(开集检测系列)OPEN-VOCABULARY OBJECT DETECTION VIA VISION AND LANGUAGE KNOWLEDGE DISTILLATION
不引入caption数据,使用coco数据集,使用CLIP 作为teacher模型蒸馏出Mask RCNN模型的检测能力(主要是训练出Mask RCNN能提取出类无关的box和该box的特征能和CLIP text embedding能很好的match),novel类检测能力通过伪novel类的框+推理时CLIP text embedding的进行分类 引入
1、动机
1、数据集方面,过去已有收集数据方法,包含1203类的LVIS和专门收集稀有数据
2、检测方面,image-text数据的在CLIP上成功使用,其中0-shot的能力关键点在预训练的text encoder,CLIP这种图片级别的0-shot,能否迁移到目标检测,也就是本文要研究的方向
2、方法
RCNN做开集检测的2个重要问题 1、类无关的proposal提取 2、开集的图片分类
ViLD主要有text embedding和image embedding组成
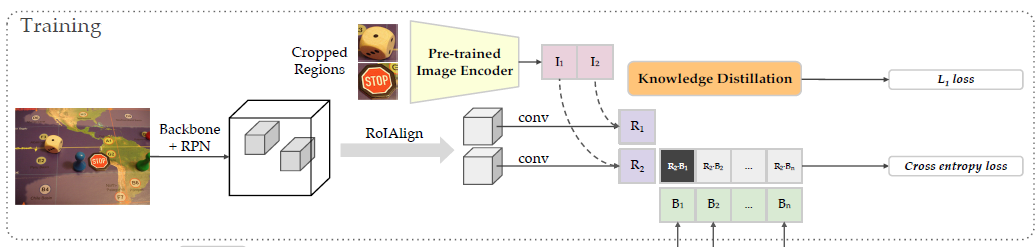
- 步骤1、Mask RCNN在base类别上训练类无关的Proposal模型(loss只计算box回归,不看类别),然后再image上提取base+novel proposal,通过CLIP image encoder生成image region embedding。其中在base上训练的模型在target类别上有一定的召回能力,而这正好用到了ViLD-image的novel类别上,但是每个图100个proposal有多点

