、背景解释器
除2.1节结束的方法,还可以给背景 proposal单独训练prompt,但是效果不好,原因是单独训练的prompt还是固定的,但是背景类可能类型不同(地,天空,房子等),就是背景类可能包含很多很多类别,不能用一个固定的prompt表达
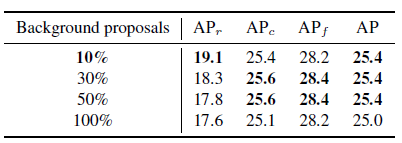
4.2、负proposal个数
负样本要适量
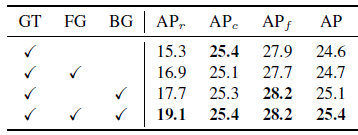
4.3、训练是前景proposal,背景proposal,GT对结果影响
3个都的要
4.4、Context Grading and Prompt Representation Ensemble

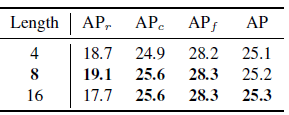
4.5、Context Length
越大对base类越好,但是等于8对novel类最好,原因可能是太大了,参数多了,可能会过拟合
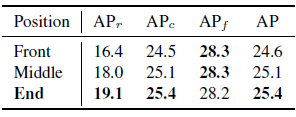
4.6、Position of Class Token
不同数据集的class在prompt中的位置不一样,LVES数据集是在prompt最后

 浙公网安备 33010602011771号
浙公网安备 33010602011771号