- 步骤2、base 类别,使用prompt template(a photo of categoryg in the scene)和同义词,然后输入clip text encoder 生成 text embedding
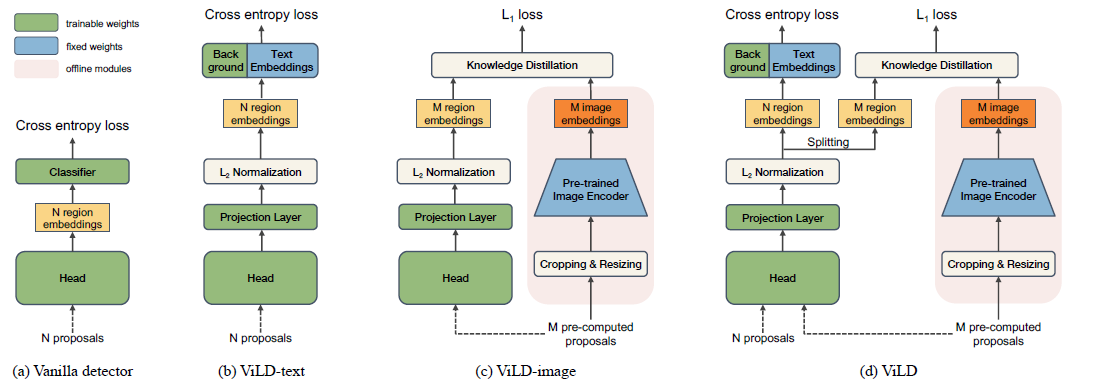
- 步骤3、ViLD-text/分类头换成text embeddings,上图,a为Mask RCNN网络,ViLD-text将分类头换成步骤2text embedding和可学习的“background”的embedding。 中间投射层是为了将reion embedding投射到 text embedding相同的维度
训练过程中,ViLD-text除了base类别,其他类别均被分到background类别,其他类别不能很好的被CLIP中的background单词的embedding表示,所以这里使用参数学习出一个“background”的embedding
训练loss使用region embedding和 text embedding+background embedding cosine similarity的交叉熵
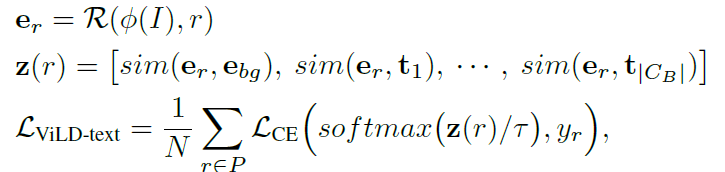
- 步骤4、ViLD-image/image embedding蒸馏, 步骤1生成base+novel的 image embedding,作为teacher指导RCNN产生proposal
训练loss使用L1 loss
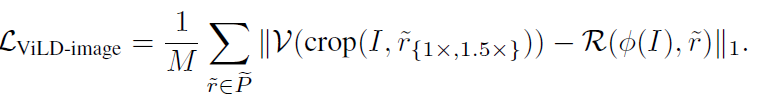
- 步骤5、最终loss
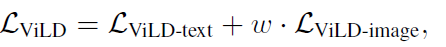
- 其他技巧:
- 1、MODEL ENSEMBLING
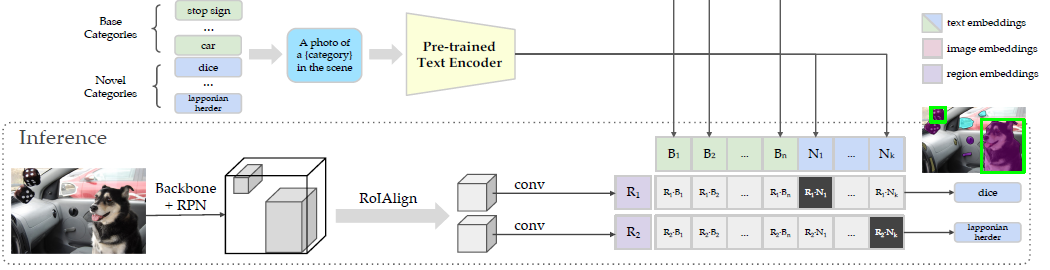
上图推理的流程图会生成proposal和CLIP text embedding对齐的一个score,另外ViLD-text也会生成score。然后使用下面式子进行集成,其中 “那马大”=2/3,因为ViLD-text在base上训练,所以赋予权重更大
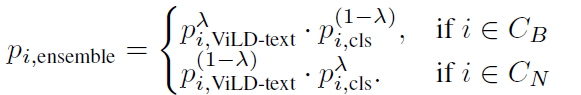
- 1、MODEL ENSEMBLING
3、效果
COCO上和已存在方法比较
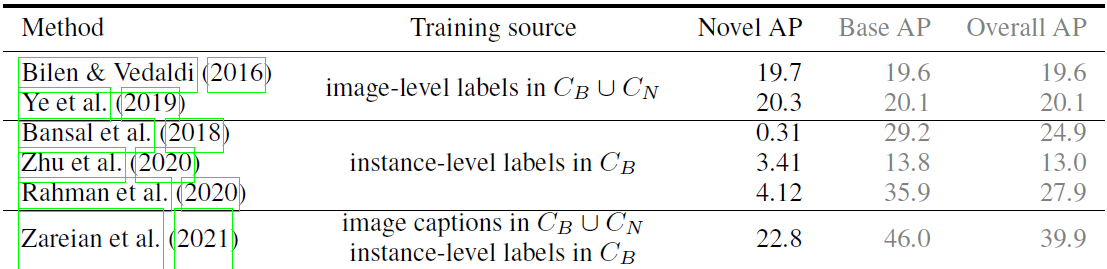

4、消融实验
- 1、crop region上使用CLIP开集分类
在region proposal上使用开集分类(CLIP text encoder)对新类别分类可以检出novel类别,在novel比监督模型好,在所有类别上没有监督模型好;并且region和CLIP得分+proposal object scores可以提点
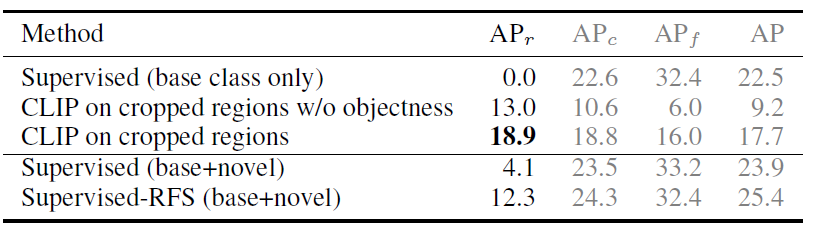
- 2、ViLD-text
ViLD-text使用CLIP比GloVe效果好,得出预训练text+image比纯语义的要好;
VilD-text比CLP on crop region在base效果好,因为训练是在base上对齐的,而novel上不好,说明ViLD-text效果泛化到novel类不如原CLIP


- 3、ViLD-image
ViLD-image 能增加在novel类泛化能力,但是还是没有CLIP on crop效果好,见上图 - 4、Text+visual embeddings (ViLD)
ViLD-image 结合 ViLD-text可以进一步提升novel的AP,但是在base上相对ViLD-text有下降,见上图
5、遗留问题
推理速度慢,因为产生的object proposal要一个一个进行分类?为什么不能同时呢?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号